 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderwater imaging without color distortions requires RAW capture
Mar 21, 2026Consumer cameras are ubiquitous in aquatic sciences because they are affordable and easy to use, generating vast collections of underwater imagery for ecosystem surveys, monitoring, mapping, and animal behavior studies. Yet when color is the variable of interest, such as in coral-bleaching research, most of these images cannot be used quantitatively if captured in JPEG format. The limitation is not due to JPEG compression itself, but to the in-camera processing that precedes it: as cameras produce these images, built-in algorithms modify colors and contrast not to ensure color accuracy but to produce visually pleasing pictures. These irreversible in-camera operations break the linear relationship between pixel values and scene radiance, making colors impossible to standardize, reproduce, or compare across cameras, locations, or time. This essay explains the scientific costs of this practice and offers pragmatic guidance to prevent irreversible data loss, beginning with the capture and archiving of minimally processed RAW images.
Gaussian Splashing: Direct Volumetric Rendering Underwater
Nov 29, 2024
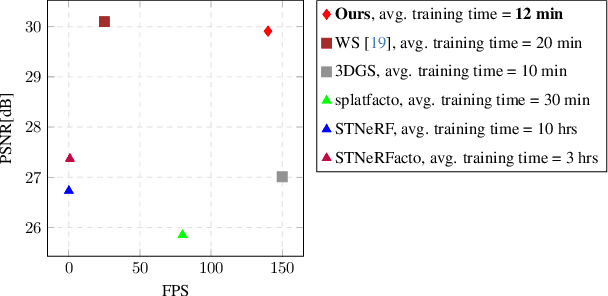

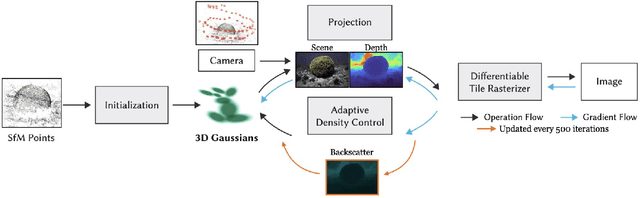
In underwater images, most useful features are occluded by water. The extent of the occlusion depends on imaging geometry and can vary even across a sequence of burst images. As a result, 3D reconstruction methods robust on in-air scenes, like Neural Radiance Field methods (NeRFs) or 3D Gaussian Splatting (3DGS), fail on underwater scenes. While a recent underwater adaptation of NeRFs achieved state-of-the-art results, it is impractically slow: reconstruction takes hours and its rendering rate, in frames per second (FPS), is less than 1. Here, we present a new method that takes only a few minutes for reconstruction and renders novel underwater scenes at 140 FPS. Named Gaussian Splashing, our method unifies the strengths and speed of 3DGS with an image formation model for capturing scattering, introducing innovations in the rendering and depth estimation procedures and in the 3DGS loss function. Despite the complexities of underwater adaptation, our method produces images at unparalleled speeds with superior details. Moreover, it reveals distant scene details with far greater clarity than other methods, dramatically improving reconstructed and rendered images. We demonstrate results on existing datasets and a new dataset we have collected. Additional visual results are available at: https://bgu-cs-vil.github.io/gaussiansplashingUW.github.io/ .
Spectral Sensitivity Estimation Without a Camera
Apr 23, 2023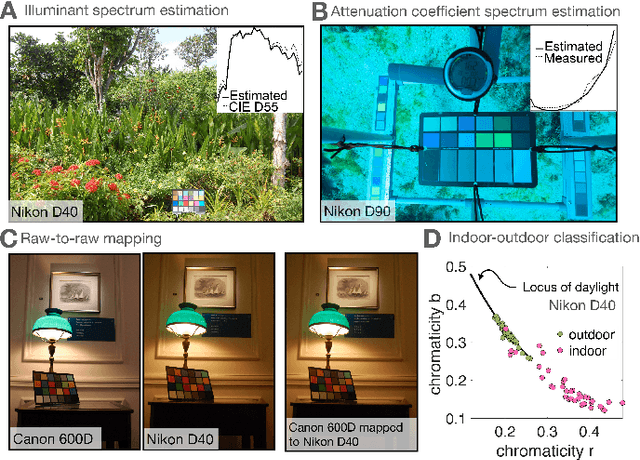
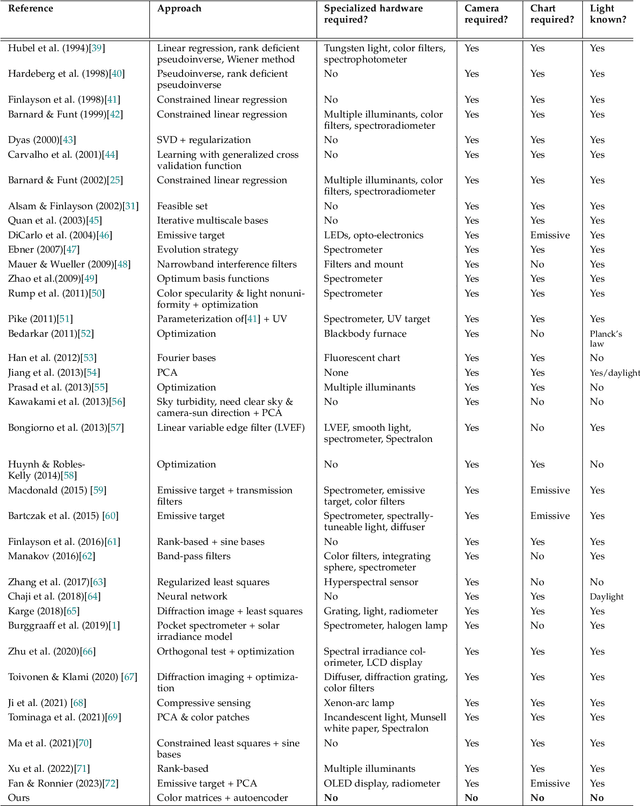
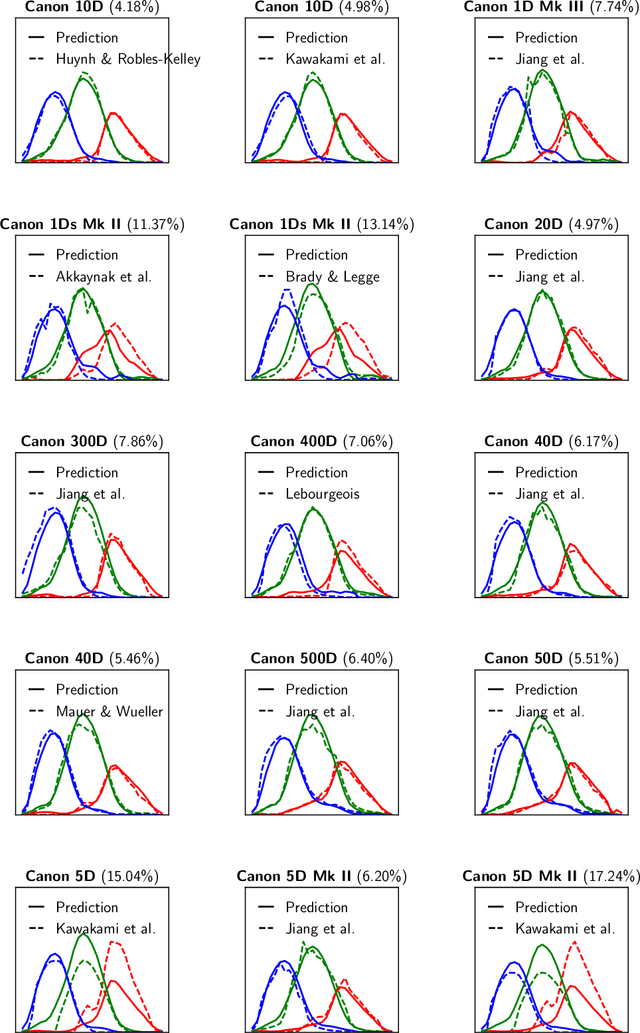
A number of problems in computer vision and related fields would be mitigated if camera spectral sensitivities were known. As consumer cameras are not designed for high-precision visual tasks, manufacturers do not disclose spectral sensitivities. Their estimation requires a costly optical setup, which triggered researchers to come up with numerous indirect methods that aim to lower cost and complexity by using color targets. However, the use of color targets gives rise to new complications that make the estimation more difficult, and consequently, there currently exists no simple, low-cost, robust go-to method for spectral sensitivity estimation. Furthermore, even if not limited by hardware or cost, researchers frequently work with imagery from multiple cameras that they do not have in their possession. To provide a practical solution to this problem, we propose a framework for spectral sensitivity estimation that not only does not require any hardware, but also does not require physical access to the camera itself. Similar to other work, we formulate an optimization problem that minimizes a two-term objective function: a camera-specific term from a system of equations, and a universal term that bounds the solution space. Different than other work, we use publicly available high-quality calibration data to construct both terms. We use the colorimetric mapping matrices provided by the Adobe DNG Converter to formulate the camera-specific system of equations, and constrain the solutions using an autoencoder trained on a database of ground-truth curves. On average, we achieve reconstruction errors as low as those that can arise due to manufacturing imperfections between two copies of the same camera. We provide predicted sensitivities for more than 1,000 cameras that the Adobe DNG Converter currently supports, and discuss which tasks can become trivial when camera responses are available.
SeaThru-NeRF: Neural Radiance Fields in Scattering Media
Apr 16, 2023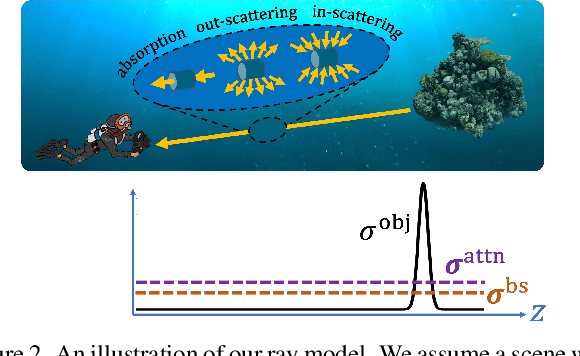

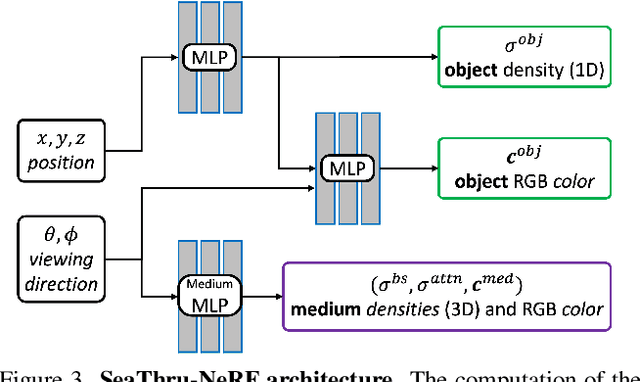

Research on neural radiance fields (NeRFs) for novel view generation is exploding with new models and extensions. However, a question that remains unanswered is what happens in underwater or foggy scenes where the medium strongly influences the appearance of objects. Thus far, NeRF and its variants have ignored these cases. However, since the NeRF framework is based on volumetric rendering, it has inherent capability to account for the medium's effects, once modeled appropriately. We develop a new rendering model for NeRFs in scattering media, which is based on the SeaThru image formation model, and suggest a suitable architecture for learning both scene information and medium parameters. We demonstrate the strength of our method using simulated and real-world scenes, correctly rendering novel photorealistic views underwater. Even more excitingly, we can render clear views of these scenes, removing the medium between the camera and the scene and reconstructing the appearance and depth of far objects, which are severely occluded by the medium. Our code and unique datasets are available on the project's website.