 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMoLingo: Motion-Language Alignment for Text-to-Motion Generation
Dec 15, 2025We introduce MoLingo, a text-to-motion (T2M) model that generates realistic, lifelike human motion by denoising in a continuous latent space. Recent works perform latent space diffusion, either on the whole latent at once or auto-regressively over multiple latents. In this paper, we study how to make diffusion on continuous motion latents work best. We focus on two questions: (1) how to build a semantically aligned latent space so diffusion becomes more effective, and (2) how to best inject text conditioning so the motion follows the description closely. We propose a semantic-aligned motion encoder trained with frame-level text labels so that latents with similar text meaning stay close, which makes the latent space more diffusion-friendly. We also compare single-token conditioning with a multi-token cross-attention scheme and find that cross-attention gives better motion realism and text-motion alignment. With semantically aligned latents, auto-regressive generation, and cross-attention text conditioning, our model sets a new state of the art in human motion generation on standard metrics and in a user study. We will release our code and models for further research and downstream usage.
Unimotion: Unifying 3D Human Motion Synthesis and Understanding
Sep 24, 2024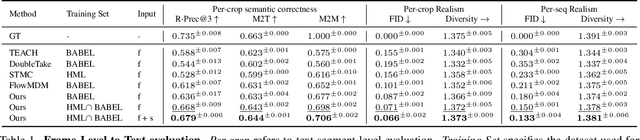
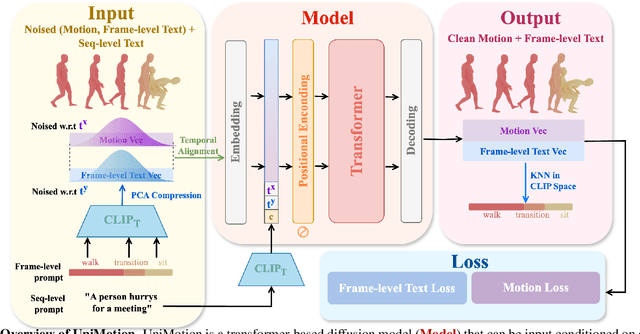
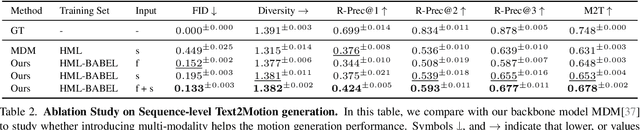
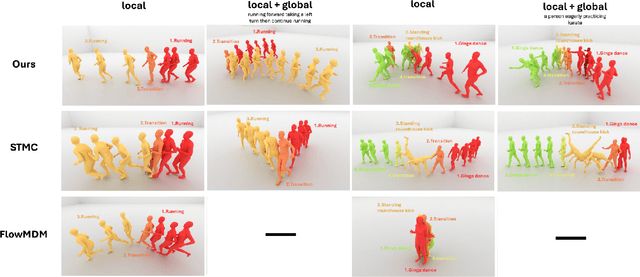
We introduce Unimotion, the first unified multi-task human motion model capable of both flexible motion control and frame-level motion understanding. While existing works control avatar motion with global text conditioning, or with fine-grained per frame scripts, none can do both at once. In addition, none of the existing works can output frame-level text paired with the generated poses. In contrast, Unimotion allows to control motion with global text, or local frame-level text, or both at once, providing more flexible control for users. Importantly, Unimotion is the first model which by design outputs local text paired with the generated poses, allowing users to know what motion happens and when, which is necessary for a wide range of applications. We show Unimotion opens up new applications: 1.) Hierarchical control, allowing users to specify motion at different levels of detail, 2.) Obtaining motion text descriptions for existing MoCap data or YouTube videos 3.) Allowing for editability, generating motion from text, and editing the motion via text edits. Moreover, Unimotion attains state-of-the-art results for the frame-level text-to-motion task on the established HumanML3D dataset. The pre-trained model and code are available available on our project page at https://coral79.github.io/Unimotion/.
NRDF: Neural Riemannian Distance Fields for Learning Articulated Pose Priors
Mar 05, 2024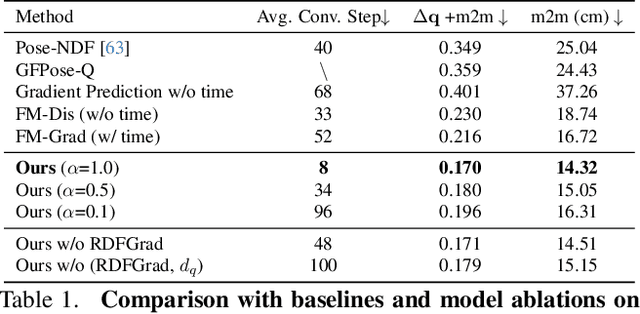
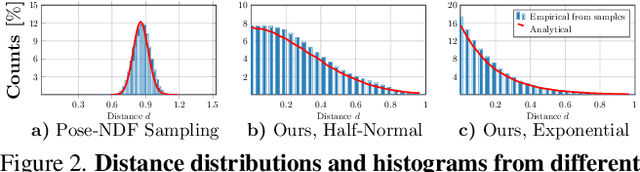
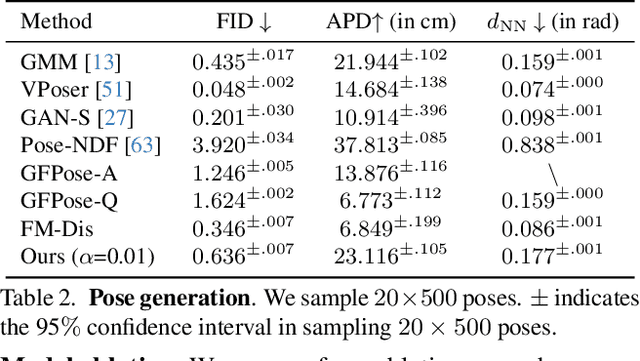
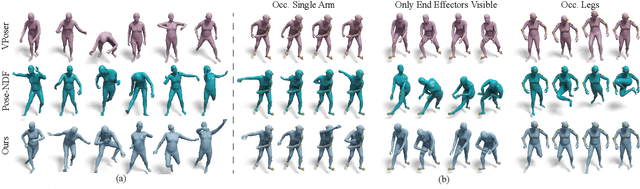
Faithfully modeling the space of articulations is a crucial task that allows recovery and generation of realistic poses, and remains a notorious challenge. To this end, we introduce Neural Riemannian Distance Fields (NRDFs), data-driven priors modeling the space of plausible articulations, represented as the zero-level-set of a neural field in a high-dimensional product-quaternion space. To train NRDFs only on positive examples, we introduce a new sampling algorithm, ensuring that the geodesic distances follow a desired distribution, yielding a principled distance field learning paradigm. We then devise a projection algorithm to map any random pose onto the level-set by an adaptive-step Riemannian optimizer, adhering to the product manifold of joint rotations at all times. NRDFs can compute the Riemannian gradient via backpropagation and by mathematical analogy, are related to Riemannian flow matching, a recent generative model. We conduct a comprehensive evaluation of NRDF against other pose priors in various downstream tasks, i.e., pose generation, image-based pose estimation, and solving inverse kinematics, highlighting NRDF's superior performance. Besides humans, NRDF's versatility extends to hand and animal poses, as it can effectively represent any articulation.
LiDAR-aid Inertial Poser: Large-scale Human Motion Capture by Sparse Inertial and LiDAR Sensors
May 30, 2022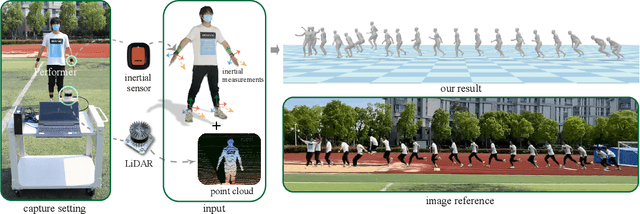

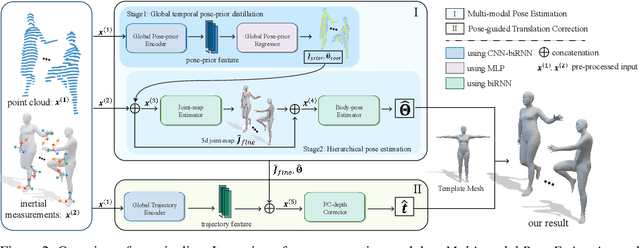
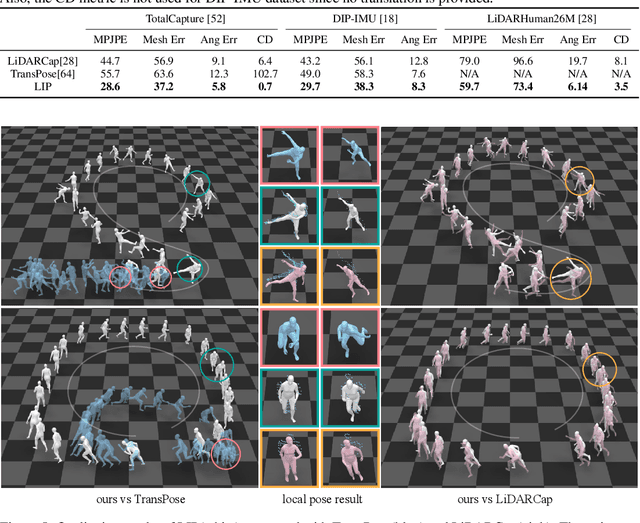
We propose a multi-sensor fusion method for capturing challenging 3D human motions with accurate consecutive local poses and global trajectories in large-scale scenarios, only using a single LiDAR and 4 IMUs. Specifically, to fully utilize the global geometry information captured by LiDAR and local dynamic motions captured by IMUs, we design a two-stage pose estimator in a coarse-to-fine manner, where point clouds provide the coarse body shape and IMU measurements optimize the local actions. Furthermore, considering the translation deviation caused by the view-dependent partial point cloud, we propose a pose-guided translation corrector. It predicts the offset between captured points and the real root locations, which makes the consecutive movements and trajectories more precise and natural. Extensive quantitative and qualitative experiments demonstrate the capability of our approach for compelling motion capture in large-scale scenarios, which outperforms other methods by an obvious margin. We will release our code and captured dataset to stimulate future research.
HybridCap: Inertia-aid Monocular Capture of Challenging Human Motions
Mar 17, 2022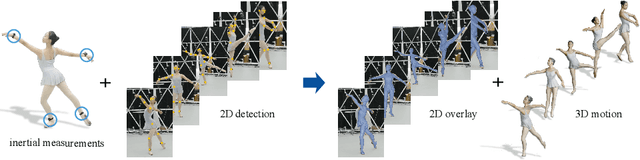

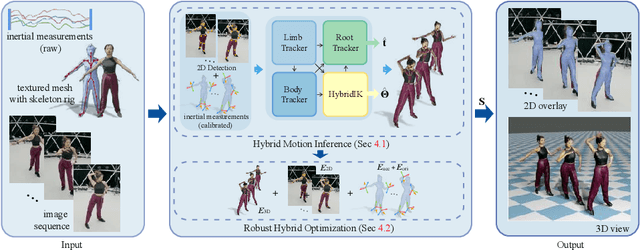
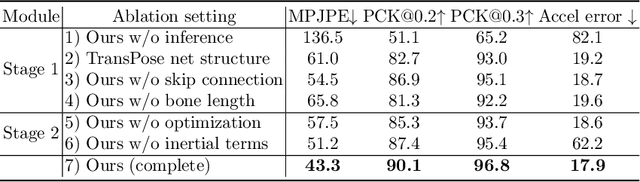
Monocular 3D motion capture (mocap) is beneficial to many applications. The use of a single camera, however, often fails to handle occlusions of different body parts and hence it is limited to capture relatively simple movements. We present a light-weight, hybrid mocap technique called HybridCap that augments the camera with only 4 Inertial Measurement Units (IMUs) in a learning-and-optimization framework. We first employ a weakly-supervised and hierarchical motion inference module based on cooperative Gated Recurrent Unit (GRU) blocks that serve as limb, body and root trackers as well as an inverse kinematics solver. Our network effectively narrows the search space of plausible motions via coarse-to-fine pose estimation and manages to tackle challenging movements with high efficiency. We further develop a hybrid optimization scheme that combines inertial feedback and visual cues to improve tracking accuracy. Extensive experiments on various datasets demonstrate HybridCap can robustly handle challenging movements ranging from fitness actions to Latin dance. It also achieves real-time performance up to 60 fps with state-of-the-art accuracy.
ChallenCap: Monocular 3D Capture of Challenging Human Performances using Multi-Modal References
Mar 29, 2021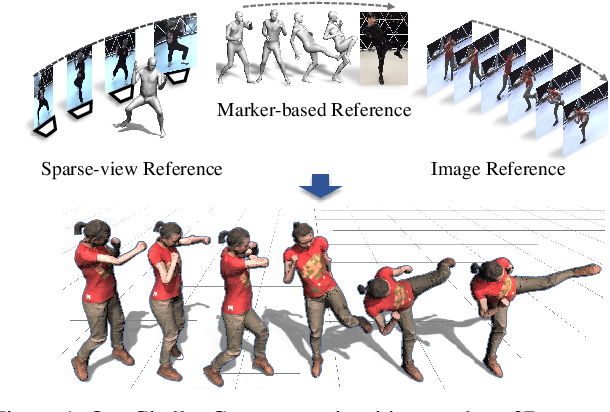
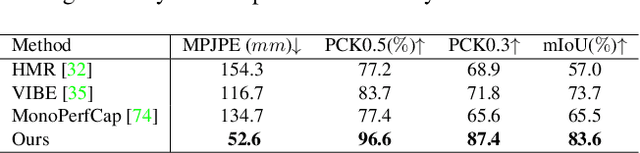
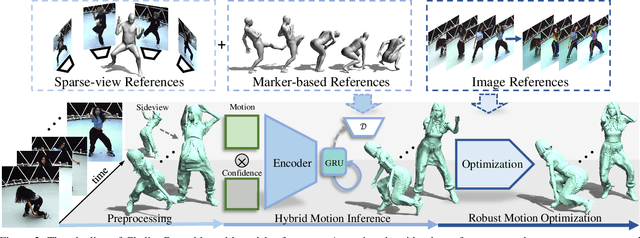

Capturing challenging human motions is critical for numerous applications, but it suffers from complex motion patterns and severe self-occlusion under the monocular setting. In this paper, we propose ChallenCap -- a template-based approach to capture challenging 3D human motions using a single RGB camera in a novel learning-and-optimization framework, with the aid of multi-modal references. We propose a hybrid motion inference stage with a generation network, which utilizes a temporal encoder-decoder to extract the motion details from the pair-wise sparse-view reference, as well as a motion discriminator to utilize the unpaired marker-based references to extract specific challenging motion characteristics in a data-driven manner. We further adopt a robust motion optimization stage to increase the tracking accuracy, by jointly utilizing the learned motion details from the supervised multi-modal references as well as the reliable motion hints from the input image reference. Extensive experiments on our new challenging motion dataset demonstrate the effectiveness and robustness of our approach to capture challenging human motions.