 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGaussian Splashing: Direct Volumetric Rendering Underwater
Nov 29, 2024
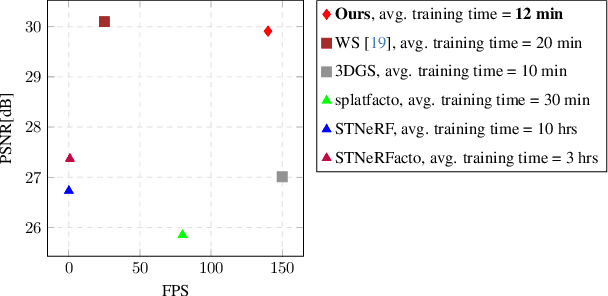

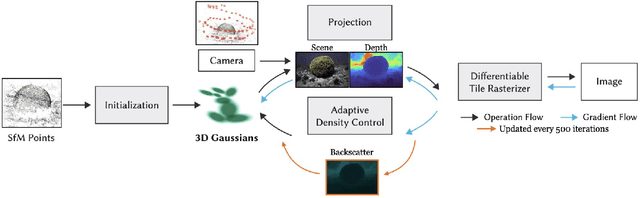
In underwater images, most useful features are occluded by water. The extent of the occlusion depends on imaging geometry and can vary even across a sequence of burst images. As a result, 3D reconstruction methods robust on in-air scenes, like Neural Radiance Field methods (NeRFs) or 3D Gaussian Splatting (3DGS), fail on underwater scenes. While a recent underwater adaptation of NeRFs achieved state-of-the-art results, it is impractically slow: reconstruction takes hours and its rendering rate, in frames per second (FPS), is less than 1. Here, we present a new method that takes only a few minutes for reconstruction and renders novel underwater scenes at 140 FPS. Named Gaussian Splashing, our method unifies the strengths and speed of 3DGS with an image formation model for capturing scattering, introducing innovations in the rendering and depth estimation procedures and in the 3DGS loss function. Despite the complexities of underwater adaptation, our method produces images at unparalleled speeds with superior details. Moreover, it reveals distant scene details with far greater clarity than other methods, dramatically improving reconstructed and rendered images. We demonstrate results on existing datasets and a new dataset we have collected. Additional visual results are available at: https://bgu-cs-vil.github.io/gaussiansplashingUW.github.io/ .
SpaceJAM: a Lightweight and Regularization-free Method for Fast Joint Alignment of Images
Jul 16, 2024



The unsupervised task of Joint Alignment (JA) of images is beset by challenges such as high complexity, geometric distortions, and convergence to poor local or even global optima. Although Vision Transformers (ViT) have recently provided valuable features for JA, they fall short of fully addressing these issues. Consequently, researchers frequently depend on expensive models and numerous regularization terms, resulting in long training times and challenging hyperparameter tuning. We introduce the Spatial Joint Alignment Model (SpaceJAM), a novel approach that addresses the JA task with efficiency and simplicity. SpaceJAM leverages a compact architecture with only 16K trainable parameters and uniquely operates without the need for regularization or atlas maintenance. Evaluations on SPair-71K and CUB datasets demonstrate that SpaceJAM matches the alignment capabilities of existing methods while significantly reducing computational demands and achieving at least a 10x speedup. SpaceJAM sets a new standard for rapid and effective image alignment, making the process more accessible and efficient. Our code is available at: https://bgu-cs-vil.github.io/SpaceJAM/.