 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConsistent Amortized Clustering via Generative Flow Networks
Feb 26, 2025



Neural models for amortized probabilistic clustering yield samples of cluster labels given a set-structured input, while avoiding lengthy Markov chain runs and the need for explicit data likelihoods. Existing methods which label each data point sequentially, like the Neural Clustering Process, often lead to cluster assignments highly dependent on the data order. Alternatively, methods that sequentially create full clusters, do not provide assignment probabilities. In this paper, we introduce GFNCP, a novel framework for amortized clustering. GFNCP is formulated as a Generative Flow Network with a shared energy-based parametrization of policy and reward. We show that the flow matching conditions are equivalent to consistency of the clustering posterior under marginalization, which in turn implies order invariance. GFNCP also outperforms existing methods in clustering performance on both synthetic and real-world data.
von Mises Quasi-Processes for Bayesian Circular Regression
Jun 19, 2024The need for regression models to predict circular values arises in many scientific fields. In this work we explore a family of expressive and interpretable distributions over circle-valued random functions related to Gaussian processes targeting two Euclidean dimensions conditioned on the unit circle. The resulting probability model has connections with continuous spin models in statistical physics. Moreover, its density is very simple and has maximum-entropy, unlike previous Gaussian process-based approaches, which use wrapping or radial marginalization. For posterior inference, we introduce a new Stratonovich-like augmentation that lends itself to fast Markov Chain Monte Carlo sampling. We argue that transductive learning in these models favors a Bayesian approach to the parameters. We present experiments applying this model to the prediction of (i) wind directions and (ii) the percentage of the running gait cycle as a function of joint angles.
Marginalizable Density Models
Jun 08, 2021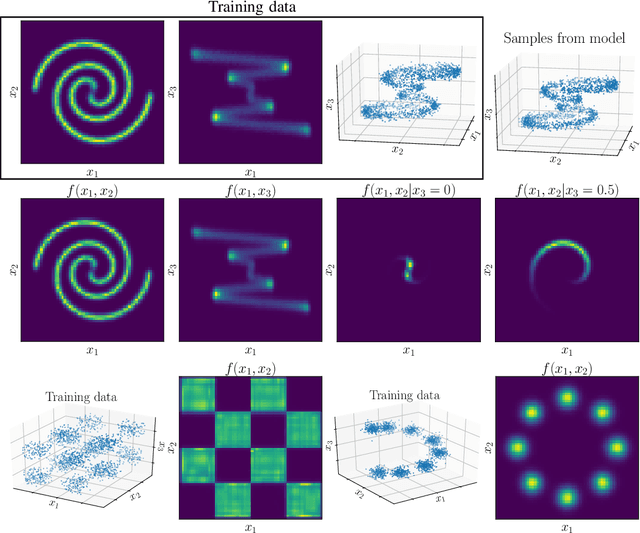

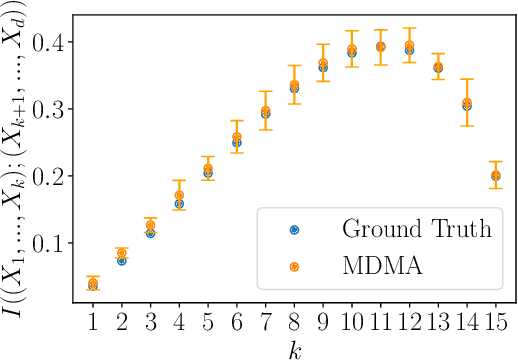

Probability density models based on deep networks have achieved remarkable success in modeling complex high-dimensional datasets. However, unlike kernel density estimators, modern neural models do not yield marginals or conditionals in closed form, as these quantities require the evaluation of seldom tractable integrals. In this work, we present the Marginalizable Density Model Approximator (MDMA), a novel deep network architecture which provides closed form expressions for the probabilities, marginals and conditionals of any subset of the variables. The MDMA learns deep scalar representations for each individual variable and combines them via learned hierarchical tensor decompositions into a tractable yet expressive CDF, from which marginals and conditional densities are easily obtained. We illustrate the advantage of exact marginalizability in several tasks that are out of reach of previous deep network-based density estimation models, such as estimating mutual information between arbitrary subsets of variables, inferring causality by testing for conditional independence, and inference with missing data without the need for data imputation, outperforming state-of-the-art models on these tasks. The model also allows for parallelized sampling with only a logarithmic dependence of the time complexity on the number of variables.
Attentive Clustering Processes
Oct 29, 2020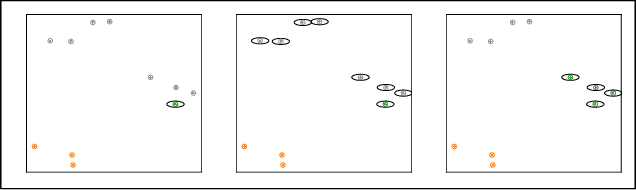
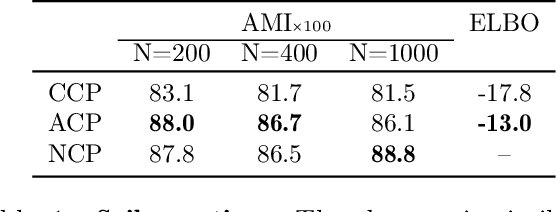
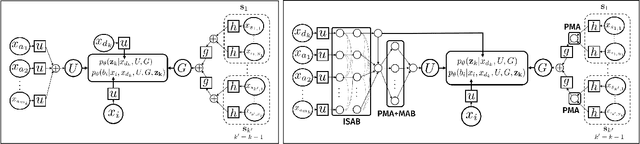
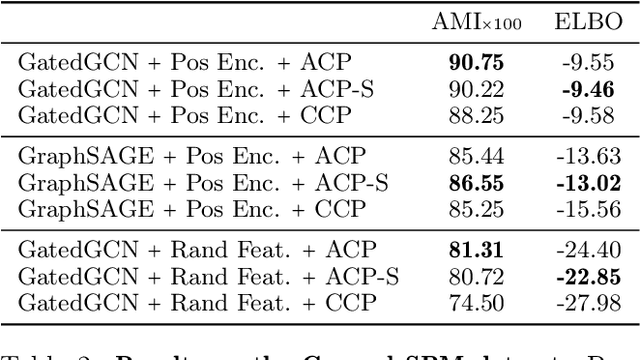
Amortized approaches to clustering have recently received renewed attention thanks to novel objective functions that exploit the expressiveness of deep learning models. In this work we revisit a recent proposal for fast amortized probabilistic clustering, the Clusterwise Clustering Process (CCP), which yields samples from the posterior distribution of cluster labels for sets of arbitrary size using only O(K) forward network evaluations, where K is an arbitrary number of clusters. While adequate in simple datasets, we show that the model can severely underfit complex datasets, and hypothesize that this limitation can be traced back to the implicit assumption that the probability of a point joining a cluster is equally sensitive to all the points available to join the same cluster. We propose an improved model, the Attentive Clustering Process (ACP), that selectively pays more attention to relevant points while preserving the invariance properties of the generative model. We illustrate the advantages of the new model in applications to spike-sorting in multi-electrode arrays and community discovery in networks. The latter case combines the ACP model with graph convolutional networks, and to our knowledge is the first deep learning model that handles an arbitrary number of communities.
Discrete Neural Processes
Dec 28, 2018


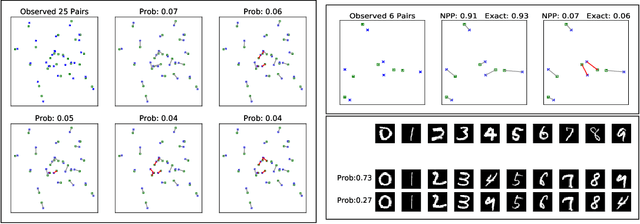
Many data generating processes involve latent random variables over discrete combinatorial spaces whose size grows factorially with the dataset. In these settings, existing posterior inference methods can be inaccurate and/or very slow. In this work we develop methods for efficient amortized approximate Bayesian inference over discrete combinatorial spaces, with applications to random permutations, probabilistic clustering (such as Dirichlet process mixture models) and random communities (such as stochastic block models). The approach is based on mapping distributed, symmetry-invariant representations of discrete arrangements into conditional probabilities. The resulting algorithms parallelize easily, yield iid samples from the approximate posteriors, and can easily be applied to both conjugate and non-conjugate models, as training only requires samples from the generative model.
Amortized Bayesian inference for clustering models
Nov 24, 2018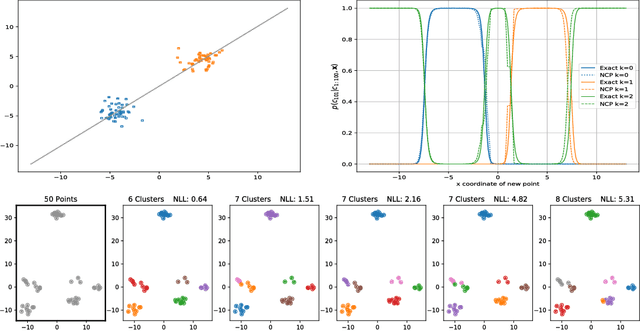

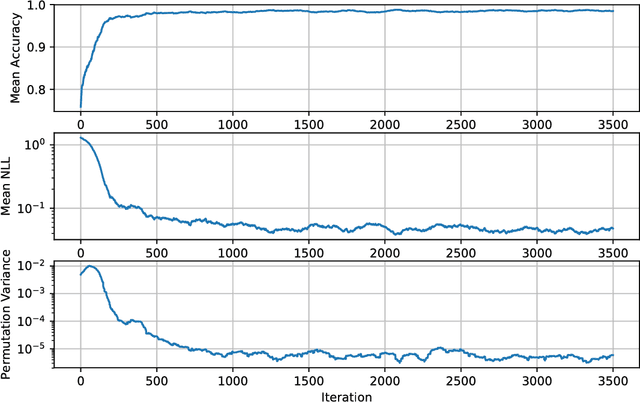
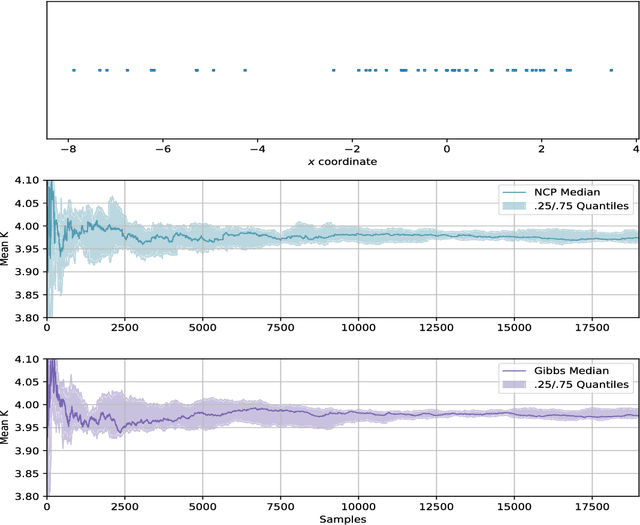
We develop methods for efficient amortized approximate Bayesian inference over posterior distributions of probabilistic clustering models, such as Dirichlet process mixture models. The approach is based on mapping distributed, symmetry-invariant representations of cluster arrangements into conditional probabilities. The method parallelizes easily, yields iid samples from the approximate posterior of cluster assignments with the same computational cost of a single Gibbs sampler sweep, and can easily be applied to both conjugate and non-conjugate models, as training only requires samples from the generative model.
Binary Bouncy Particle Sampler
Nov 02, 2017
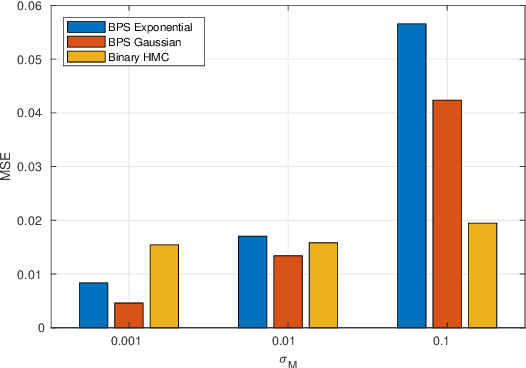
The Bouncy Particle Sampler is a novel rejection-free non-reversible sampler for differentiable probability distributions over continuous variables. We generalize the algorithm to piecewise differentiable distributions and apply it to generic binary distributions using a piecewise differentiable augmentation. We illustrate the new algorithm in a binary Markov Random Field example, and compare it to binary Hamiltonian Monte Carlo. Our results suggest that binary BPS samplers are better for easy to mix distributions.
Stochastic Bouncy Particle Sampler
Jun 14, 2017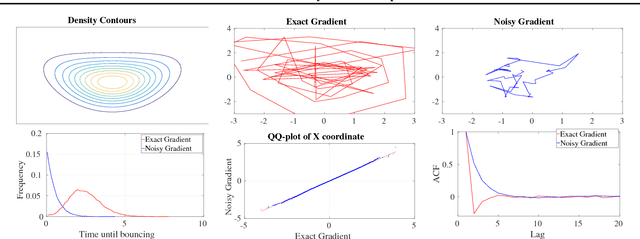
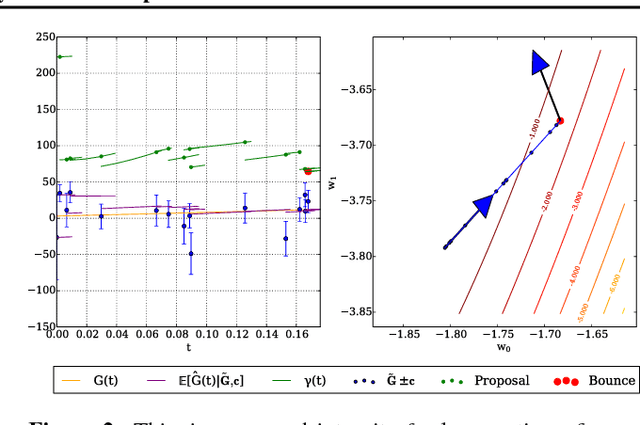
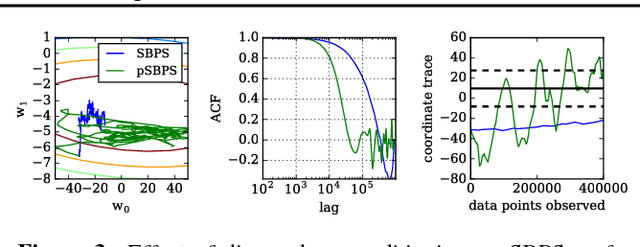
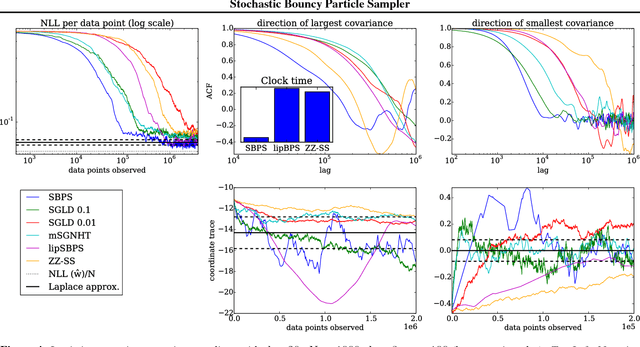
We introduce a novel stochastic version of the non-reversible, rejection-free Bouncy Particle Sampler (BPS), a Markov process whose sample trajectories are piecewise linear. The algorithm is based on simulating first arrival times in a doubly stochastic Poisson process using the thinning method, and allows efficient sampling of Bayesian posteriors in big datasets. We prove that in the BPS no bias is introduced by noisy evaluations of the log-likelihood gradient. On the other hand, we argue that efficiency considerations favor a small, controllable bias in the construction of the thinning proposals, in exchange for faster mixing. We introduce a simple regression-based proposal intensity for the thinning method that controls this trade-off. We illustrate the algorithm in several examples in which it outperforms both unbiased, but slowly mixing stochastic versions of BPS, as well as biased stochastic gradient-based samplers.
Taming the Noise in Reinforcement Learning via Soft Updates
Mar 30, 2017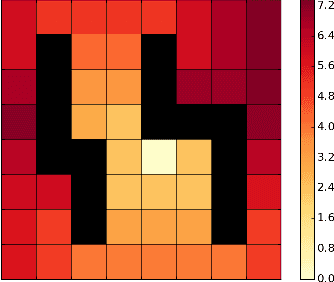
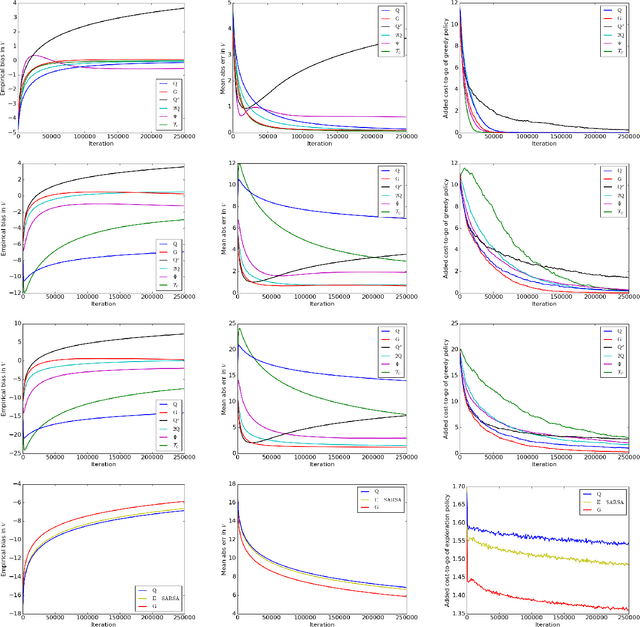
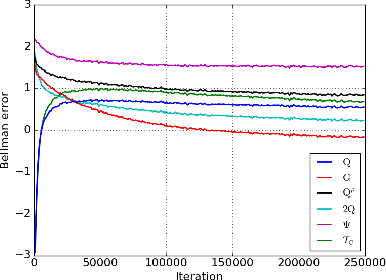
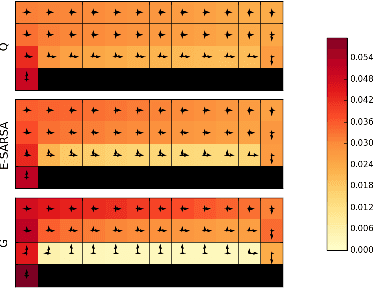
Model-free reinforcement learning algorithms, such as Q-learning, perform poorly in the early stages of learning in noisy environments, because much effort is spent unlearning biased estimates of the state-action value function. The bias results from selecting, among several noisy estimates, the apparent optimum, which may actually be suboptimal. We propose G-learning, a new off-policy learning algorithm that regularizes the value estimates by penalizing deterministic policies in the beginning of the learning process. We show that this method reduces the bias of the value-function estimation, leading to faster convergence to the optimal value and the optimal policy. Moreover, G-learning enables the natural incorporation of prior domain knowledge, when available. The stochastic nature of G-learning also makes it avoid some exploration costs, a property usually attributed only to on-policy algorithms. We illustrate these ideas in several examples, where G-learning results in significant improvements of the convergence rate and the cost of the learning process.
Partition Functions from Rao-Blackwellized Tempered Sampling
May 25, 2016



Partition functions of probability distributions are important quantities for model evaluation and comparisons. We present a new method to compute partition functions of complex and multimodal distributions. Such distributions are often sampled using simulated tempering, which augments the target space with an auxiliary inverse temperature variable. Our method exploits the multinomial probability law of the inverse temperatures, and provides estimates of the partition function in terms of a simple quotient of Rao-Blackwellized marginal inverse temperature probability estimates, which are updated while sampling. We show that the method has interesting connections with several alternative popular methods, and offers some significant advantages. In particular, we empirically find that the new method provides more accurate estimates than Annealed Importance Sampling when calculating partition functions of large Restricted Boltzmann Machines (RBM); moreover, the method is sufficiently accurate to track training and validation log-likelihoods during learning of RBMs, at minimal computational cost.