 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNoise-Response Calibration: A Causal Intervention Protocol for LLM-Judges
Mar 17, 2026Large language models (LLMs) are increasingly used as automated judges and synthetic labelers, especially in low-label settings. Yet these systems are stochastic and often overconfident, which makes deployment decisions difficult when external ground truth is limited. We propose a practical calibration protocol based on controlled input interventions: if noise severity increases, task performance should exhibit a statistically significant deterioration trend. We operationalize this with a slope-based hypothesis test over repeated trials, using signal-to-noise-ratio (SNR) perturbations for tabular data and lexical perturbations for text data. Across UCI tabular benchmarks and four text classification datasets, we find clear modality-dependent behavior. Our results reveal a modality gap: while text-based judges degrade predictably, the majority of tabular datasets show a lack of statistically significant performance deterioration even under significant signal-to-noise reduction. Interestingly we find that model performance is lower on datasets that are insensitive to noise interventions. We present a reproducible methodology and reporting protocol for robust LLM-judge calibration under distribution shift.
Fast Sampling for Flows and Diffusions with Lazy and Point Mass Stochastic Interpolants
Feb 03, 2026Stochastic interpolants unify flows and diffusions, popular generative modeling frameworks. A primary hyperparameter in these methods is the interpolation schedule that determines how to bridge a standard Gaussian base measure to an arbitrary target measure. We prove how to convert a sample path of a stochastic differential equation (SDE) with arbitrary diffusion coefficient under any schedule into the unique sample path under another arbitrary schedule and diffusion coefficient. We then extend the stochastic interpolant framework to admit a larger class of point mass schedules in which the Gaussian base measure collapses to a point mass measure. Under the assumption of Gaussian data, we identify lazy schedule families that make the drift identically zero and show that with deterministic sampling one gets a variance-preserving schedule commonly used in diffusion models, whereas with statistically optimal SDE sampling one gets our point mass schedule. Finally, to demonstrate the usefulness of our theoretical results on realistic highly non-Gaussian data, we apply our lazy schedule conversion to a state-of-the-art pretrained flow model and show that this allows for generating images in fewer steps without retraining the model.
Supervised Guidance Training for Infinite-Dimensional Diffusion Models
Jan 28, 2026Score-based diffusion models have recently been extended to infinite-dimensional function spaces, with uses such as inverse problems arising from partial differential equations. In the Bayesian formulation of inverse problems, the aim is to sample from a posterior distribution over functions obtained by conditioning a prior on noisy observations. While diffusion models provide expressive priors in function space, the theory of conditioning them to sample from the posterior remains open. We address this, assuming that either the prior lies in the Cameron-Martin space, or is absolutely continuous with respect to a Gaussian measure. We prove that the models can be conditioned using an infinite-dimensional extension of Doob's $h$-transform, and that the conditional score decomposes into an unconditional score and a guidance term. As the guidance term is intractable, we propose a simulation-free score matching objective (called Supervised Guidance Training) enabling efficient and stable posterior sampling. We illustrate the theory with numerical examples on Bayesian inverse problems in function spaces. In summary, our work offers the first function-space method for fine-tuning trained diffusion models to accurately sample from a posterior.
Zero-shot protein stability prediction by inverse folding models: a free energy interpretation
Jun 05, 2025Inverse folding models have proven to be highly effective zero-shot predictors of protein stability. Despite this success, the link between the amino acid preferences of an inverse folding model and the free-energy considerations underlying thermodynamic stability remains incompletely understood. A better understanding would be of interest not only from a theoretical perspective, but also potentially provide the basis for stronger zero-shot stability prediction. In this paper, we take steps to clarify the free-energy foundations of inverse folding models. Our derivation reveals the standard practice of likelihood ratios as a simplistic approximation and suggests several paths towards better estimates of the relative stability. We empirically assess these approaches and demonstrate that considerable gains in zero-shot performance can be achieved with fairly simple means.
Exploring bidirectional bounds for minimax-training of Energy-based models
Jun 05, 2025Energy-based models (EBMs) estimate unnormalized densities in an elegant framework, but they are generally difficult to train. Recent work has linked EBMs to generative adversarial networks, by noting that they can be trained through a minimax game using a variational lower bound. To avoid the instabilities caused by minimizing a lower bound, we propose to instead work with bidirectional bounds, meaning that we maximize a lower bound and minimize an upper bound when training the EBM. We investigate four different bounds on the log-likelihood derived from different perspectives. We derive lower bounds based on the singular values of the generator Jacobian and on mutual information. To upper bound the negative log-likelihood, we consider a gradient penalty-like bound, as well as one based on diffusion processes. In all cases, we provide algorithms for evaluating the bounds. We compare the different bounds to investigate, the pros and cons of the different approaches. Finally, we demonstrate that the use of bidirectional bounds stabilizes EBM training and yields high-quality density estimation and sample generation.
* accepted to IJCV
Hyper-Transforming Latent Diffusion Models
Apr 24, 2025We introduce a novel generative framework for functions by integrating Implicit Neural Representations (INRs) and Transformer-based hypernetworks into latent variable models. Unlike prior approaches that rely on MLP-based hypernetworks with scalability limitations, our method employs a Transformer-based decoder to generate INR parameters from latent variables, addressing both representation capacity and computational efficiency. Our framework extends latent diffusion models (LDMs) to INR generation by replacing standard decoders with a Transformer-based hypernetwork, which can be trained either from scratch or via hyper-transforming-a strategy that fine-tunes only the decoder while freezing the pre-trained latent space. This enables efficient adaptation of existing generative models to INR-based representations without requiring full retraining.
Learning Energy-Based Models by Self-normalising the Likelihood
Mar 10, 2025Training an energy-based model (EBM) with maximum likelihood is challenging due to the intractable normalisation constant. Traditional methods rely on expensive Markov chain Monte Carlo (MCMC) sampling to estimate the gradient of logartihm of the normalisation constant. We propose a novel objective called self-normalised log-likelihood (SNL) that introduces a single additional learnable parameter representing the normalisation constant compared to the regular log-likelihood. SNL is a lower bound of the log-likelihood, and its optimum corresponds to both the maximum likelihood estimate of the model parameters and the normalisation constant. We show that the SNL objective is concave in the model parameters for exponential family distributions. Unlike the regular log-likelihood, the SNL can be directly optimised using stochastic gradient techniques by sampling from a crude proposal distribution. We validate the effectiveness of our proposed method on various density estimation tasks as well as EBMs for regression. Our results show that the proposed method, while simpler to implement and tune, outperforms existing techniques.
Debiasing Guidance for Discrete Diffusion with Sequential Monte Carlo
Feb 10, 2025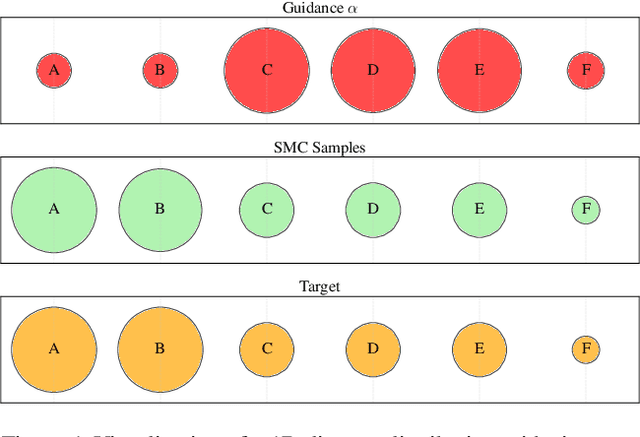
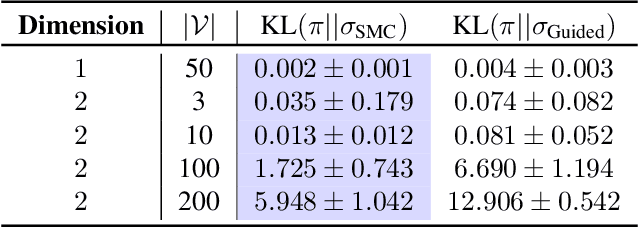
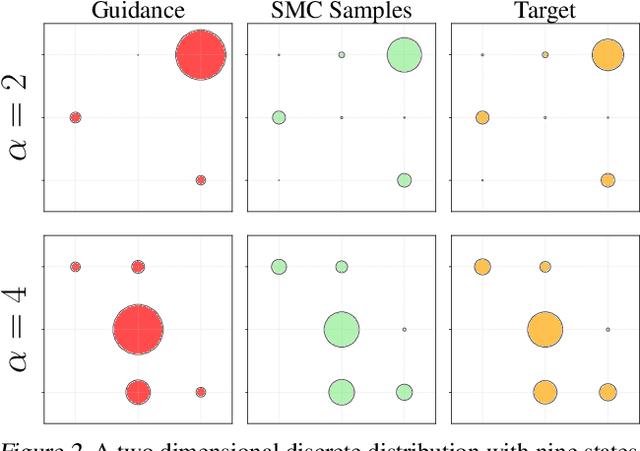

Discrete diffusion models are a class of generative models that produce samples from an approximated data distribution within a discrete state space. Often, there is a need to target specific regions of the data distribution. Current guidance methods aim to sample from a distribution with mass proportional to $p_0(x_0) p(\zeta|x_0)^\alpha$ but fail to achieve this in practice. We introduce a Sequential Monte Carlo algorithm that generates unbiasedly from this target distribution, utilising the learnt unconditional and guided process. We validate our approach on low-dimensional distributions, controlled images and text generations. For text generation, our method provides strong control while maintaining low perplexity compared to guidance-based approaches.
GeoFormer: A Multi-Polygon Segmentation Transformer
Nov 25, 2024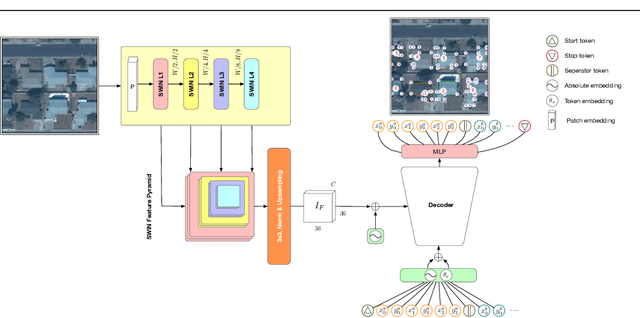


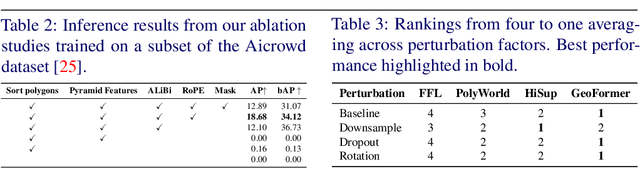
In remote sensing there exists a common need for learning scale invariant shapes of objects like buildings. Prior works relies on tweaking multiple loss functions to convert segmentation maps into the final scale invariant representation, necessitating arduous design and optimization. For this purpose we introduce the GeoFormer, a novel architecture which presents a remedy to the said challenges, learning to generate multipolygons end-to-end. By modeling keypoints as spatially dependent tokens in an auto-regressive manner, the GeoFormer outperforms existing works in delineating building objects from satellite imagery. We evaluate the robustness of the GeoFormer against former methods through a variety of parameter ablations and highlight the advantages of optimizing a single likelihood function. Our study presents the first successful application of auto-regressive transformer models for multi-polygon predictions in remote sensing, suggesting a promising methodological alternative for building vectorization.
MolMiner: Transformer architecture for fragment-based autoregressive generation of molecular stories
Nov 10, 2024



Deep generative models for molecular discovery have become a very popular choice in new high-throughput screening paradigms. These models have been developed inheriting from the advances in natural language processing and computer vision, achieving ever greater results. However, generative molecular modelling has unique challenges that are often overlooked. Chemical validity, interpretability of the generation process and flexibility to variable molecular sizes are among some of the remaining challenges for generative models in computational materials design. In this work, we propose an autoregressive approach that decomposes molecular generation into a sequence of discrete and interpretable steps using molecular fragments as units, a 'molecular story'. Enforcing chemical rules in the stories guarantees the chemical validity of the generated molecules, the discrete sequential steps of a molecular story makes the process transparent improving interpretability, and the autoregressive nature of the approach allows the size of the molecule to be a decision of the model. We demonstrate the validity of the approach in a multi-target inverse design of electroactive organic compounds, focusing on the target properties of solubility, redox potential, and synthetic accessibility. Our results show that the model can effectively bias the generation distribution according to the prompted multi-target objective.