 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeViewDiff: 3D-Consistent Image Generation with Text-to-Image Models
Mar 04, 2024



3D asset generation is getting massive amounts of attention, inspired by the recent success of text-guided 2D content creation. Existing text-to-3D methods use pretrained text-to-image diffusion models in an optimization problem or fine-tune them on synthetic data, which often results in non-photorealistic 3D objects without backgrounds. In this paper, we present a method that leverages pretrained text-to-image models as a prior, and learn to generate multi-view images in a single denoising process from real-world data. Concretely, we propose to integrate 3D volume-rendering and cross-frame-attention layers into each block of the existing U-Net network of the text-to-image model. Moreover, we design an autoregressive generation that renders more 3D-consistent images at any viewpoint. We train our model on real-world datasets of objects and showcase its capabilities to generate instances with a variety of high-quality shapes and textures in authentic surroundings. Compared to the existing methods, the results generated by our method are consistent, and have favorable visual quality (-30% FID, -37% KID).
VR-NeRF: High-Fidelity Virtualized Walkable Spaces
Nov 05, 2023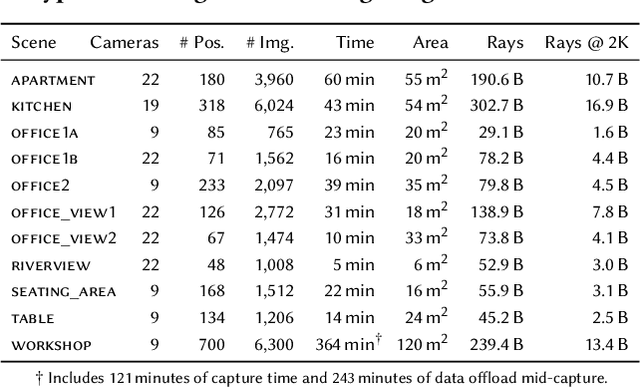
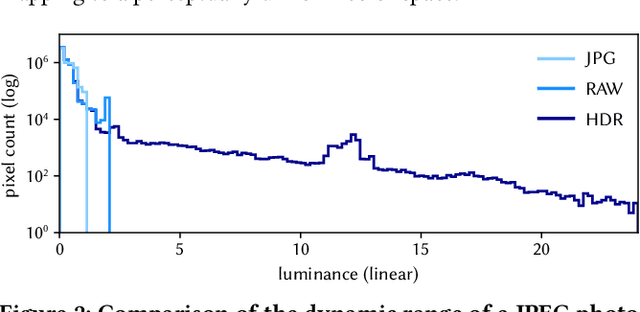
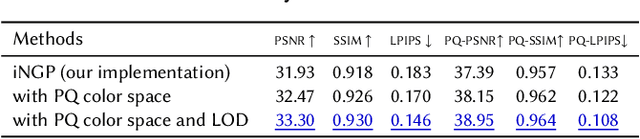
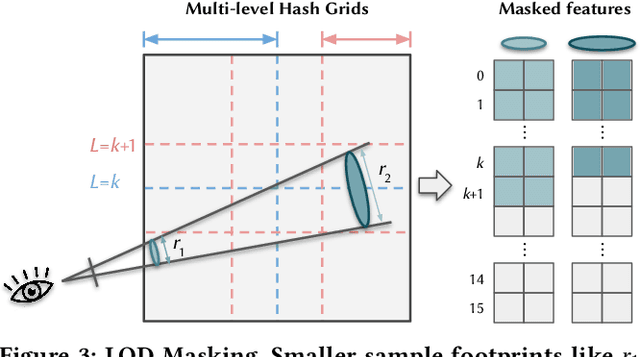
We present an end-to-end system for the high-fidelity capture, model reconstruction, and real-time rendering of walkable spaces in virtual reality using neural radiance fields. To this end, we designed and built a custom multi-camera rig to densely capture walkable spaces in high fidelity and with multi-view high dynamic range images in unprecedented quality and density. We extend instant neural graphics primitives with a novel perceptual color space for learning accurate HDR appearance, and an efficient mip-mapping mechanism for level-of-detail rendering with anti-aliasing, while carefully optimizing the trade-off between quality and speed. Our multi-GPU renderer enables high-fidelity volume rendering of our neural radiance field model at the full VR resolution of dual 2K$\times$2K at 36 Hz on our custom demo machine. We demonstrate the quality of our results on our challenging high-fidelity datasets, and compare our method and datasets to existing baselines. We release our dataset on our project website.
Learning Neural Duplex Radiance Fields for Real-Time View Synthesis
Apr 20, 2023



Neural radiance fields (NeRFs) enable novel view synthesis with unprecedented visual quality. However, to render photorealistic images, NeRFs require hundreds of deep multilayer perceptron (MLP) evaluations - for each pixel. This is prohibitively expensive and makes real-time rendering infeasible, even on powerful modern GPUs. In this paper, we propose a novel approach to distill and bake NeRFs into highly efficient mesh-based neural representations that are fully compatible with the massively parallel graphics rendering pipeline. We represent scenes as neural radiance features encoded on a two-layer duplex mesh, which effectively overcomes the inherent inaccuracies in 3D surface reconstruction by learning the aggregated radiance information from a reliable interval of ray-surface intersections. To exploit local geometric relationships of nearby pixels, we leverage screen-space convolutions instead of the MLPs used in NeRFs to achieve high-quality appearance. Finally, the performance of the whole framework is further boosted by a novel multi-view distillation optimization strategy. We demonstrate the effectiveness and superiority of our approach via extensive experiments on a range of standard datasets.
Neural Lens Modeling
Apr 10, 2023



Recent methods for 3D reconstruction and rendering increasingly benefit from end-to-end optimization of the entire image formation process. However, this approach is currently limited: effects of the optical hardware stack and in particular lenses are hard to model in a unified way. This limits the quality that can be achieved for camera calibration and the fidelity of the results of 3D reconstruction. In this paper, we propose NeuroLens, a neural lens model for distortion and vignetting that can be used for point projection and ray casting and can be optimized through both operations. This means that it can (optionally) be used to perform pre-capture calibration using classical calibration targets, and can later be used to perform calibration or refinement during 3D reconstruction, e.g., while optimizing a radiance field. To evaluate the performance of our proposed model, we create a comprehensive dataset assembled from the Lensfun database with a multitude of lenses. Using this and other real-world datasets, we show that the quality of our proposed lens model outperforms standard packages as well as recent approaches while being much easier to use and extend. The model generalizes across many lens types and is trivial to integrate into existing 3D reconstruction and rendering systems.
Neural Assets: Volumetric Object Capture and Rendering for Interactive Environments
Dec 12, 2022



Creating realistic virtual assets is a time-consuming process: it usually involves an artist designing the object, then spending a lot of effort on tweaking its appearance. Intricate details and certain effects, such as subsurface scattering, elude representation using real-time BRDFs, making it impossible to fully capture the appearance of certain objects. Inspired by the recent progress of neural rendering, we propose an approach for capturing real-world objects in everyday environments faithfully and fast. We use a novel neural representation to reconstruct volumetric effects, such as translucent object parts, and preserve photorealistic object appearance. To support real-time rendering without compromising rendering quality, our model uses a grid of features and a small MLP decoder that is transpiled into efficient shader code with interactive framerates. This leads to a seamless integration of the proposed neural assets with existing mesh environments and objects. Thanks to the use of standard shader code rendering is portable across many existing hardware and software systems.
RC-MVSNet: Unsupervised Multi-View Stereo with Neural Rendering
Mar 14, 2022
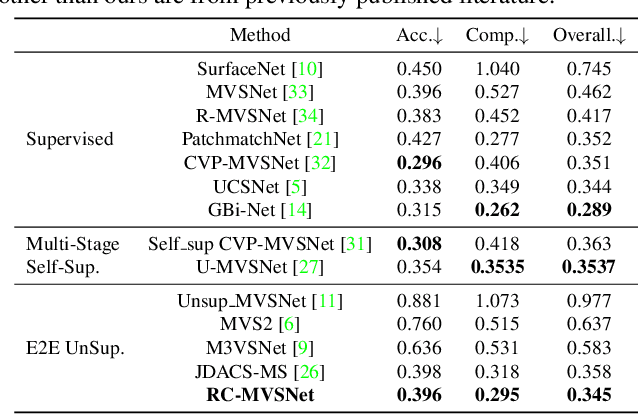
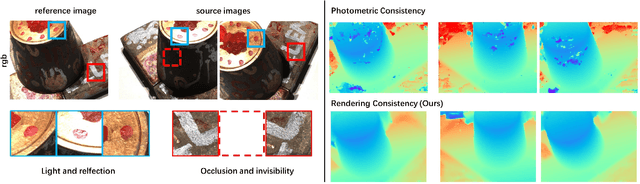
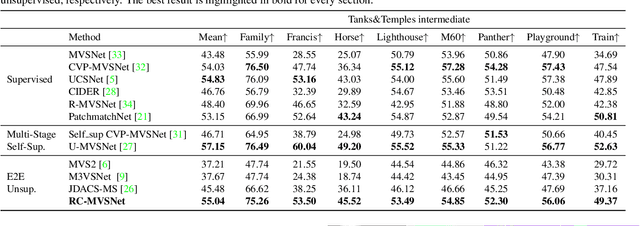
Finding accurate correspondences among different views is the Achilles' heel of unsupervised Multi-View Stereo (MVS). Existing methods are built upon the assumption that corresponding pixels share similar photometric features. However, multi-view images in real scenarios observe non-Lambertian surfaces and experience occlusions. In this work, we propose a novel approach with neural rendering (RC-MVSNet) to solve such ambiguity issues of correspondences among views. Specifically, we impose a depth rendering consistency loss to constrain the geometry features close to the object surface to alleviate occlusions. Concurrently, we introduce a reference view synthesis loss to generate consistent supervision, even for non-Lambertian surfaces. Extensive experiments on DTU and Tanks\&Temples benchmarks demonstrate that our RC-MVSNet approach achieves state-of-the-art performance over unsupervised MVS frameworks and competitive performance to many supervised methods.The trained models and code will be released at https://github.com/Boese0601/RC-MVSNet.
TransformerFusion: Monocular RGB Scene Reconstruction using Transformers
Jul 05, 2021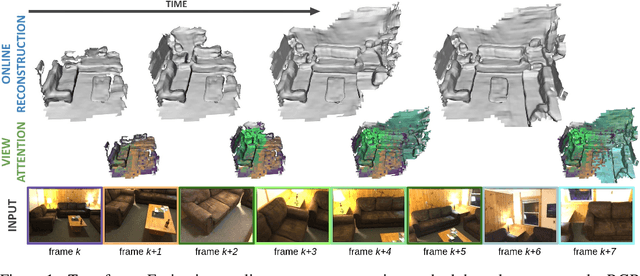
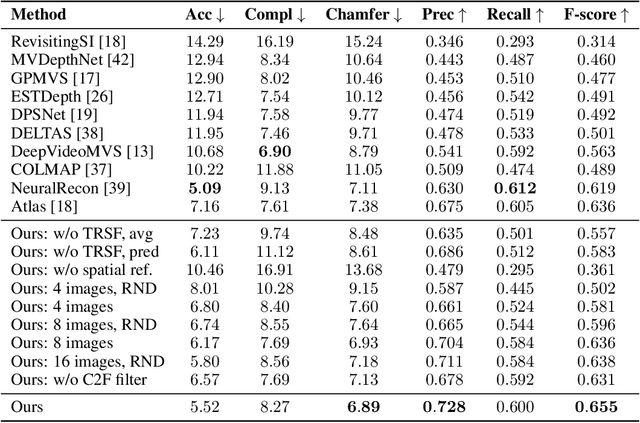
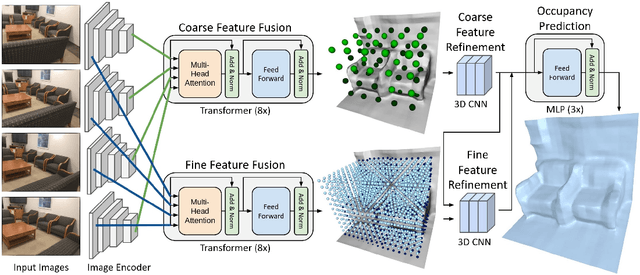

We introduce TransformerFusion, a transformer-based 3D scene reconstruction approach. From an input monocular RGB video, the video frames are processed by a transformer network that fuses the observations into a volumetric feature grid representing the scene; this feature grid is then decoded into an implicit 3D scene representation. Key to our approach is the transformer architecture that enables the network to learn to attend to the most relevant image frames for each 3D location in the scene, supervised only by the scene reconstruction task. Features are fused in a coarse-to-fine fashion, storing fine-level features only where needed, requiring lower memory storage and enabling fusion at interactive rates. The feature grid is then decoded to a higher-resolution scene reconstruction, using an MLP-based surface occupancy prediction from interpolated coarse-to-fine 3D features. Our approach results in an accurate surface reconstruction, outperforming state-of-the-art multi-view stereo depth estimation methods, fully-convolutional 3D reconstruction approaches, and approaches using LSTM- or GRU-based recurrent networks for video sequence fusion.
NPMs: Neural Parametric Models for 3D Deformable Shapes
Apr 01, 2021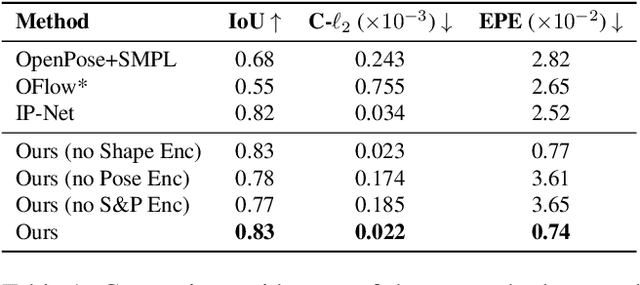
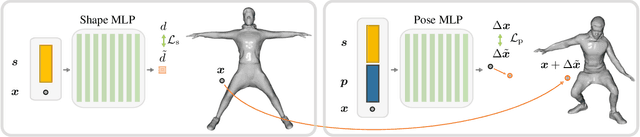

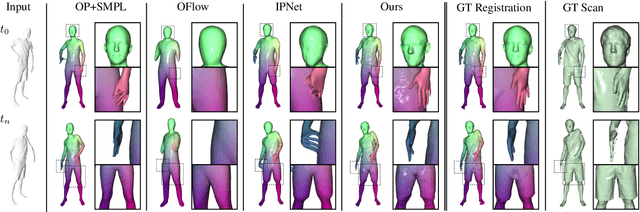
Parametric 3D models have enabled a wide variety of tasks in computer graphics and vision, such as modeling human bodies, faces, and hands. However, the construction of these parametric models is often tedious, as it requires heavy manual tweaking, and they struggle to represent additional complexity and details such as wrinkles or clothing. To this end, we propose Neural Parametric Models (NPMs), a novel, learned alternative to traditional, parametric 3D models, which does not require hand-crafted, object-specific constraints. In particular, we learn to disentangle 4D dynamics into latent-space representations of shape and pose, leveraging the flexibility of recent developments in learned implicit functions. Crucially, once learned, our neural parametric models of shape and pose enable optimization over the learned spaces to fit to new observations, similar to the fitting of a traditional parametric model, e.g., SMPL. This enables NPMs to achieve a significantly more accurate and detailed representation of observed deformable sequences. We show that NPMs improve notably over both parametric and non-parametric state of the art in reconstruction and tracking of monocular depth sequences of clothed humans and hands. Latent-space interpolation as well as shape / pose transfer experiments further demonstrate the usefulness of NPMs.
Neural Deformation Graphs for Globally-consistent Non-rigid Reconstruction
Dec 02, 2020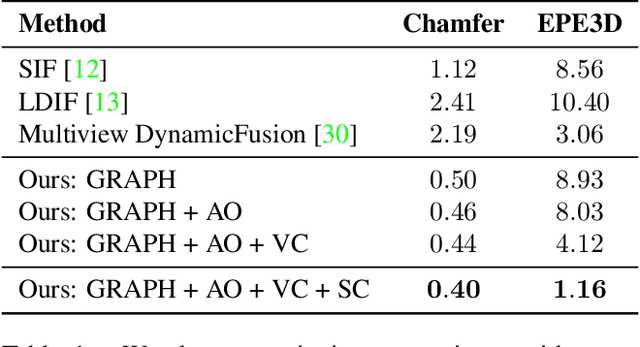
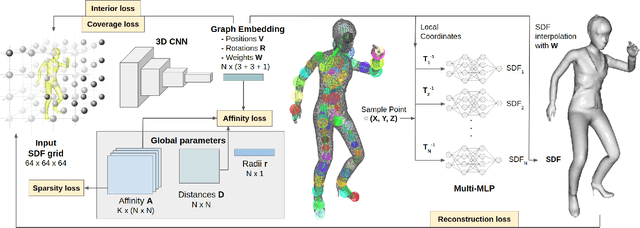


We introduce Neural Deformation Graphs for globally-consistent deformation tracking and 3D reconstruction of non-rigid objects. Specifically, we implicitly model a deformation graph via a deep neural network. This neural deformation graph does not rely on any object-specific structure and, thus, can be applied to general non-rigid deformation tracking. Our method globally optimizes this neural graph on a given sequence of depth camera observations of a non-rigidly moving object. Based on explicit viewpoint consistency as well as inter-frame graph and surface consistency constraints, the underlying network is trained in a self-supervised fashion. We additionally optimize for the geometry of the object with an implicit deformable multi-MLP shape representation. Our approach does not assume sequential input data, thus enabling robust tracking of fast motions or even temporally disconnected recordings. Our experiments demonstrate that our Neural Deformation Graphs outperform state-of-the-art non-rigid reconstruction approaches both qualitatively and quantitatively, with 64% improved reconstruction and 62% improved deformation tracking performance.
Neural Non-Rigid Tracking
Jun 23, 2020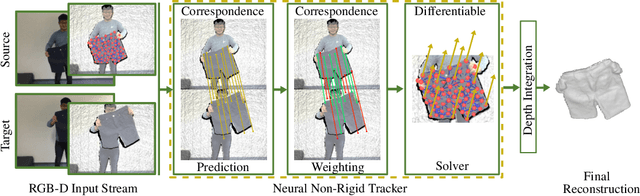
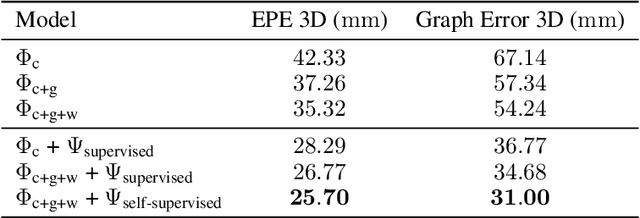
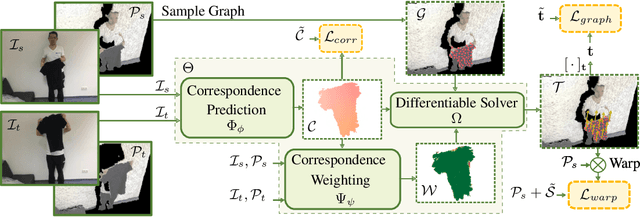
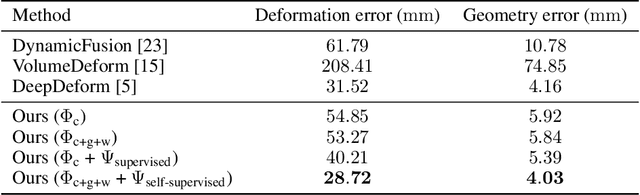
We introduce a novel, end-to-end learnable, differentiable non-rigid tracker that enables state-of-the-art non-rigid reconstruction. Given two input RGB-D frames of a non-rigidly moving object, we employ a convolutional neural network to predict dense correspondences. These correspondences are used as constraints in an as-rigid-as-possible (ARAP) optimization problem. By enabling gradient back-propagation through the non-rigid optimization solver, we are able to learn correspondences in an end-to-end manner such that they are optimal for the task of non-rigid tracking. Furthermore, this formulation allows for learning correspondence weights in a self-supervised manner. Thus, outliers and wrong correspondences are down-weighted to enable robust tracking. Compared to state-of-the-art approaches, our algorithm shows improved reconstruction performance, while simultaneously achieving 85 times faster correspondence prediction than comparable deep-learning based methods.