 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVirtually Being: Customizing Camera-Controllable Video Diffusion Models with Multi-View Performance Captures
Oct 16, 2025We introduce a framework that enables both multi-view character consistency and 3D camera control in video diffusion models through a novel customization data pipeline. We train the character consistency component with recorded volumetric capture performances re-rendered with diverse camera trajectories via 4D Gaussian Splatting (4DGS), lighting variability obtained with a video relighting model. We fine-tune state-of-the-art open-source video diffusion models on this data to provide strong multi-view identity preservation, precise camera control, and lighting adaptability. Our framework also supports core capabilities for virtual production, including multi-subject generation using two approaches: joint training and noise blending, the latter enabling efficient composition of independently customized models at inference time; it also achieves scene and real-life video customization as well as control over motion and spatial layout during customization. Extensive experiments show improved video quality, higher personalization accuracy, and enhanced camera control and lighting adaptability, advancing the integration of video generation into virtual production. Our project page is available at: https://eyeline-labs.github.io/Virtually-Being.
FlashDepth: Real-time Streaming Video Depth Estimation at 2K Resolution
Apr 09, 2025A versatile video depth estimation model should (1) be accurate and consistent across frames, (2) produce high-resolution depth maps, and (3) support real-time streaming. We propose FlashDepth, a method that satisfies all three requirements, performing depth estimation on a 2044x1148 streaming video at 24 FPS. We show that, with careful modifications to pretrained single-image depth models, these capabilities are enabled with relatively little data and training. We evaluate our approach across multiple unseen datasets against state-of-the-art depth models, and find that ours outperforms them in terms of boundary sharpness and speed by a significant margin, while maintaining competitive accuracy. We hope our model will enable various applications that require high-resolution depth, such as video editing, and online decision-making, such as robotics.
Lux Post Facto: Learning Portrait Performance Relighting with Conditional Video Diffusion and a Hybrid Dataset
Mar 18, 2025Video portrait relighting remains challenging because the results need to be both photorealistic and temporally stable. This typically requires a strong model design that can capture complex facial reflections as well as intensive training on a high-quality paired video dataset, such as dynamic one-light-at-a-time (OLAT). In this work, we introduce Lux Post Facto, a novel portrait video relighting method that produces both photorealistic and temporally consistent lighting effects. From the model side, we design a new conditional video diffusion model built upon state-of-the-art pre-trained video diffusion model, alongside a new lighting injection mechanism to enable precise control. This way we leverage strong spatial and temporal generative capability to generate plausible solutions to the ill-posed relighting problem. Our technique uses a hybrid dataset consisting of static expression OLAT data and in-the-wild portrait performance videos to jointly learn relighting and temporal modeling. This avoids the need to acquire paired video data in different lighting conditions. Our extensive experiments show that our model produces state-of-the-art results both in terms of photorealism and temporal consistency.
Self-Calibrating Gaussian Splatting for Large Field of View Reconstruction
Feb 13, 2025
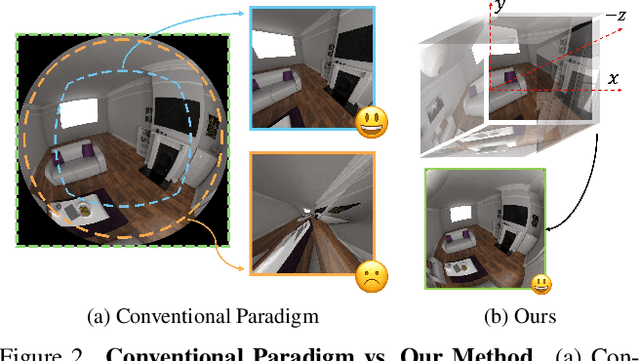
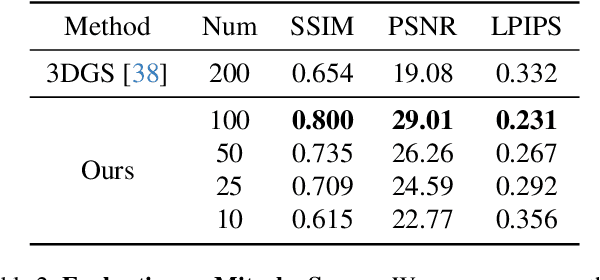
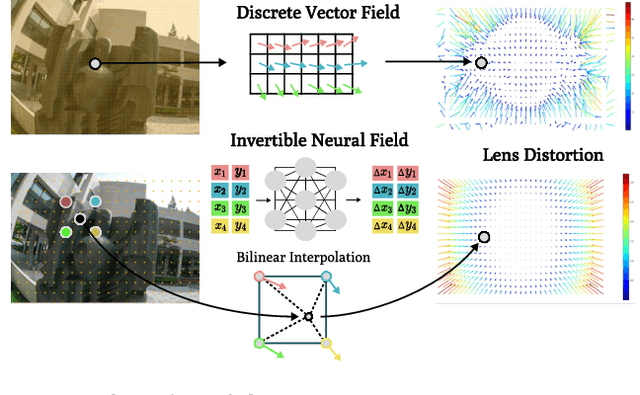
In this paper, we present a self-calibrating framework that jointly optimizes camera parameters, lens distortion and 3D Gaussian representations, enabling accurate and efficient scene reconstruction. In particular, our technique enables high-quality scene reconstruction from Large field-of-view (FOV) imagery taken with wide-angle lenses, allowing the scene to be modeled from a smaller number of images. Our approach introduces a novel method for modeling complex lens distortions using a hybrid network that combines invertible residual networks with explicit grids. This design effectively regularizes the optimization process, achieving greater accuracy than conventional camera models. Additionally, we propose a cubemap-based resampling strategy to support large FOV images without sacrificing resolution or introducing distortion artifacts. Our method is compatible with the fast rasterization of Gaussian Splatting, adaptable to a wide variety of camera lens distortion, and demonstrates state-of-the-art performance on both synthetic and real-world datasets.
Go-with-the-Flow: Motion-Controllable Video Diffusion Models Using Real-Time Warped Noise
Jan 16, 2025



Generative modeling aims to transform random noise into structured outputs. In this work, we enhance video diffusion models by allowing motion control via structured latent noise sampling. This is achieved by just a change in data: we pre-process training videos to yield structured noise. Consequently, our method is agnostic to diffusion model design, requiring no changes to model architectures or training pipelines. Specifically, we propose a novel noise warping algorithm, fast enough to run in real time, that replaces random temporal Gaussianity with correlated warped noise derived from optical flow fields, while preserving the spatial Gaussianity. The efficiency of our algorithm enables us to fine-tune modern video diffusion base models using warped noise with minimal overhead, and provide a one-stop solution for a wide range of user-friendly motion control: local object motion control, global camera movement control, and motion transfer. The harmonization between temporal coherence and spatial Gaussianity in our warped noise leads to effective motion control while maintaining per-frame pixel quality. Extensive experiments and user studies demonstrate the advantages of our method, making it a robust and scalable approach for controlling motion in video diffusion models. Video results are available on our webpage: https://vgenai-netflix-eyeline-research.github.io/Go-with-the-Flow. Source code and model checkpoints are available on GitHub: https://github.com/VGenAI-Netflix-Eyeline-Research/Go-with-the-Flow.
DifFRelight: Diffusion-Based Facial Performance Relighting
Oct 10, 2024



We present a novel framework for free-viewpoint facial performance relighting using diffusion-based image-to-image translation. Leveraging a subject-specific dataset containing diverse facial expressions captured under various lighting conditions, including flat-lit and one-light-at-a-time (OLAT) scenarios, we train a diffusion model for precise lighting control, enabling high-fidelity relit facial images from flat-lit inputs. Our framework includes spatially-aligned conditioning of flat-lit captures and random noise, along with integrated lighting information for global control, utilizing prior knowledge from the pre-trained Stable Diffusion model. This model is then applied to dynamic facial performances captured in a consistent flat-lit environment and reconstructed for novel-view synthesis using a scalable dynamic 3D Gaussian Splatting method to maintain quality and consistency in the relit results. In addition, we introduce unified lighting control by integrating a novel area lighting representation with directional lighting, allowing for joint adjustments in light size and direction. We also enable high dynamic range imaging (HDRI) composition using multiple directional lights to produce dynamic sequences under complex lighting conditions. Our evaluations demonstrate the models efficiency in achieving precise lighting control and generalizing across various facial expressions while preserving detailed features such as skintexture andhair. The model accurately reproduces complex lighting effects like eye reflections, subsurface scattering, self-shadowing, and translucency, advancing photorealism within our framework.
Neural Lens Modeling
Apr 10, 2023



Recent methods for 3D reconstruction and rendering increasingly benefit from end-to-end optimization of the entire image formation process. However, this approach is currently limited: effects of the optical hardware stack and in particular lenses are hard to model in a unified way. This limits the quality that can be achieved for camera calibration and the fidelity of the results of 3D reconstruction. In this paper, we propose NeuroLens, a neural lens model for distortion and vignetting that can be used for point projection and ray casting and can be optimized through both operations. This means that it can (optionally) be used to perform pre-capture calibration using classical calibration targets, and can later be used to perform calibration or refinement during 3D reconstruction, e.g., while optimizing a radiance field. To evaluate the performance of our proposed model, we create a comprehensive dataset assembled from the Lensfun database with a multitude of lenses. Using this and other real-world datasets, we show that the quality of our proposed lens model outperforms standard packages as well as recent approaches while being much easier to use and extend. The model generalizes across many lens types and is trivial to integrate into existing 3D reconstruction and rendering systems.
FactorMatte: Redefining Video Matting for Re-Composition Tasks
Nov 03, 2022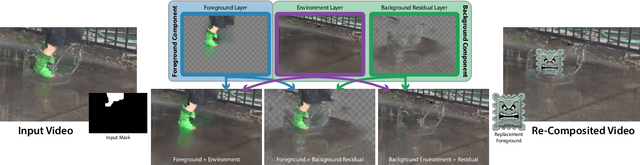

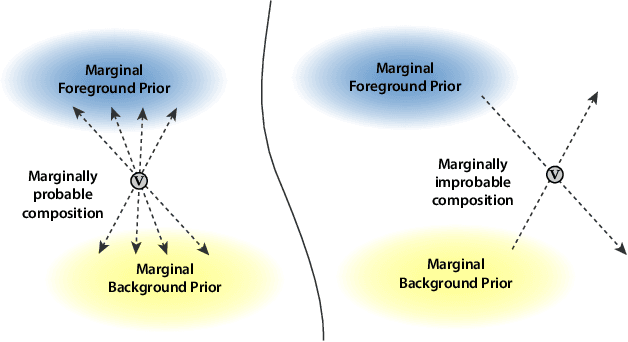

We propose "factor matting", an alternative formulation of the video matting problem in terms of counterfactual video synthesis that is better suited for re-composition tasks. The goal of factor matting is to separate the contents of video into independent components, each visualizing a counterfactual version of the scene where contents of other components have been removed. We show that factor matting maps well to a more general Bayesian framing of the matting problem that accounts for complex conditional interactions between layers. Based on this observation, we present a method for solving the factor matting problem that produces useful decompositions even for video with complex cross-layer interactions like splashes, shadows, and reflections. Our method is trained per-video and requires neither pre-training on external large datasets, nor knowledge about the 3D structure of the scene. We conduct extensive experiments, and show that our method not only can disentangle scenes with complex interactions, but also outperforms top methods on existing tasks such as classical video matting and background subtraction. In addition, we demonstrate the benefits of our approach on a range of downstream tasks. Please refer to our project webpage for more details: https://factormatte.github.io
Stay Positive: Non-Negative Image Synthesis for Augmented Reality
Feb 01, 2022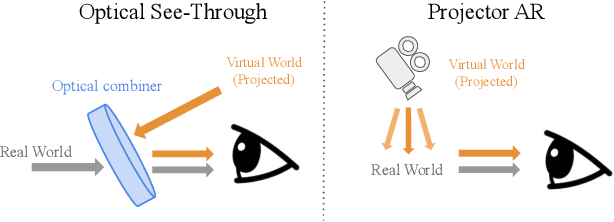
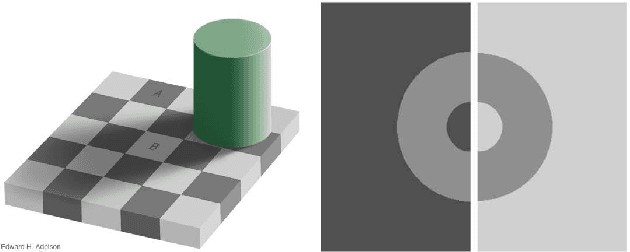
In applications such as optical see-through and projector augmented reality, producing images amounts to solving non-negative image generation, where one can only add light to an existing image. Most image generation methods, however, are ill-suited to this problem setting, as they make the assumption that one can assign arbitrary color to each pixel. In fact, naive application of existing methods fails even in simple domains such as MNIST digits, since one cannot create darker pixels by adding light. We know, however, that the human visual system can be fooled by optical illusions involving certain spatial configurations of brightness and contrast. Our key insight is that one can leverage this behavior to produce high quality images with negligible artifacts. For example, we can create the illusion of darker patches by brightening surrounding pixels. We propose a novel optimization procedure to produce images that satisfy both semantic and non-negativity constraints. Our approach can incorporate existing state-of-the-art methods, and exhibits strong performance in a variety of tasks including image-to-image translation and style transfer.
Space-time Neural Irradiance Fields for Free-Viewpoint Video
Nov 25, 2020

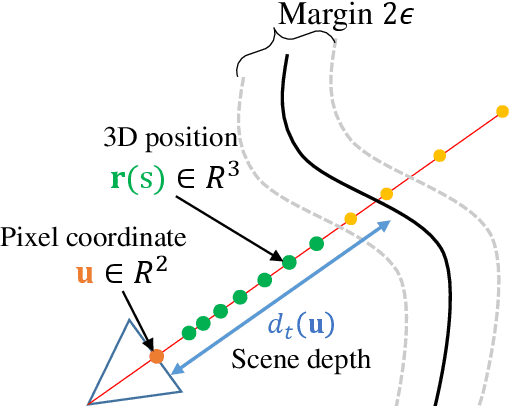

We present a method that learns a spatiotemporal neural irradiance field for dynamic scenes from a single video. Our learned representation enables free-viewpoint rendering of the input video. Our method builds upon recent advances in implicit representations. Learning a spatiotemporal irradiance field from a single video poses significant challenges because the video contains only one observation of the scene at any point in time. The 3D geometry of a scene can be legitimately represented in numerous ways since varying geometry (motion) can be explained with varying appearance and vice versa. We address this ambiguity by constraining the time-varying geometry of our dynamic scene representation using the scene depth estimated from video depth estimation methods, aggregating contents from individual frames into a single global representation. We provide an extensive quantitative evaluation and demonstrate compelling free-viewpoint rendering results.