 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving task-specific representation via 1M unlabelled images without any extra knowledge
Paper and Code
Jun 24, 2020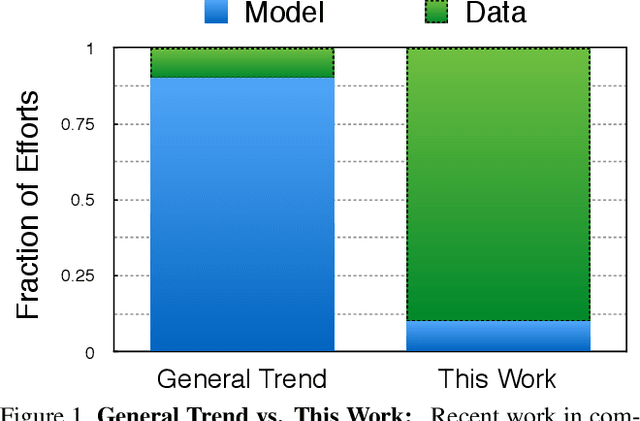
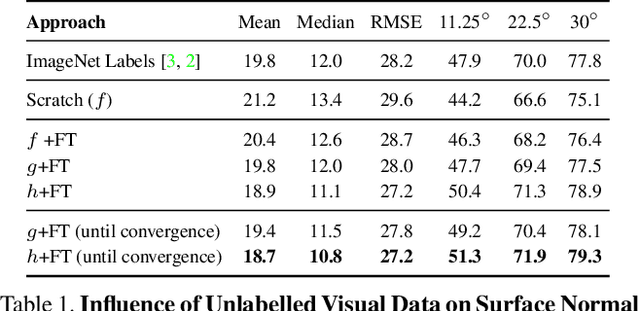
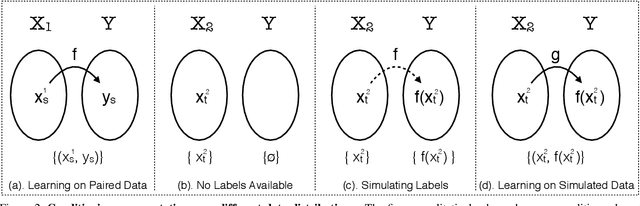
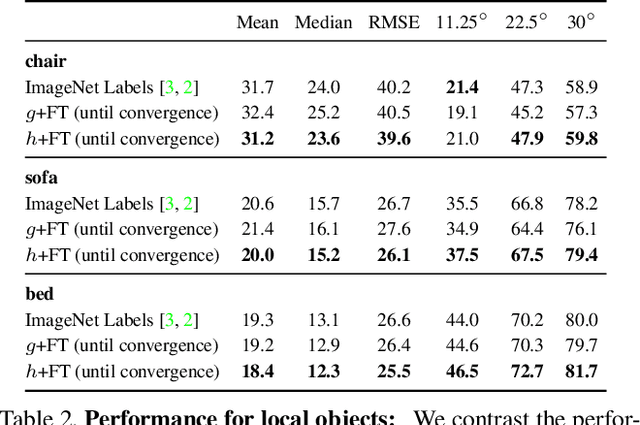
We present a case-study to improve the task-specific representation by leveraging a million unlabelled images without any extra knowledge. We propose an exceedingly simple method of conditioning an existing representation on a diverse data distribution and observe that a model trained on diverse examples acts as a better initialization. We extensively study our findings for the task of surface normal estimation and semantic segmentation from a single image. We improve surface normal estimation on NYU-v2 depth dataset and semantic segmentation on PASCAL VOC by 4% over base model. We did not use any task-specific knowledge or auxiliary tasks, neither changed hyper-parameters nor made any modification in the underlying neural network architecture.