 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnimotion: Unifying 3D Human Motion Synthesis and Understanding
Paper and Code
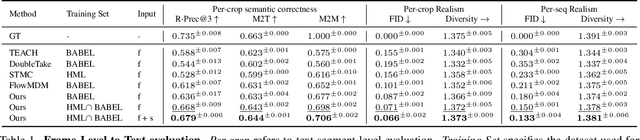
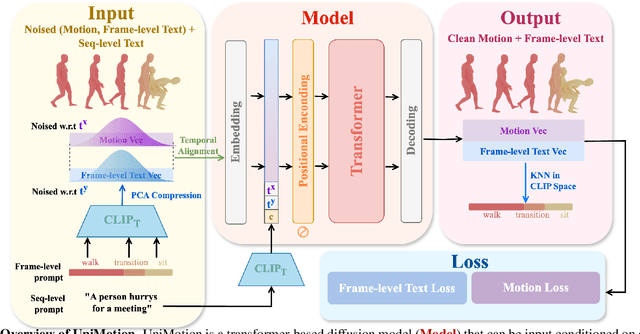
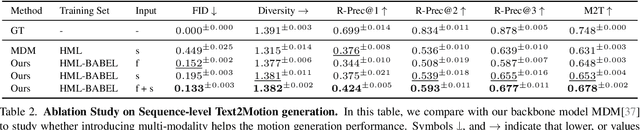
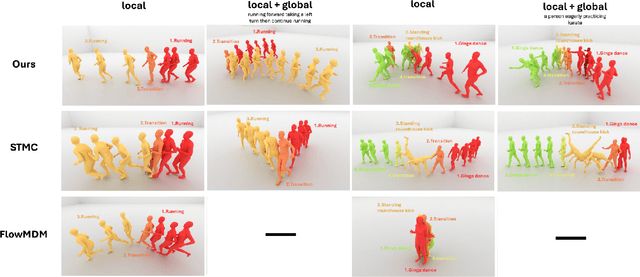
We introduce Unimotion, the first unified multi-task human motion model capable of both flexible motion control and frame-level motion understanding. While existing works control avatar motion with global text conditioning, or with fine-grained per frame scripts, none can do both at once. In addition, none of the existing works can output frame-level text paired with the generated poses. In contrast, Unimotion allows to control motion with global text, or local frame-level text, or both at once, providing more flexible control for users. Importantly, Unimotion is the first model which by design outputs local text paired with the generated poses, allowing users to know what motion happens and when, which is necessary for a wide range of applications. We show Unimotion opens up new applications: 1.) Hierarchical control, allowing users to specify motion at different levels of detail, 2.) Obtaining motion text descriptions for existing MoCap data or YouTube videos 3.) Allowing for editability, generating motion from text, and editing the motion via text edits. Moreover, Unimotion attains state-of-the-art results for the frame-level text-to-motion task on the established HumanML3D dataset. The pre-trained model and code are available available on our project page at https://coral79.github.io/Unimotion/.