 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnimotion: Unifying 3D Human Motion Synthesis and Understanding
Sep 24, 2024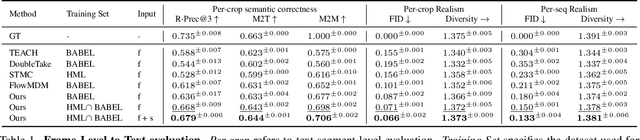
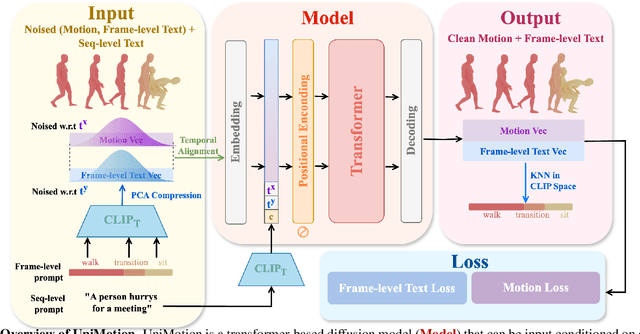
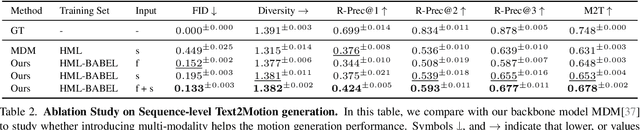
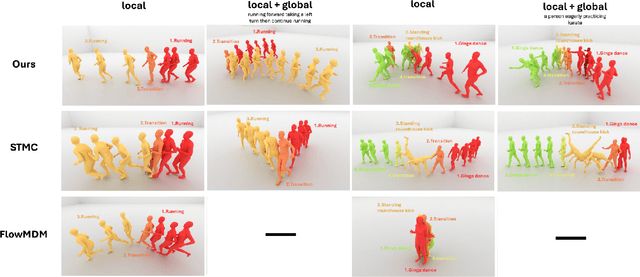
We introduce Unimotion, the first unified multi-task human motion model capable of both flexible motion control and frame-level motion understanding. While existing works control avatar motion with global text conditioning, or with fine-grained per frame scripts, none can do both at once. In addition, none of the existing works can output frame-level text paired with the generated poses. In contrast, Unimotion allows to control motion with global text, or local frame-level text, or both at once, providing more flexible control for users. Importantly, Unimotion is the first model which by design outputs local text paired with the generated poses, allowing users to know what motion happens and when, which is necessary for a wide range of applications. We show Unimotion opens up new applications: 1.) Hierarchical control, allowing users to specify motion at different levels of detail, 2.) Obtaining motion text descriptions for existing MoCap data or YouTube videos 3.) Allowing for editability, generating motion from text, and editing the motion via text edits. Moreover, Unimotion attains state-of-the-art results for the frame-level text-to-motion task on the established HumanML3D dataset. The pre-trained model and code are available available on our project page at https://coral79.github.io/Unimotion/.
SVNR: Spatially-variant Noise Removal with Denoising Diffusion
Jun 28, 2023Denoising diffusion models have recently shown impressive results in generative tasks. By learning powerful priors from huge collections of training images, such models are able to gradually modify complete noise to a clean natural image via a sequence of small denoising steps, seemingly making them well-suited for single image denoising. However, effectively applying denoising diffusion models to removal of realistic noise is more challenging than it may seem, since their formulation is based on additive white Gaussian noise, unlike noise in real-world images. In this work, we present SVNR, a novel formulation of denoising diffusion that assumes a more realistic, spatially-variant noise model. SVNR enables using the noisy input image as the starting point for the denoising diffusion process, in addition to conditioning the process on it. To this end, we adapt the diffusion process to allow each pixel to have its own time embedding, and propose training and inference schemes that support spatially-varying time maps. Our formulation also accounts for the correlation that exists between the condition image and the samples along the modified diffusion process. In our experiments we demonstrate the advantages of our approach over a strong diffusion model baseline, as well as over a state-of-the-art single image denoising method.
SeaThru-NeRF: Neural Radiance Fields in Scattering Media
Apr 16, 2023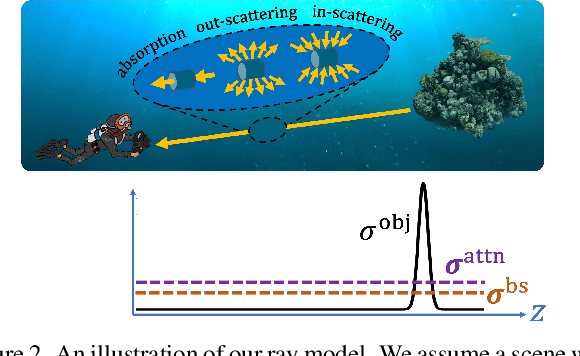

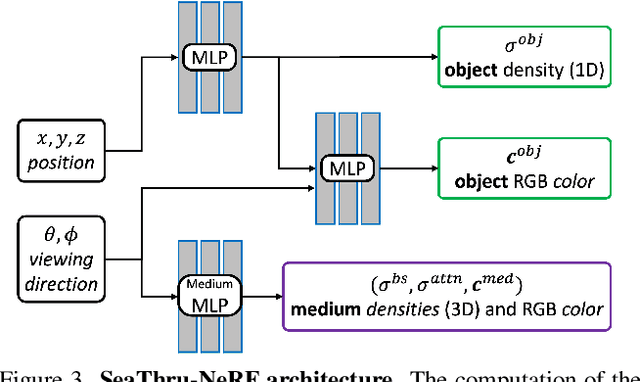

Research on neural radiance fields (NeRFs) for novel view generation is exploding with new models and extensions. However, a question that remains unanswered is what happens in underwater or foggy scenes where the medium strongly influences the appearance of objects. Thus far, NeRF and its variants have ignored these cases. However, since the NeRF framework is based on volumetric rendering, it has inherent capability to account for the medium's effects, once modeled appropriately. We develop a new rendering model for NeRFs in scattering media, which is based on the SeaThru image formation model, and suggest a suitable architecture for learning both scene information and medium parameters. We demonstrate the strength of our method using simulated and real-world scenes, correctly rendering novel photorealistic views underwater. Even more excitingly, we can render clear views of these scenes, removing the medium between the camera and the scene and reconstructing the appearance and depth of far objects, which are severely occluded by the medium. Our code and unique datasets are available on the project's website.
NAN: Noise-Aware NeRFs for Burst-Denoising
Apr 12, 2022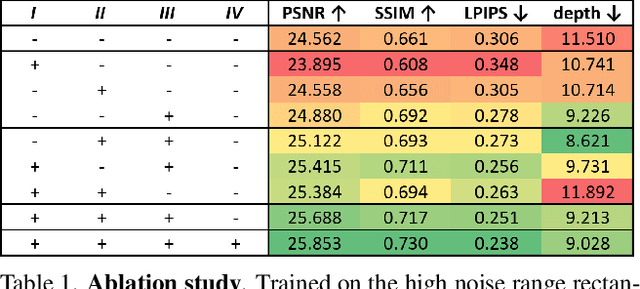
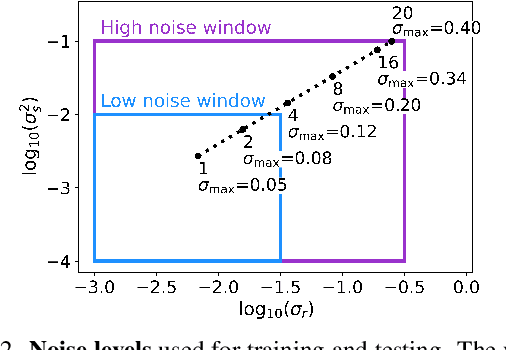
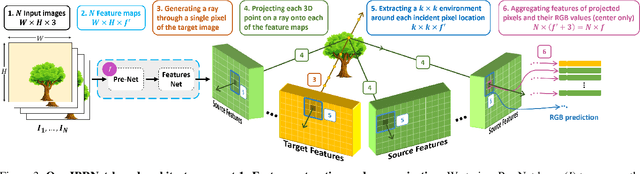
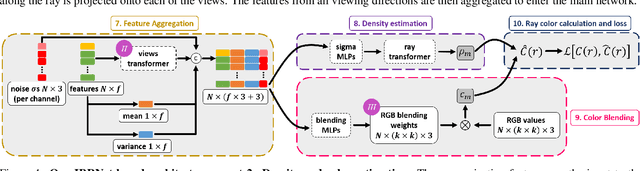
Burst denoising is now more relevant than ever, as computational photography helps overcome sensitivity issues inherent in mobile phones and small cameras. A major challenge in burst-denoising is in coping with pixel misalignment, which was so far handled with rather simplistic assumptions of simple motion, or the ability to align in pre-processing. Such assumptions are not realistic in the presence of large motion and high levels of noise. We show that Neural Radiance Fields (NeRFs), originally suggested for physics-based novel-view rendering, can serve as a powerful framework for burst denoising. NeRFs have an inherent capability of handling noise as they integrate information from multiple images, but they are limited in doing so, mainly since they build on pixel-wise operations which are suitable to ideal imaging conditions. Our approach, termed NAN, leverages inter-view and spatial information in NeRFs to better deal with noise. It achieves state-of-the-art results in burst denoising and is especially successful in coping with large movement and occlusions, under very high levels of noise. With the rapid advances in accelerating NeRFs, it could provide a powerful platform for denoising in challenging environments.
Metalearning Linear Bandits by Prior Update
Jul 12, 2021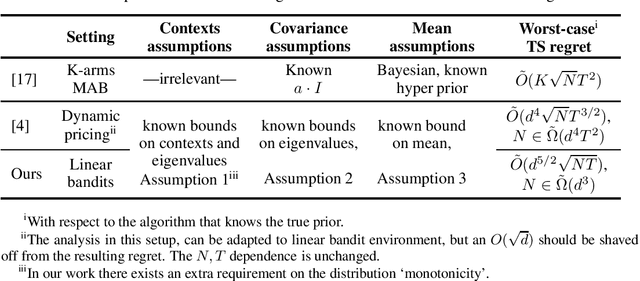
Fully Bayesian approaches to sequential decision-making assume that problem parameters are generated from a known prior, while in practice, such information is often lacking, and needs to be estimated through learning. This problem is exacerbated in decision-making setups with partial information, where using a misspecified prior may lead to poor exploration and inferior performance. In this work we prove, in the context of stochastic linear bandits and Gaussian priors, that as long as the prior estimate is sufficiently close to the true prior, the performance of an algorithm that uses the misspecified prior is close to that of the algorithm that uses the true prior. Next, we address the task of learning the prior through metalearning, where a learner updates its estimate of the prior across multiple task instances in order to improve performance on future tasks. The estimated prior is then updated within each task based on incoming observations, while actions are selected in order to maximize expected reward. In this work we apply this scheme within a linear bandit setting, and provide algorithms and regret bounds, demonstrating its effectiveness, as compared to an algorithm that knows the correct prior. Our results hold for a broad class of algorithms, including, for example, Thompson Sampling and Information Directed Sampling.