 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePositional Biases Shift as Inputs Approach Context Window Limits
Aug 10, 2025



Large Language Models (LLMs) often struggle to use information across long inputs effectively. Prior work has identified positional biases, such as the Lost in the Middle (LiM) effect, where models perform better when information appears at the beginning (primacy bias) or end (recency bias) of the input, rather than in the middle. However, long-context studies have not consistently replicated these effects, raising questions about their intensity and the conditions under which they manifest. To address this, we conducted a comprehensive analysis using relative rather than absolute input lengths, defined with respect to each model's context window. Our findings reveal that the LiM effect is strongest when inputs occupy up to 50% of a model's context window. Beyond that, the primacy bias weakens, while recency bias remains relatively stable. This effectively eliminates the LiM effect; instead, we observe a distance-based bias, where model performance is better when relevant information is closer to the end of the input. Furthermore, our results suggest that successful retrieval is a prerequisite for reasoning in LLMs, and that the observed positional biases in reasoning are largely inherited from retrieval. These insights have implications for long-context tasks, the design of future LLM benchmarks, and evaluation methodologies for LLMs handling extended inputs.
TriDi: Trilateral Diffusion of 3D Humans, Objects, and Interactions
Dec 09, 2024Modeling 3D human-object interaction (HOI) is a problem of great interest for computer vision and a key enabler for virtual and mixed-reality applications. Existing methods work in a one-way direction: some recover plausible human interactions conditioned on a 3D object; others recover the object pose conditioned on a human pose. Instead, we provide the first unified model - TriDi which works in any direction. Concretely, we generate Human, Object, and Interaction modalities simultaneously with a new three-way diffusion process, allowing to model seven distributions with one network. We implement TriDi as a transformer attending to the various modalities' tokens, thereby discovering conditional relations between them. The user can control the interaction either as a text description of HOI or a contact map. We embed these two representations into a shared latent space, combining the practicality of text descriptions with the expressiveness of contact maps. Using a single network, TriDi unifies all the special cases of prior work and extends to new ones, modeling a family of seven distributions. Remarkably, despite using a single model, TriDi generated samples surpass one-way specialized baselines on GRAB and BEHAVE in terms of both qualitative and quantitative metrics, and demonstrating better diversity. We show the applicability of TriDi to scene population, generating objects for human-contact datasets, and generalization to unseen object geometry. The project page is available at: https://virtualhumans.mpi-inf.mpg.de/tridi.
Unimotion: Unifying 3D Human Motion Synthesis and Understanding
Sep 24, 2024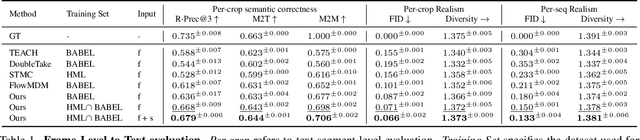
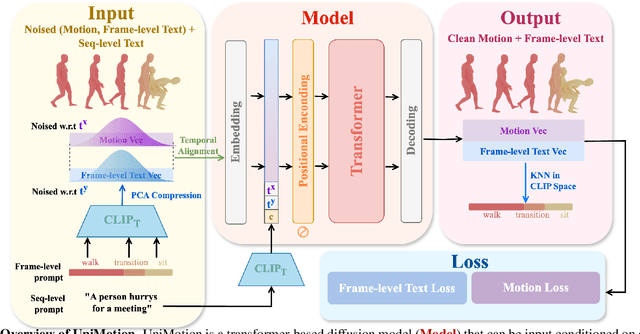
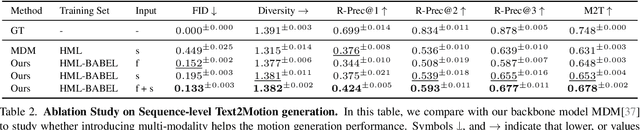
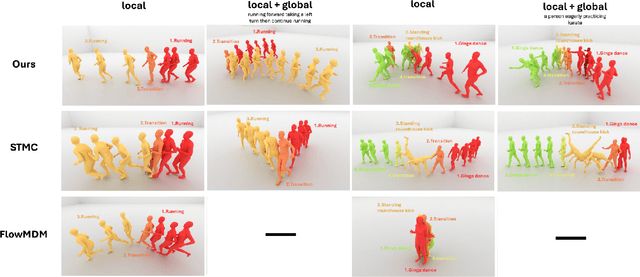
We introduce Unimotion, the first unified multi-task human motion model capable of both flexible motion control and frame-level motion understanding. While existing works control avatar motion with global text conditioning, or with fine-grained per frame scripts, none can do both at once. In addition, none of the existing works can output frame-level text paired with the generated poses. In contrast, Unimotion allows to control motion with global text, or local frame-level text, or both at once, providing more flexible control for users. Importantly, Unimotion is the first model which by design outputs local text paired with the generated poses, allowing users to know what motion happens and when, which is necessary for a wide range of applications. We show Unimotion opens up new applications: 1.) Hierarchical control, allowing users to specify motion at different levels of detail, 2.) Obtaining motion text descriptions for existing MoCap data or YouTube videos 3.) Allowing for editability, generating motion from text, and editing the motion via text edits. Moreover, Unimotion attains state-of-the-art results for the frame-level text-to-motion task on the established HumanML3D dataset. The pre-trained model and code are available available on our project page at https://coral79.github.io/Unimotion/.
Object pop-up: Can we infer 3D objects and their poses from human interactions alone?
Jun 01, 2023The intimate entanglement between objects affordances and human poses is of large interest, among others, for behavioural sciences, cognitive psychology, and Computer Vision communities. In recent years, the latter has developed several object-centric approaches: starting from items, learning pipelines synthesizing human poses and dynamics in a realistic way, satisfying both geometrical and functional expectations. However, the inverse perspective is significantly less explored: Can we infer 3D objects and their poses from human interactions alone? Our investigation follows this direction, showing that a generic 3D human point cloud is enough to pop up an unobserved object, even when the user is just imitating a functionality (e.g., looking through a binocular) without involving a tangible counterpart. We validate our method qualitatively and quantitatively, with synthetic data and sequences acquired for the task, showing applicability for XR/VR. The code is available at https://github.com/ptrvilya/object-popup.
Semantic Instance Segmentation of 3D Scenes Through Weak Bounding Box Supervision
Jun 02, 2022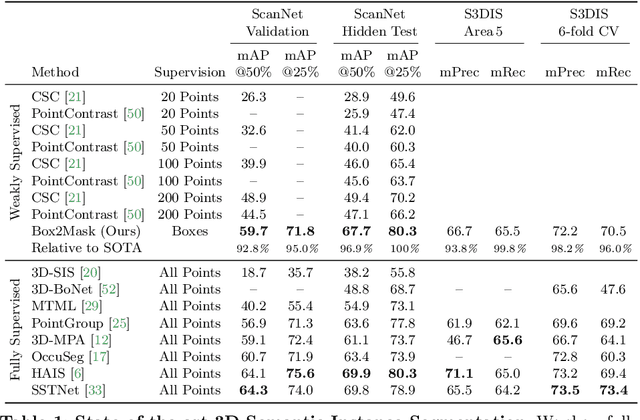
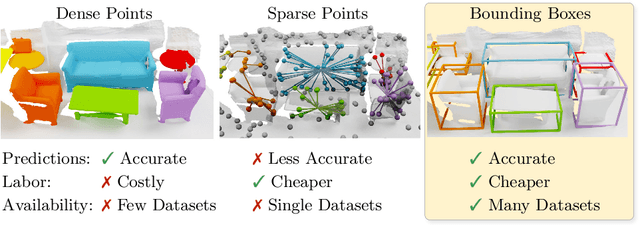
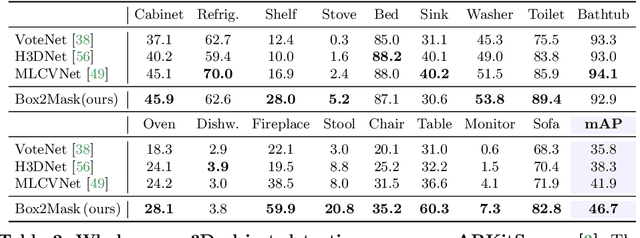
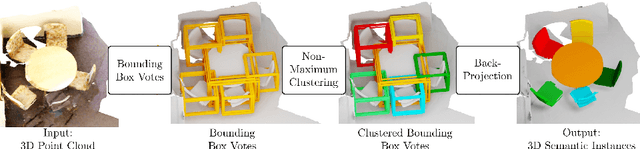
Current 3D segmentation methods heavily rely on large-scale point-cloud datasets, which are notoriously laborious to annotate. Few attempts have been made to circumvent the need for dense per-point annotations. In this work, we look at weakly-supervised 3D instance semantic segmentation. The key idea is to leverage 3D bounding box labels which are easier and faster to annotate. Indeed, we show that it is possible to train dense segmentation models using only weak bounding box labels. At the core of our method, Box2Mask, lies a deep model, inspired by classical Hough voting, that directly votes for bounding box parameters, and a clustering method specifically tailored to bounding box votes. This goes beyond commonly used center votes, which would not fully exploit the bounding box annotations. On ScanNet test, our weakly supervised model attains leading performance among other weakly supervised approaches (+18 mAP50). Remarkably, it also achieves 97% of the performance of fully supervised models. To prove the practicality of our approach, we show segmentation results on the recently released ARKitScenes dataset which is annotated with 3D bounding boxes only, and obtain, for the first time, compelling 3D instance segmentation results.
Stereo Radiance Fields (SRF): Learning View Synthesis for Sparse Views of Novel Scenes
Apr 14, 2021

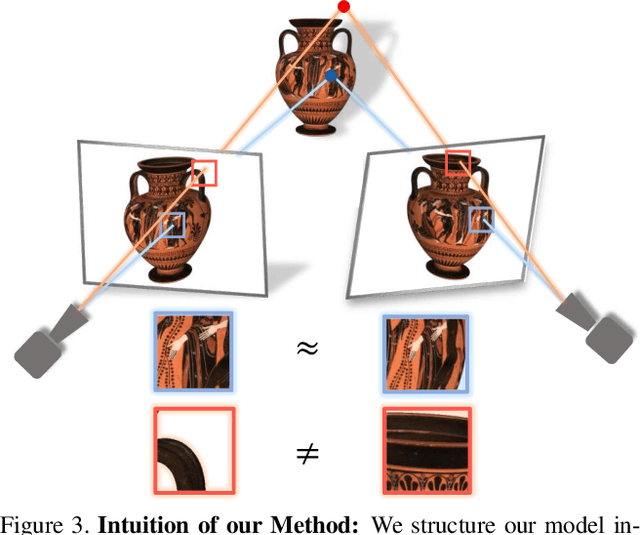
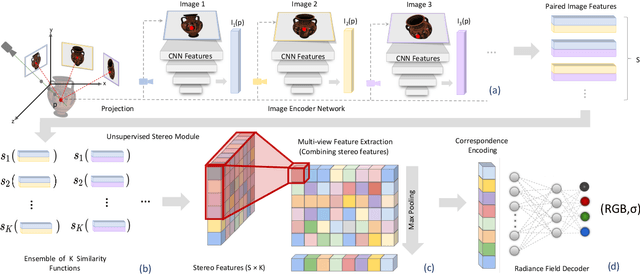
Recent neural view synthesis methods have achieved impressive quality and realism, surpassing classical pipelines which rely on multi-view reconstruction. State-of-the-Art methods, such as NeRF, are designed to learn a single scene with a neural network and require dense multi-view inputs. Testing on a new scene requires re-training from scratch, which takes 2-3 days. In this work, we introduce Stereo Radiance Fields (SRF), a neural view synthesis approach that is trained end-to-end, generalizes to new scenes, and requires only sparse views at test time. The core idea is a neural architecture inspired by classical multi-view stereo methods, which estimates surface points by finding similar image regions in stereo images. In SRF, we predict color and density for each 3D point given an encoding of its stereo correspondence in the input images. The encoding is implicitly learned by an ensemble of pair-wise similarities -- emulating classical stereo. Experiments show that SRF learns structure instead of overfitting on a scene. We train on multiple scenes of the DTU dataset and generalize to new ones without re-training, requiring only 10 sparse and spread-out views as input. We show that 10-15 minutes of fine-tuning further improve the results, achieving significantly sharper, more detailed results than scene-specific models. The code, model, and videos are available at https://virtualhumans.mpi-inf.mpg.de/srf/.
* IEEE Conference on Computer Vision and Pattern Recognition (CVPR) 2021
Neural Unsigned Distance Fields for Implicit Function Learning
Oct 26, 2020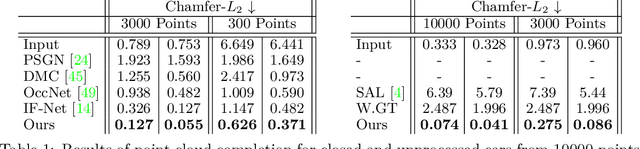
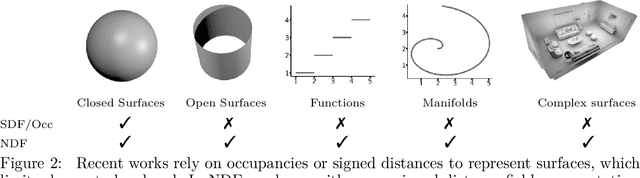
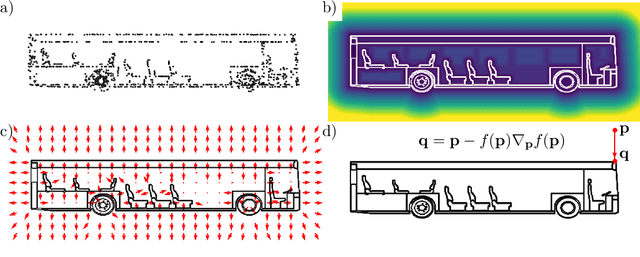

In this work we target a learnable output representation that allows continuous, high resolution outputs of arbitrary shape. Recent works represent 3D surfaces implicitly with a Neural Network, thereby breaking previous barriers in resolution, and ability to represent diverse topologies. However, neural implicit representations are limited to closed surfaces, which divide the space into inside and outside. Many real world objects such as walls of a scene scanned by a sensor, clothing, or a car with inner structures are not closed. This constitutes a significant barrier, in terms of data pre-processing (objects need to be artificially closed creating artifacts), and the ability to output open surfaces. In this work, we propose Neural Distance Fields (NDF), a neural network based model which predicts the unsigned distance field for arbitrary 3D shapes given sparse point clouds. NDF represent surfaces at high resolutions as prior implicit models, but do not require closed surface data, and significantly broaden the class of representable shapes in the output. NDF allow to extract the surface as very dense point clouds and as meshes. We also show that NDF allow for surface normal calculation and can be rendered using a slight modification of sphere tracing. We find NDF can be used for multi-target regression (multiple outputs for one input) with techniques that have been exclusively used for rendering in graphics. Experiments on ShapeNet show that NDF, while simple, is the state-of-the art, and allows to reconstruct shapes with inner structures, such as the chairs inside a bus. Notably, we show that NDF are not restricted to 3D shapes, and can approximate more general open surfaces such as curves, manifolds, and functions. Code is available for research at https://virtualhumans.mpi-inf.mpg.de/ndf/.
* Neural Information Processing Systems (NeurIPS) 2020
SHARP 2020: The 1st Shape Recovery from Partial Textured 3D Scans Challenge Results
Oct 26, 2020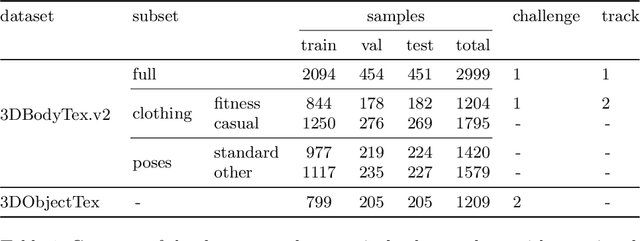


The SHApe Recovery from Partial textured 3D scans challenge, SHARP 2020, is the first edition of a challenge fostering and benchmarking methods for recovering complete textured 3D scans from raw incomplete data. SHARP 2020 is organised as a workshop in conjunction with ECCV 2020. There are two complementary challenges, the first one on 3D human scans, and the second one on generic objects. Challenge 1 is further split into two tracks, focusing, first, on large body and clothing regions, and, second, on fine body details. A novel evaluation metric is proposed to quantify jointly the shape reconstruction, the texture reconstruction and the amount of completed data. Additionally, two unique datasets of 3D scans are proposed, to provide raw ground-truth data for the benchmarks. The datasets are released to the scientific community. Moreover, an accompanying custom library of software routines is also released to the scientific community. It allows for processing 3D scans, generating partial data and performing the evaluation. Results of the competition, analysed in comparison to baselines, show the validity of the proposed evaluation metrics, and highlight the challenging aspects of the task and of the datasets. Details on the SHARP 2020 challenge can be found at https://cvi2.uni.lu/sharp2020/.
Implicit Feature Networks for Texture Completion from Partial 3D Data
Sep 20, 2020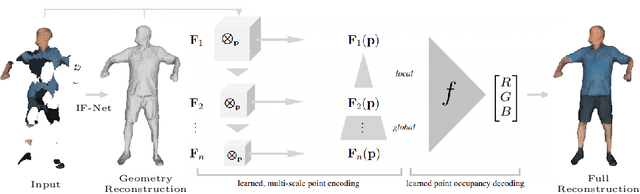
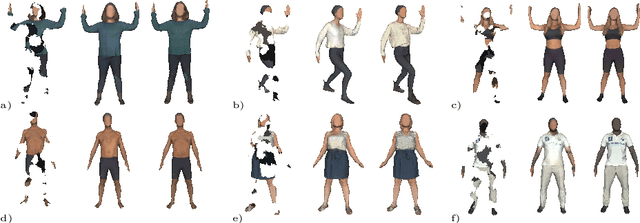

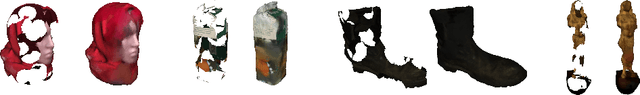
Prior work to infer 3D texture use either texture atlases, which require uv-mappings and hence have discontinuities, or colored voxels, which are memory inefficient and limited in resolution. Recent work, predicts RGB color at every XYZ coordinate forming a texture field, but focus on completing texture given a single 2D image. Instead, we focus on 3D texture and geometry completion from partial and incomplete 3D scans. IF-Nets have recently achieved state-of-the-art results on 3D geometry completion using a multi-scale deep feature encoding, but the outputs lack texture. In this work, we generalize IF-Nets to texture completion from partial textured scans of humans and arbitrary objects. Our key insight is that 3D texture completion benefits from incorporating local and global deep features extracted from both the 3D partial texture and completed geometry. Specifically, given the partial 3D texture and the 3D geometry completed with IF-Nets, our model successfully in-paints the missing texture parts in consistence with the completed geometry. Our model won the SHARP ECCV'20 challenge, achieving highest performance on all challenges.
* SHARP Workshop, European Conference on Computer Vision (ECCV), 2020
Implicit Functions in Feature Space for 3D Shape Reconstruction and Completion
Apr 15, 2020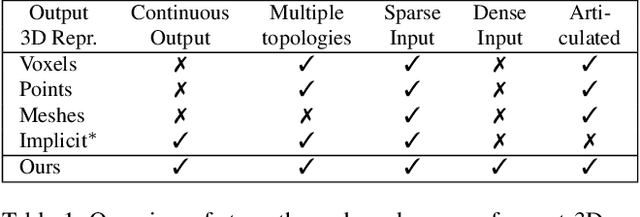
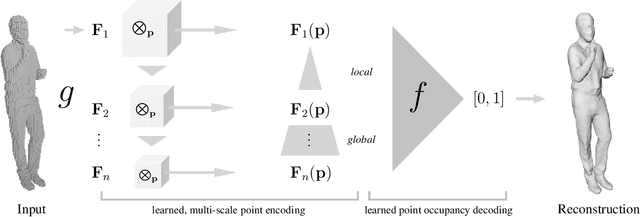
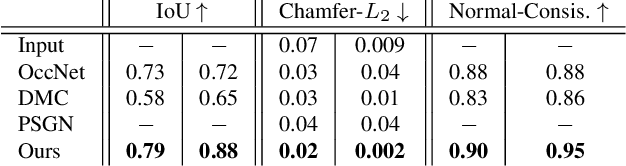
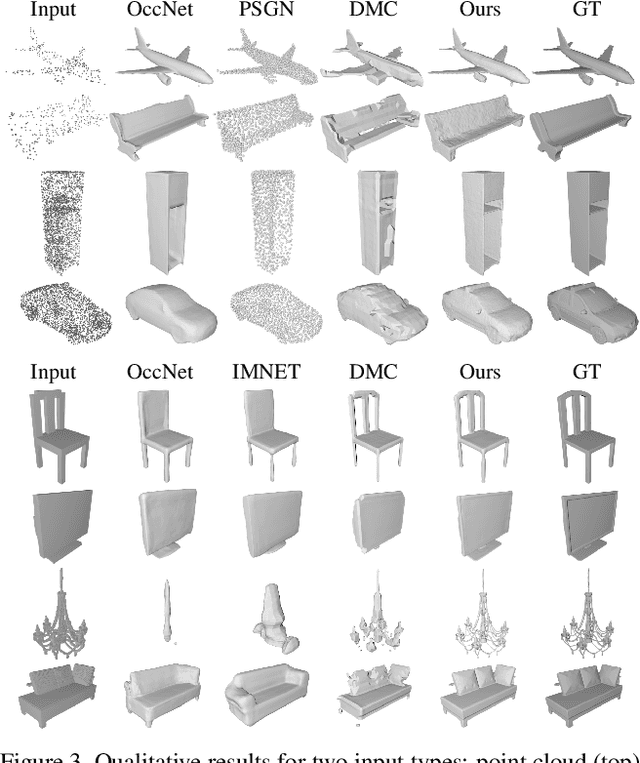
While many works focus on 3D reconstruction from images, in this paper, we focus on 3D shape reconstruction and completion from a variety of 3D inputs, which are deficient in some respect: low and high resolution voxels, sparse and dense point clouds, complete or incomplete. Processing of such 3D inputs is an increasingly important problem as they are the output of 3D scanners, which are becoming more accessible, and are the intermediate output of 3D computer vision algorithms. Recently, learned implicit functions have shown great promise as they produce continuous reconstructions. However, we identified two limitations in reconstruction from 3D inputs: 1) details present in the input data are not retained, and 2) poor reconstruction of articulated humans. To solve this, we propose Implicit Feature Networks (IF-Nets), which deliver continuous outputs, can handle multiple topologies, and complete shapes for missing or sparse input data retaining the nice properties of recent learned implicit functions, but critically they can also retain detail when it is present in the input data, and can reconstruct articulated humans. Our work differs from prior work in two crucial aspects. First, instead of using a single vector to encode a 3D shape, we extract a learnable 3-dimensional multi-scale tensor of deep features, which is aligned with the original Euclidean space embedding the shape. Second, instead of classifying x-y-z point coordinates directly, we classify deep features extracted from the tensor at a continuous query point. We show that this forces our model to make decisions based on global and local shape structure, as opposed to point coordinates, which are arbitrary under Euclidean transformations. Experiments demonstrate that IF-Nets clearly outperform prior work in 3D object reconstruction in ShapeNet, and obtain significantly more accurate 3D human reconstructions.
* {IEEE} Conference on Computer Vision and Pattern Recognition (CVPR)2020