 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGaussian Splashing: Direct Volumetric Rendering Underwater
Nov 29, 2024
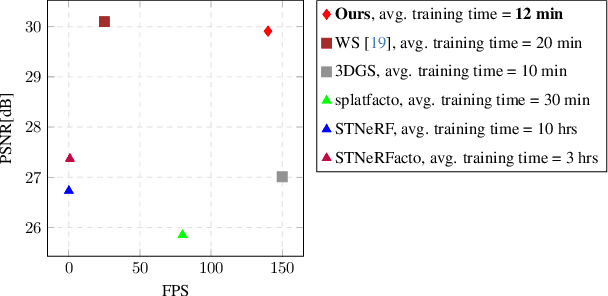

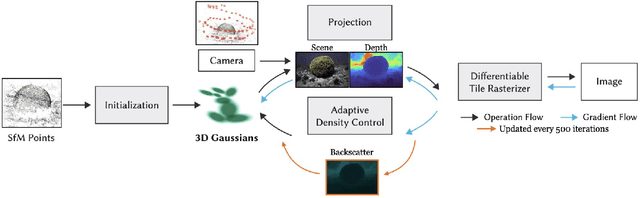
In underwater images, most useful features are occluded by water. The extent of the occlusion depends on imaging geometry and can vary even across a sequence of burst images. As a result, 3D reconstruction methods robust on in-air scenes, like Neural Radiance Field methods (NeRFs) or 3D Gaussian Splatting (3DGS), fail on underwater scenes. While a recent underwater adaptation of NeRFs achieved state-of-the-art results, it is impractically slow: reconstruction takes hours and its rendering rate, in frames per second (FPS), is less than 1. Here, we present a new method that takes only a few minutes for reconstruction and renders novel underwater scenes at 140 FPS. Named Gaussian Splashing, our method unifies the strengths and speed of 3DGS with an image formation model for capturing scattering, introducing innovations in the rendering and depth estimation procedures and in the 3DGS loss function. Despite the complexities of underwater adaptation, our method produces images at unparalleled speeds with superior details. Moreover, it reveals distant scene details with far greater clarity than other methods, dramatically improving reconstructed and rendered images. We demonstrate results on existing datasets and a new dataset we have collected. Additional visual results are available at: https://bgu-cs-vil.github.io/gaussiansplashingUW.github.io/ .
Wavelet Convolutions for Large Receptive Fields
Jul 08, 2024In recent years, there have been attempts to increase the kernel size of Convolutional Neural Nets (CNNs) to mimic the global receptive field of Vision Transformers' (ViTs) self-attention blocks. That approach, however, quickly hit an upper bound and saturated way before achieving a global receptive field. In this work, we demonstrate that by leveraging the Wavelet Transform (WT), it is, in fact, possible to obtain very large receptive fields without suffering from over-parameterization, e.g., for a $k \times k$ receptive field, the number of trainable parameters in the proposed method grows only logarithmically with $k$. The proposed layer, named WTConv, can be used as a drop-in replacement in existing architectures, results in an effective multi-frequency response, and scales gracefully with the size of the receptive field. We demonstrate the effectiveness of the WTConv layer within ConvNeXt and MobileNetV2 architectures for image classification, as well as backbones for downstream tasks, and show it yields additional properties such as robustness to image corruption and an increased response to shapes over textures. Our code is available at https://github.com/BGU-CS-VIL/WTConv.