 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFastJAM: a Fast Joint Alignment Model for Images
Oct 26, 2025Joint Alignment (JA) of images aims to align a collection of images into a unified coordinate frame, such that semantically-similar features appear at corresponding spatial locations. Most existing approaches often require long training times, large-capacity models, and extensive hyperparameter tuning. We introduce FastJAM, a rapid, graph-based method that drastically reduces the computational complexity of joint alignment tasks. FastJAM leverages pairwise matches computed by an off-the-shelf image matcher, together with a rapid nonparametric clustering, to construct a graph representing intra- and inter-image keypoint relations. A graph neural network propagates and aggregates these correspondences, efficiently predicting per-image homography parameters via image-level pooling. Utilizing an inverse-compositional loss, that eliminates the need for a regularization term over the predicted transformations (and thus also obviates the hyperparameter tuning associated with such terms), FastJAM performs image JA quickly and effectively. Experimental results on several benchmarks demonstrate that FastJAM achieves results better than existing modern JA methods in terms of alignment quality, while reducing computation time from hours or minutes to mere seconds. Our code is available at our project webpage, https://bgu-cs-vil.github.io/FastJAM/
Synchronization of Multiple Videos
Oct 15, 2025Synchronizing videos captured simultaneously from multiple cameras in the same scene is often easy and typically requires only simple time shifts. However, synchronizing videos from different scenes or, more recently, generative AI videos, poses a far more complex challenge due to diverse subjects, backgrounds, and nonlinear temporal misalignment. We propose Temporal Prototype Learning (TPL), a prototype-based framework that constructs a shared, compact 1D representation from high-dimensional embeddings extracted by any of various pretrained models. TPL robustly aligns videos by learning a unified prototype sequence that anchors key action phases, thereby avoiding exhaustive pairwise matching. Our experiments show that TPL improves synchronization accuracy, efficiency, and robustness across diverse datasets, including fine-grained frame retrieval and phase classification tasks. Importantly, TPL is the first approach to mitigate synchronization issues in multiple generative AI videos depicting the same action. Our code and a new multiple video synchronization dataset are available at https://bgu-cs-vil.github.io/TPL/
Improving the Effective Receptive Field of Message-Passing Neural Networks
May 29, 2025Message-Passing Neural Networks (MPNNs) have become a cornerstone for processing and analyzing graph-structured data. However, their effectiveness is often hindered by phenomena such as over-squashing, where long-range dependencies or interactions are inadequately captured and expressed in the MPNN output. This limitation mirrors the challenges of the Effective Receptive Field (ERF) in Convolutional Neural Networks (CNNs), where the theoretical receptive field is underutilized in practice. In this work, we show and theoretically explain the limited ERF problem in MPNNs. Furthermore, inspired by recent advances in ERF augmentation for CNNs, we propose an Interleaved Multiscale Message-Passing Neural Networks (IM-MPNN) architecture to address these problems in MPNNs. Our method incorporates a hierarchical coarsening of the graph, enabling message-passing across multiscale representations and facilitating long-range interactions without excessive depth or parameterization. Through extensive evaluations on benchmarks such as the Long-Range Graph Benchmark (LRGB), we demonstrate substantial improvements over baseline MPNNs in capturing long-range dependencies while maintaining computational efficiency.
TimePoint: Accelerated Time Series Alignment via Self-Supervised Keypoint and Descriptor Learning
May 29, 2025Fast and scalable alignment of time series is a fundamental challenge in many domains. The standard solution, Dynamic Time Warping (DTW), struggles with poor scalability and sensitivity to noise. We introduce TimePoint, a self-supervised method that dramatically accelerates DTW-based alignment while typically improving alignment accuracy by learning keypoints and descriptors from synthetic data. Inspired by 2D keypoint detection but carefully adapted to the unique challenges of 1D signals, TimePoint leverages efficient 1D diffeomorphisms, which effectively model nonlinear time warping, to generate realistic training data. This approach, along with fully convolutional and wavelet convolutional architectures, enables the extraction of informative keypoints and descriptors. Applying DTW to these sparse representations yield major speedups and typically higher alignment accuracy than standard DTW applied to the full signals. TimePoint demonstrates strong generalization to real-world time series when trained solely on synthetic data, and further improves with fine-tuning on real data. Extensive experiments demonstrate that TimePoint consistently achieves faster and more accurate alignments than standard DTW, making it a scalable solution for time-series analysis. Our code is available at https://github.com/BGU-CS-VIL/TimePoint
Consistent Amortized Clustering via Generative Flow Networks
Feb 26, 2025



Neural models for amortized probabilistic clustering yield samples of cluster labels given a set-structured input, while avoiding lengthy Markov chain runs and the need for explicit data likelihoods. Existing methods which label each data point sequentially, like the Neural Clustering Process, often lead to cluster assignments highly dependent on the data order. Alternatively, methods that sequentially create full clusters, do not provide assignment probabilities. In this paper, we introduce GFNCP, a novel framework for amortized clustering. GFNCP is formulated as a Generative Flow Network with a shared energy-based parametrization of policy and reward. We show that the flow matching conditions are equivalent to consistency of the clustering posterior under marginalization, which in turn implies order invariance. GFNCP also outperforms existing methods in clustering performance on both synthetic and real-world data.
Diffeomorphic Temporal Alignment Nets for Time-series Joint Alignment and Averaging
Feb 10, 2025In time-series analysis, nonlinear temporal misalignment remains a pivotal challenge that forestalls even simple averaging. Since its introduction, the Diffeomorphic Temporal Alignment Net (DTAN), which we first introduced (Weber et al., 2019) and further developed in (Weber & Freifeld, 2023), has proven itself as an effective solution for this problem (these conference papers are earlier partial versions of the current manuscript). DTAN predicts and applies diffeomorphic transformations in an input-dependent manner, thus facilitating the joint alignment (JA) and averaging of time-series ensembles in an unsupervised or a weakly-supervised manner. The inherent challenges of the weakly/unsupervised setting, particularly the risk of trivial solutions through excessive signal distortion, are mitigated using either one of two distinct strategies: 1) a regularization term for warps; 2) using the Inverse Consistency Averaging Error (ICAE). The latter is a novel, regularization-free approach which also facilitates the JA of variable-length signals. We also further extend our framework to incorporate multi-task learning (MT-DTAN), enabling simultaneous time-series alignment and classification. Additionally, we conduct a comprehensive evaluation of different backbone architectures, demonstrating their efficacy in time-series alignment tasks. Finally, we showcase the utility of our approach in enabling Principal Component Analysis (PCA) for misaligned time-series data. Extensive experiments across 128 UCR datasets validate the superiority of our approach over contemporary averaging methods, including both traditional and learning-based approaches, marking a significant advancement in the field of time-series analysis.
Gaussian Splashing: Direct Volumetric Rendering Underwater
Nov 29, 2024
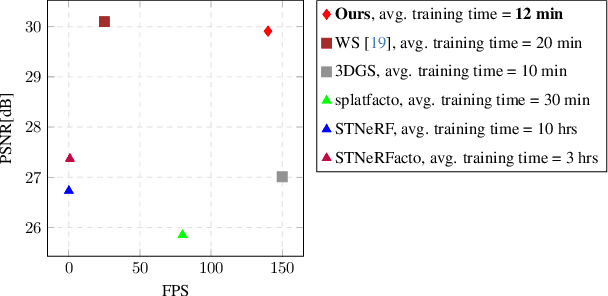

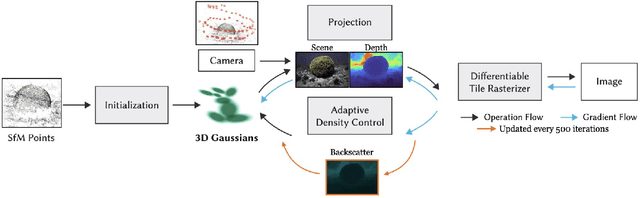
In underwater images, most useful features are occluded by water. The extent of the occlusion depends on imaging geometry and can vary even across a sequence of burst images. As a result, 3D reconstruction methods robust on in-air scenes, like Neural Radiance Field methods (NeRFs) or 3D Gaussian Splatting (3DGS), fail on underwater scenes. While a recent underwater adaptation of NeRFs achieved state-of-the-art results, it is impractically slow: reconstruction takes hours and its rendering rate, in frames per second (FPS), is less than 1. Here, we present a new method that takes only a few minutes for reconstruction and renders novel underwater scenes at 140 FPS. Named Gaussian Splashing, our method unifies the strengths and speed of 3DGS with an image formation model for capturing scattering, introducing innovations in the rendering and depth estimation procedures and in the 3DGS loss function. Despite the complexities of underwater adaptation, our method produces images at unparalleled speeds with superior details. Moreover, it reveals distant scene details with far greater clarity than other methods, dramatically improving reconstructed and rendered images. We demonstrate results on existing datasets and a new dataset we have collected. Additional visual results are available at: https://bgu-cs-vil.github.io/gaussiansplashingUW.github.io/ .
Leveraging Computational Pathology AI for Noninvasive Optical Imaging Analysis Without Retraining
Nov 19, 2024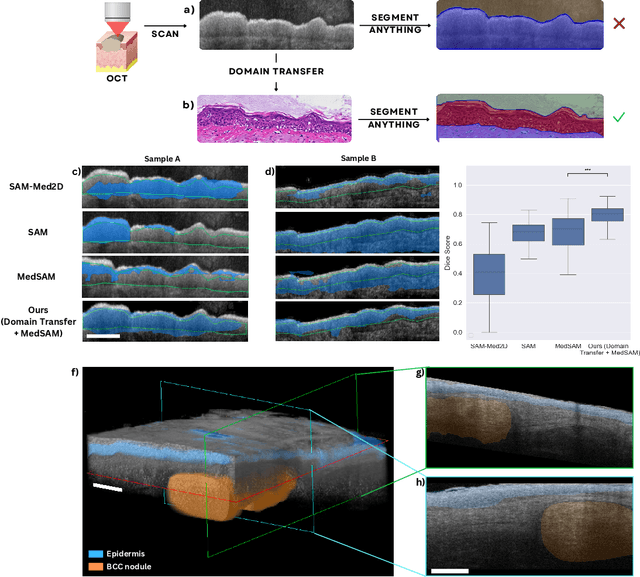
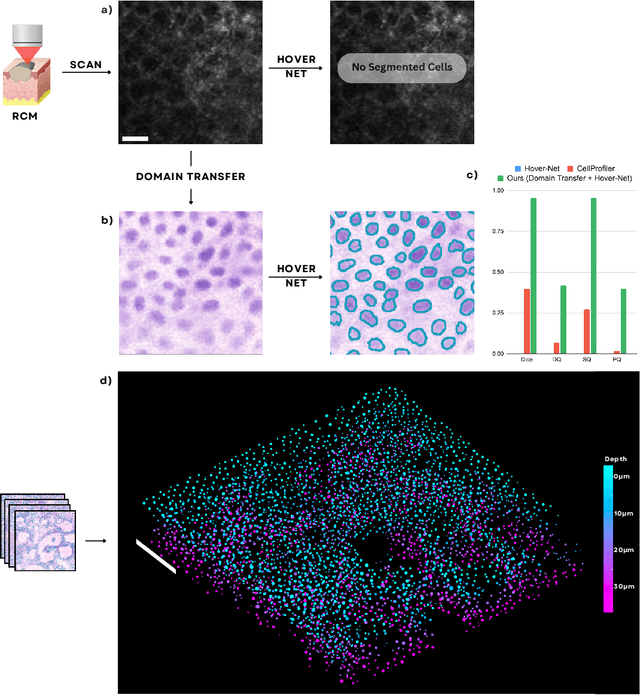
Noninvasive optical imaging modalities can probe patient's tissue in 3D and over time generate gigabytes of clinically relevant data per sample. There is a need for AI models to analyze this data and assist clinical workflow. The lack of expert labelers and the large dataset required (>100,000 images) for model training and tuning are the main hurdles in creating foundation models. In this paper we introduce FoundationShift, a method to apply any AI model from computational pathology without retraining. We show our method is more accurate than state of the art models (SAM, MedSAM, SAM-Med2D, CellProfiler, Hover-Net, PLIP, UNI and ChatGPT), with multiple imaging modalities (OCT and RCM). This is achieved without the need for model retraining or fine-tuning. Applying our method to noninvasive in vivo images could enable physicians to readily incorporate optical imaging modalities into their clinical practice, providing real time tissue analysis and improving patient care.
SpaceJAM: a Lightweight and Regularization-free Method for Fast Joint Alignment of Images
Jul 16, 2024



The unsupervised task of Joint Alignment (JA) of images is beset by challenges such as high complexity, geometric distortions, and convergence to poor local or even global optima. Although Vision Transformers (ViT) have recently provided valuable features for JA, they fall short of fully addressing these issues. Consequently, researchers frequently depend on expensive models and numerous regularization terms, resulting in long training times and challenging hyperparameter tuning. We introduce the Spatial Joint Alignment Model (SpaceJAM), a novel approach that addresses the JA task with efficiency and simplicity. SpaceJAM leverages a compact architecture with only 16K trainable parameters and uniquely operates without the need for regularization or atlas maintenance. Evaluations on SPair-71K and CUB datasets demonstrate that SpaceJAM matches the alignment capabilities of existing methods while significantly reducing computational demands and achieving at least a 10x speedup. SpaceJAM sets a new standard for rapid and effective image alignment, making the process more accessible and efficient. Our code is available at: https://bgu-cs-vil.github.io/SpaceJAM/.
Trainable Highly-expressive Activation Functions
Jul 11, 2024



Nonlinear activation functions are pivotal to the success of deep neural nets, and choosing the appropriate activation function can significantly affect their performance. Most networks use fixed activation functions (e.g., ReLU, GELU, etc.), and this choice might limit their expressiveness. Furthermore, different layers may benefit from diverse activation functions. Consequently, there has been a growing interest in trainable activation functions. In this paper, we introduce DiTAC, a trainable highly-expressive activation function based on an efficient diffeomorphic transformation (called CPAB). Despite introducing only a negligible number of trainable parameters, DiTAC enhances model expressiveness and performance, often yielding substantial improvements. It also outperforms existing activation functions (regardless whether the latter are fixed or trainable) in tasks such as semantic segmentation, image generation, regression problems, and image classification. Our code is available at https://github.com/BGU-CS-VIL/DiTAC.