 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDECORE: Deep Compression with Reinforcement Learning
Paper and Code
Jun 11, 2021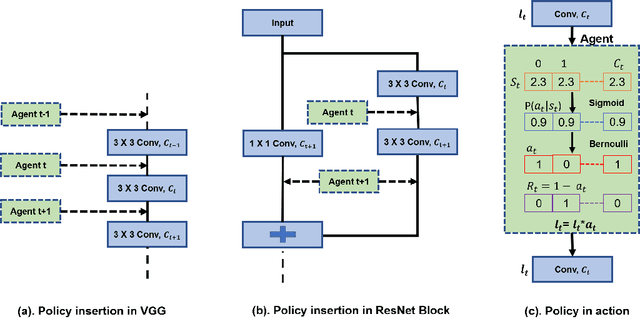


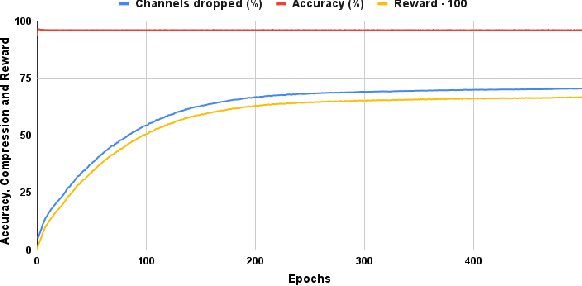
Deep learning has become an increasingly popular and powerful option for modern pattern recognition systems. However, many deep neural networks have millions to billions of parameters, making them untenable for real-world applications with constraints on memory or latency. As a result, powerful network compression techniques are a must for the widespread adoption of deep learning. We present DECORE, a reinforcement learning approach to automate the network compression process. Using a simple policy gradient method to learn which neurons or channels to keep or remove, we are able to achieve compression rates 3x to 5x greater than contemporary approaches. In contrast with other architecture search methods, DECORE is simple and quick to train, requiring only a few hours of training on 1 GPU. When applied to standard network architectures on different datasets, our approach achieves 11x to 103x compression on different architectures while maintaining accuracies similar to those of the original, large networks.