 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVirtual Fitting Room: Generating Arbitrarily Long Videos of Virtual Try-On from a Single Image -- Technical Preview
Sep 04, 2025We introduce the Virtual Fitting Room (VFR), a novel video generative model that produces arbitrarily long virtual try-on videos. Our VFR models long video generation tasks as an auto-regressive, segment-by-segment generation process, eliminating the need for resource-intensive generation and lengthy video data, while providing the flexibility to generate videos of arbitrary length. The key challenges of this task are twofold: ensuring local smoothness between adjacent segments and maintaining global temporal consistency across different segments. To address these challenges, we propose our VFR framework, which ensures smoothness through a prefix video condition and enforces consistency with the anchor video -- a 360-degree video that comprehensively captures the human's wholebody appearance. Our VFR generates minute-scale virtual try-on videos with both local smoothness and global temporal consistency under various motions, making it a pioneering work in long virtual try-on video generation.
Dress&Dance: Dress up and Dance as You Like It - Technical Preview
Aug 28, 2025We present Dress&Dance, a video diffusion framework that generates high quality 5-second-long 24 FPS virtual try-on videos at 1152x720 resolution of a user wearing desired garments while moving in accordance with a given reference video. Our approach requires a single user image and supports a range of tops, bottoms, and one-piece garments, as well as simultaneous tops and bottoms try-on in a single pass. Key to our framework is CondNet, a novel conditioning network that leverages attention to unify multi-modal inputs (text, images, and videos), thereby enhancing garment registration and motion fidelity. CondNet is trained on heterogeneous training data, combining limited video data and a larger, more readily available image dataset, in a multistage progressive manner. Dress&Dance outperforms existing open source and commercial solutions and enables a high quality and flexible try-on experience.
VR-NeRF: High-Fidelity Virtualized Walkable Spaces
Nov 05, 2023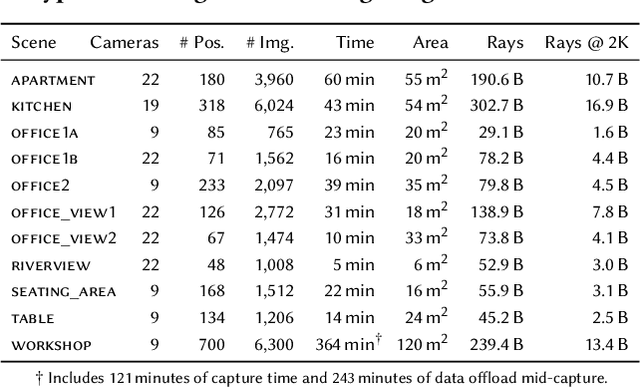
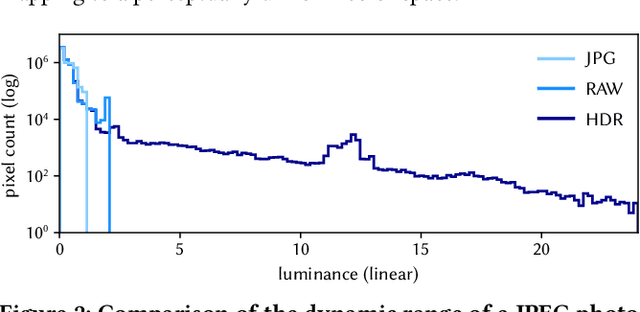
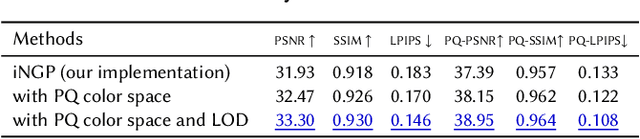
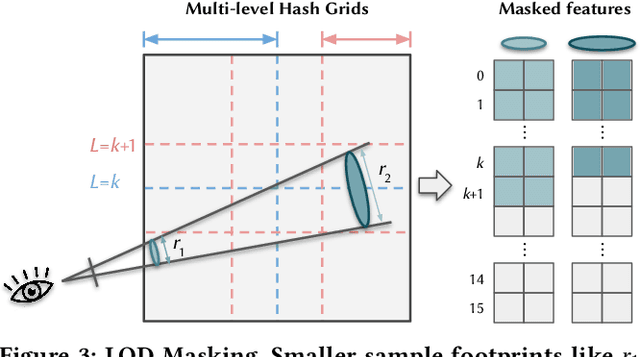
We present an end-to-end system for the high-fidelity capture, model reconstruction, and real-time rendering of walkable spaces in virtual reality using neural radiance fields. To this end, we designed and built a custom multi-camera rig to densely capture walkable spaces in high fidelity and with multi-view high dynamic range images in unprecedented quality and density. We extend instant neural graphics primitives with a novel perceptual color space for learning accurate HDR appearance, and an efficient mip-mapping mechanism for level-of-detail rendering with anti-aliasing, while carefully optimizing the trade-off between quality and speed. Our multi-GPU renderer enables high-fidelity volume rendering of our neural radiance field model at the full VR resolution of dual 2K$\times$2K at 36 Hz on our custom demo machine. We demonstrate the quality of our results on our challenging high-fidelity datasets, and compare our method and datasets to existing baselines. We release our dataset on our project website.
EgoHumans: An Egocentric 3D Multi-Human Benchmark
May 25, 2023



We present EgoHumans, a new multi-view multi-human video benchmark to advance the state-of-the-art of egocentric human 3D pose estimation and tracking. Existing egocentric benchmarks either capture single subject or indoor-only scenarios, which limit the generalization of computer vision algorithms for real-world applications. We propose a novel 3D capture setup to construct a comprehensive egocentric multi-human benchmark in the wild with annotations to support diverse tasks such as human detection, tracking, 2D/3D pose estimation, and mesh recovery. We leverage consumer-grade wearable camera-equipped glasses for the egocentric view, which enables us to capture dynamic activities like playing soccer, fencing, volleyball, etc. Furthermore, our multi-view setup generates accurate 3D ground truth even under severe or complete occlusion. The dataset consists of more than 125k egocentric images, spanning diverse scenes with a particular focus on challenging and unchoreographed multi-human activities and fast-moving egocentric views. We rigorously evaluate existing state-of-the-art methods and highlight their limitations in the egocentric scenario, specifically on multi-human tracking. To address such limitations, we propose EgoFormer, a novel approach with a multi-stream transformer architecture and explicit 3D spatial reasoning to estimate and track the human pose. EgoFormer significantly outperforms prior art by 13.6% IDF1 and 9.3 HOTA on the EgoHumans dataset.
Neural Pixel Composition: 3D-4D View Synthesis from Multi-Views
Jul 21, 2022
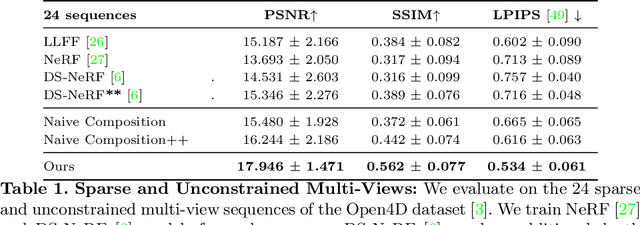
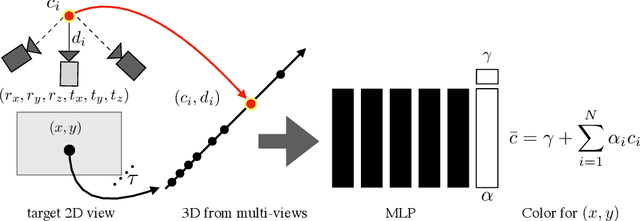
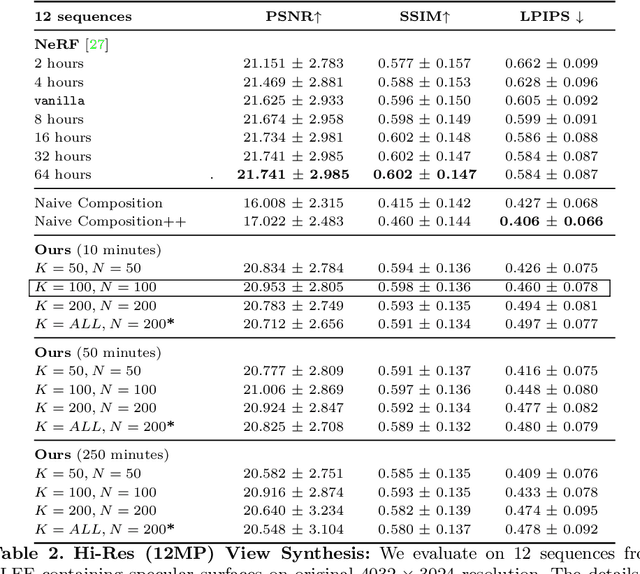
We present Neural Pixel Composition (NPC), a novel approach for continuous 3D-4D view synthesis given only a discrete set of multi-view observations as input. Existing state-of-the-art approaches require dense multi-view supervision and an extensive computational budget. The proposed formulation reliably operates on sparse and wide-baseline multi-view imagery and can be trained efficiently within a few seconds to 10 minutes for hi-res (12MP) content, i.e., 200-400X faster convergence than existing methods. Crucial to our approach are two core novelties: 1) a representation of a pixel that contains color and depth information accumulated from multi-views for a particular location and time along a line of sight, and 2) a multi-layer perceptron (MLP) that enables the composition of this rich information provided for a pixel location to obtain the final color output. We experiment with a large variety of multi-view sequences, compare to existing approaches, and achieve better results in diverse and challenging settings. Finally, our approach enables dense 3D reconstruction from sparse multi-views, where COLMAP, a state-of-the-art 3D reconstruction approach, struggles.
KeypointNeRF: Generalizing Image-based Volumetric Avatars using Relative Spatial Encoding of Keypoints
May 10, 2022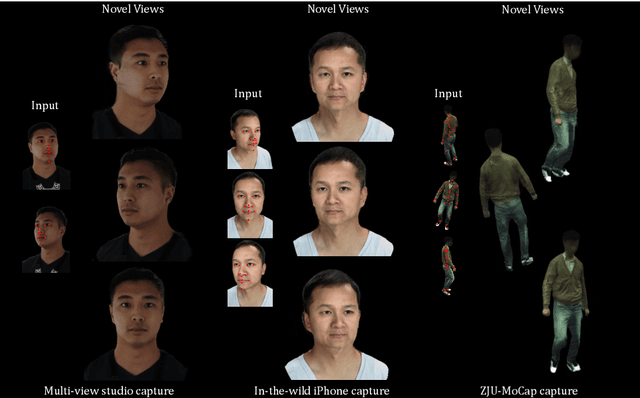

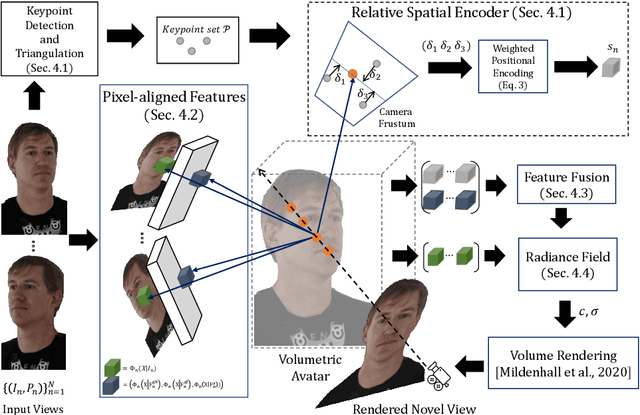
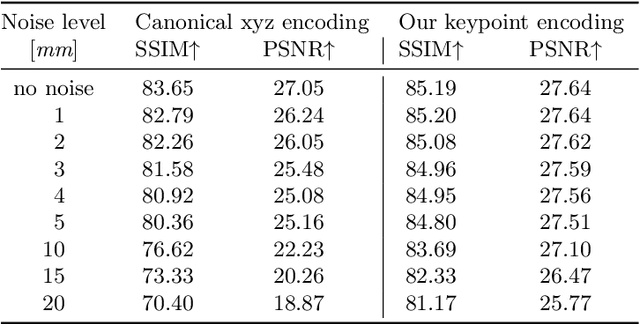
Image-based volumetric avatars using pixel-aligned features promise generalization to unseen poses and identities. Prior work leverages global spatial encodings and multi-view geometric consistency to reduce spatial ambiguity. However, global encodings often suffer from overfitting to the distribution of the training data, and it is difficult to learn multi-view consistent reconstruction from sparse views. In this work, we investigate common issues with existing spatial encodings and propose a simple yet highly effective approach to modeling high-fidelity volumetric avatars from sparse views. One of the key ideas is to encode relative spatial 3D information via sparse 3D keypoints. This approach is robust to the sparsity of viewpoints and cross-dataset domain gap. Our approach outperforms state-of-the-art methods for head reconstruction. On human body reconstruction for unseen subjects, we also achieve performance comparable to prior work that uses a parametric human body model and temporal feature aggregation. Our experiments show that a majority of errors in prior work stem from an inappropriate choice of spatial encoding and thus we suggest a new direction for high-fidelity image-based avatar modeling. https://markomih.github.io/KeypointNeRF
COAP: Compositional Articulated Occupancy of People
Apr 13, 2022
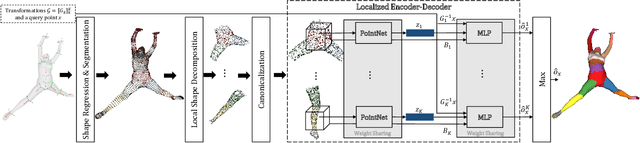
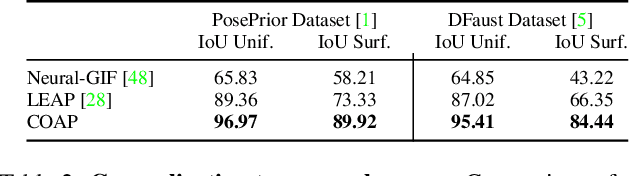
We present a novel neural implicit representation for articulated human bodies. Compared to explicit template meshes, neural implicit body representations provide an efficient mechanism for modeling interactions with the environment, which is essential for human motion reconstruction and synthesis in 3D scenes. However, existing neural implicit bodies suffer from either poor generalization on highly articulated poses or slow inference time. In this work, we observe that prior knowledge about the human body's shape and kinematic structure can be leveraged to improve generalization and efficiency. We decompose the full-body geometry into local body parts and employ a part-aware encoder-decoder architecture to learn neural articulated occupancy that models complex deformations locally. Our local shape encoder represents the body deformation of not only the corresponding body part but also the neighboring body parts. The decoder incorporates the geometric constraints of local body shape which significantly improves pose generalization. We demonstrate that our model is suitable for resolving self-intersections and collisions with 3D environments. Quantitative and qualitative experiments show that our method largely outperforms existing solutions in terms of both efficiency and accuracy. The code and models are available at https://neuralbodies.github.io/COAP/index.html
Stereo Radiance Fields (SRF): Learning View Synthesis for Sparse Views of Novel Scenes
Apr 14, 2021

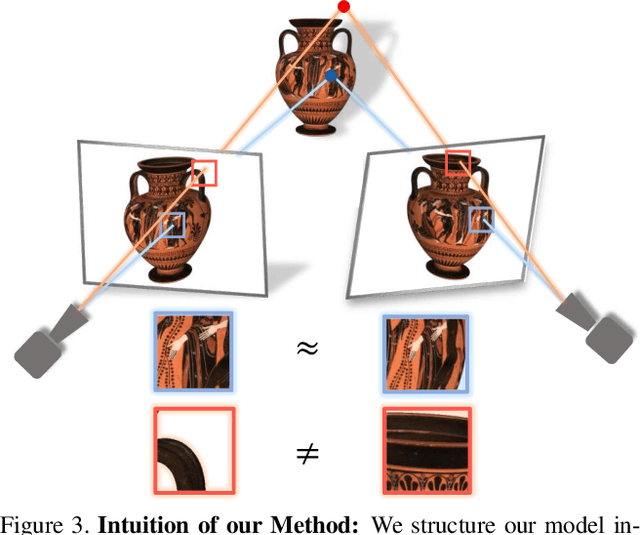
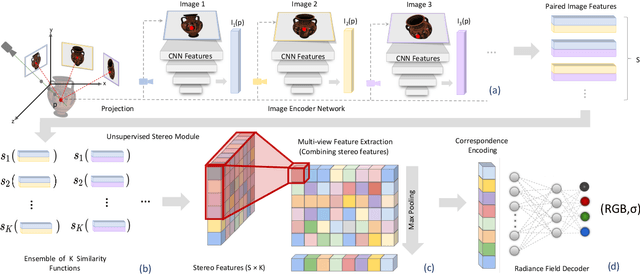
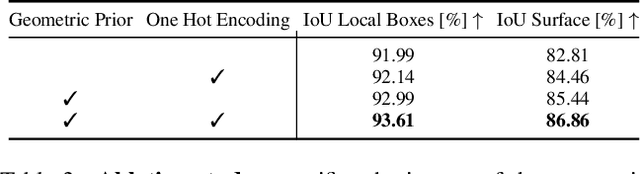
Recent neural view synthesis methods have achieved impressive quality and realism, surpassing classical pipelines which rely on multi-view reconstruction. State-of-the-Art methods, such as NeRF, are designed to learn a single scene with a neural network and require dense multi-view inputs. Testing on a new scene requires re-training from scratch, which takes 2-3 days. In this work, we introduce Stereo Radiance Fields (SRF), a neural view synthesis approach that is trained end-to-end, generalizes to new scenes, and requires only sparse views at test time. The core idea is a neural architecture inspired by classical multi-view stereo methods, which estimates surface points by finding similar image regions in stereo images. In SRF, we predict color and density for each 3D point given an encoding of its stereo correspondence in the input images. The encoding is implicitly learned by an ensemble of pair-wise similarities -- emulating classical stereo. Experiments show that SRF learns structure instead of overfitting on a scene. We train on multiple scenes of the DTU dataset and generalize to new ones without re-training, requiring only 10 sparse and spread-out views as input. We show that 10-15 minutes of fine-tuning further improve the results, achieving significantly sharper, more detailed results than scene-specific models. The code, model, and videos are available at https://virtualhumans.mpi-inf.mpg.de/srf/.
* IEEE Conference on Computer Vision and Pattern Recognition (CVPR) 2021
Streaming Self-Training via Domain-Agnostic Unlabeled Images
Apr 07, 2021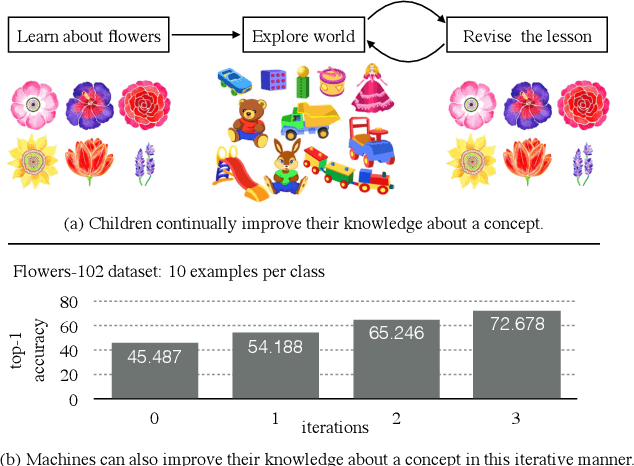
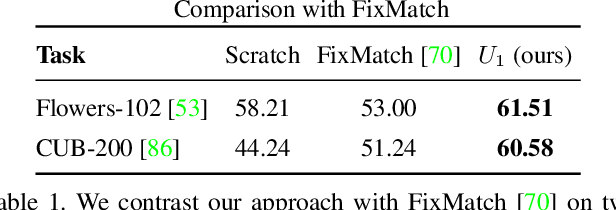
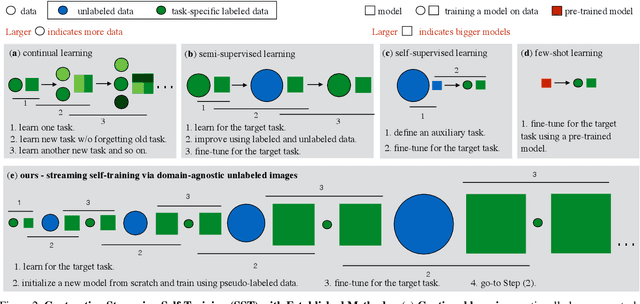
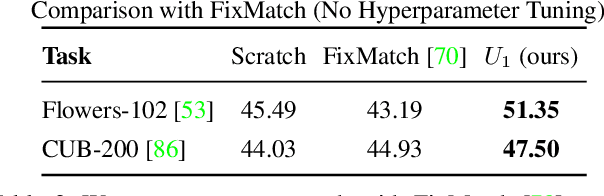
We present streaming self-training (SST) that aims to democratize the process of learning visual recognition models such that a non-expert user can define a new task depending on their needs via a few labeled examples and minimal domain knowledge. Key to SST are two crucial observations: (1) domain-agnostic unlabeled images enable us to learn better models with a few labeled examples without any additional knowledge or supervision; and (2) learning is a continuous process and can be done by constructing a schedule of learning updates that iterates between pre-training on novel segments of the streams of unlabeled data, and fine-tuning on the small and fixed labeled dataset. This allows SST to overcome the need for a large number of domain-specific labeled and unlabeled examples, exorbitant computational resources, and domain/task-specific knowledge. In this setting, classical semi-supervised approaches require a large amount of domain-specific labeled and unlabeled examples, immense resources to process data, and expert knowledge of a particular task. Due to these reasons, semi-supervised learning has been restricted to a few places that can house required computational and human resources. In this work, we overcome these challenges and demonstrate our findings for a wide range of visual recognition tasks including fine-grained image classification, surface normal estimation, and semantic segmentation. We also demonstrate our findings for diverse domains including medical, satellite, and agricultural imagery, where there does not exist a large amount of labeled or unlabeled data.
Video Exploration via Video-Specific Autoencoders
Mar 31, 2021We present simple video-specific autoencoders that enables human-controllable video exploration. This includes a wide variety of analytic tasks such as (but not limited to) spatial and temporal super-resolution, spatial and temporal editing, object removal, video textures, average video exploration, and correspondence estimation within and across videos. Prior work has independently looked at each of these problems and proposed different formulations. In this work, we observe that a simple autoencoder trained (from scratch) on multiple frames of a specific video enables one to perform a large variety of video processing and editing tasks. Our tasks are enabled by two key observations: (1) latent codes learned by the autoencoder capture spatial and temporal properties of that video and (2) autoencoders can project out-of-sample inputs onto the video-specific manifold. For e.g. (1) interpolating latent codes enables temporal super-resolution and user-controllable video textures; (2) manifold reprojection enables spatial super-resolution, object removal, and denoising without training for any of the tasks. Importantly, a two-dimensional visualization of latent codes via principal component analysis acts as a tool for users to both visualize and intuitively control video edits. Finally, we quantitatively contrast our approach with the prior art and found that without any supervision and task-specific knowledge, our approach can perform comparably to supervised approaches specifically trained for a task.