 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Local Posterior Structure in Deep Ensembles
Mar 17, 2025Bayesian Neural Networks (BNNs) often improve model calibration and predictive uncertainty quantification compared to point estimators such as maximum-a-posteriori (MAP). Similarly, deep ensembles (DEs) are also known to improve calibration, and therefore, it is natural to hypothesize that deep ensembles of BNNs (DE-BNNs) should provide even further improvements. In this work, we systematically investigate this across a number of datasets, neural network architectures, and BNN approximation methods and surprisingly find that when the ensembles grow large enough, DEs consistently outperform DE-BNNs on in-distribution data. To shine light on this observation, we conduct several sensitivity and ablation studies. Moreover, we show that even though DE-BNNs outperform DEs on out-of-distribution metrics, this comes at the cost of decreased in-distribution performance. As a final contribution, we open-source the large pool of trained models to facilitate further research on this topic.
GeoFormer: A Multi-Polygon Segmentation Transformer
Nov 25, 2024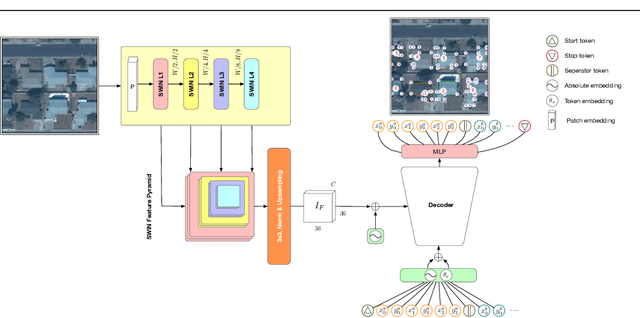


In remote sensing there exists a common need for learning scale invariant shapes of objects like buildings. Prior works relies on tweaking multiple loss functions to convert segmentation maps into the final scale invariant representation, necessitating arduous design and optimization. For this purpose we introduce the GeoFormer, a novel architecture which presents a remedy to the said challenges, learning to generate multipolygons end-to-end. By modeling keypoints as spatially dependent tokens in an auto-regressive manner, the GeoFormer outperforms existing works in delineating building objects from satellite imagery. We evaluate the robustness of the GeoFormer against former methods through a variety of parameter ablations and highlight the advantages of optimizing a single likelihood function. Our study presents the first successful application of auto-regressive transformer models for multi-polygon predictions in remote sensing, suggesting a promising methodological alternative for building vectorization.
EB-NeRD: A Large-Scale Dataset for News Recommendation
Oct 04, 2024
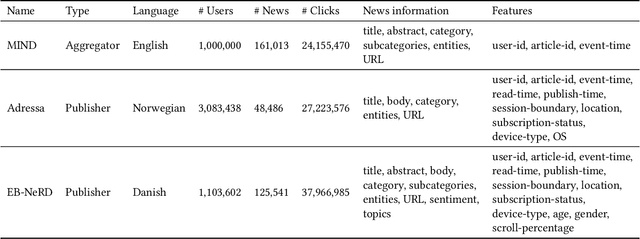

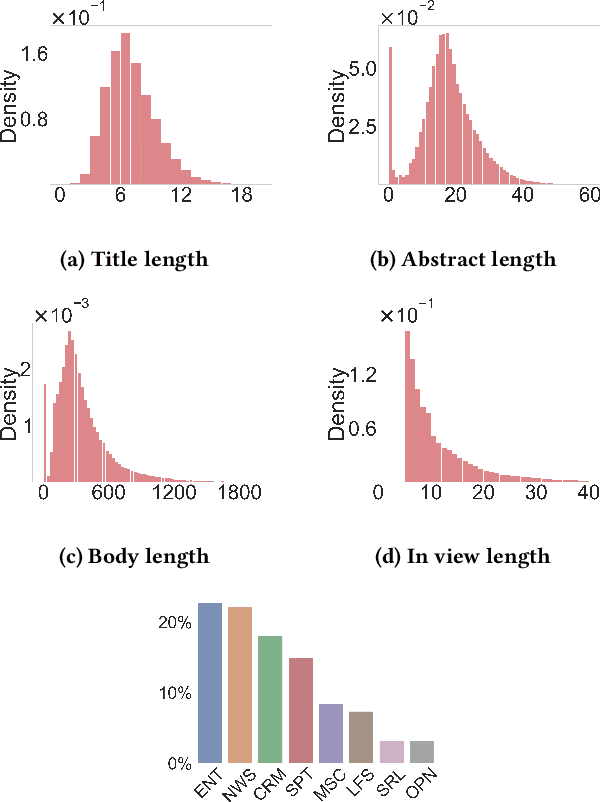
Personalized content recommendations have been pivotal to the content experience in digital media from video streaming to social networks. However, several domain specific challenges have held back adoption of recommender systems in news publishing. To address these challenges, we introduce the Ekstra Bladet News Recommendation Dataset (EB-NeRD). The dataset encompasses data from over a million unique users and more than 37 million impression logs from Ekstra Bladet. It also includes a collection of over 125,000 Danish news articles, complete with titles, abstracts, bodies, and metadata, such as categories. EB-NeRD served as the benchmark dataset for the RecSys '24 Challenge, where it was demonstrated how the dataset can be used to address both technical and normative challenges in designing effective and responsible recommender systems for news publishing. The dataset is available at: https://recsys.eb.dk.
RecSys Challenge 2024: Balancing Accuracy and Editorial Values in News Recommendations
Sep 30, 2024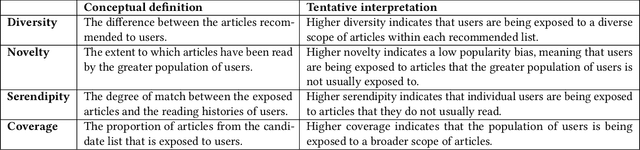
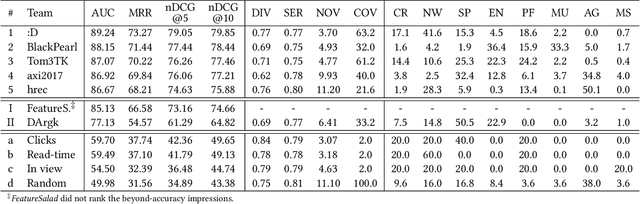
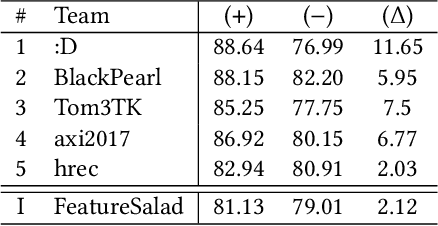
The RecSys Challenge 2024 aims to advance news recommendation by addressing both the technical and normative challenges inherent in designing effective and responsible recommender systems for news publishing. This paper describes the challenge, including its objectives, problem setting, and the dataset provided by the Danish news publishers Ekstra Bladet and JP/Politikens Media Group ("Ekstra Bladet"). The challenge explores the unique aspects of news recommendation, such as modeling user preferences based on behavior, accounting for the influence of the news agenda on user interests, and managing the rapid decay of news items. Additionally, the challenge embraces normative complexities, investigating the effects of recommender systems on news flow and their alignment with editorial values. We summarize the challenge setup, dataset characteristics, and evaluation metrics. Finally, we announce the winners and highlight their contributions. The dataset is available at: https://recsys.eb.dk.
Variance reduction of diffusion model's gradients with Taylor approximation-based control variate
Aug 22, 2024



Score-based models, trained with denoising score matching, are remarkably effective in generating high dimensional data. However, the high variance of their training objective hinders optimisation. We attempt to reduce it with a control variate, derived via a $k$-th order Taylor expansion on the training objective and its gradient. We prove an equivalence between the two and demonstrate empirically the effectiveness of our approach on a low dimensional problem setting; and study its effect on larger problems.
Neural machine translation for automated feedback on children's early-stage writing
Nov 15, 2023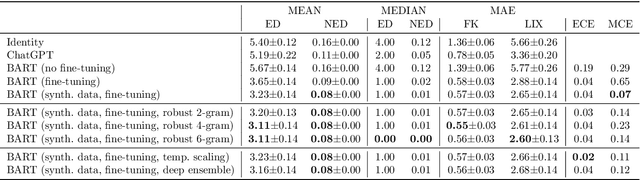
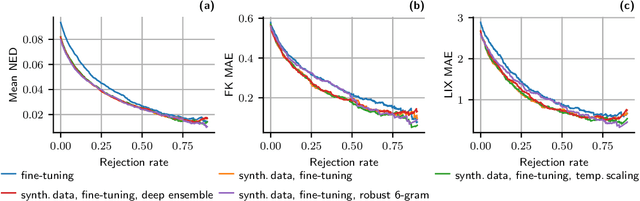
In this work, we address the problem of assessing and constructing feedback for early-stage writing automatically using machine learning. Early-stage writing is typically vastly different from conventional writing due to phonetic spelling and lack of proper grammar, punctuation, spacing etc. Consequently, early-stage writing is highly non-trivial to analyze using common linguistic metrics. We propose to use sequence-to-sequence models for "translating" early-stage writing by students into "conventional" writing, which allows the translated text to be analyzed using linguistic metrics. Furthermore, we propose a novel robust likelihood to mitigate the effect of noise in the dataset. We investigate the proposed methods using a set of numerical experiments and demonstrate that the conventional text can be predicted with high accuracy.
Polygonizer: An auto-regressive building delineator
Apr 08, 2023



In geospatial planning, it is often essential to represent objects in a vectorized format, as this format easily translates to downstream tasks such as web development, graphics, or design. While these problems are frequently addressed using semantic segmentation, which requires additional post-processing to vectorize objects in a non-trivial way, we present an Image-to-Sequence model that allows for direct shape inference and is ready for vector-based workflows out of the box. We demonstrate the model's performance in various ways, including perturbations to the image input that correspond to variations or artifacts commonly encountered in remote sensing applications. Our model outperforms prior works when using ground truth bounding boxes (one object per image), achieving the lowest maximum tangent angle error.
Learning to Generate 3D Representations of Building Roofs Using Single-View Aerial Imagery
Mar 20, 2023



We present a novel pipeline for learning the conditional distribution of a building roof mesh given pixels from an aerial image, under the assumption that roof geometry follows a set of regular patterns. Unlike alternative methods that require multiple images of the same object, our approach enables estimating 3D roof meshes using only a single image for predictions. The approach employs the PolyGen, a deep generative transformer architecture for 3D meshes. We apply this model in a new domain and investigate the sensitivity of the image resolution. We propose a novel metric to evaluate the performance of the inferred meshes, and our results show that the model is robust even at lower resolutions, while qualitatively producing realistic representations for out-of-distribution samples.
On the role of Model Uncertainties in Bayesian Optimization
Jan 14, 2023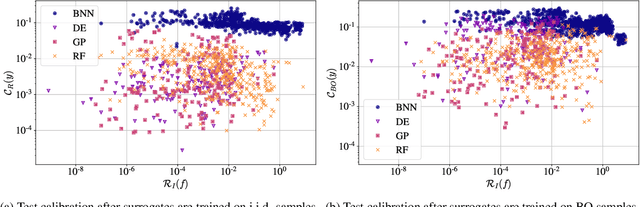

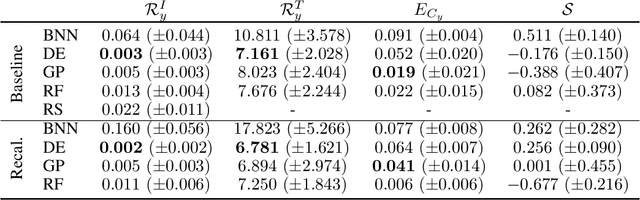
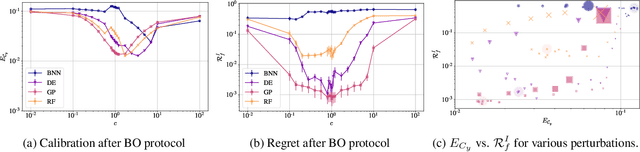
Bayesian optimization (BO) is a popular method for black-box optimization, which relies on uncertainty as part of its decision-making process when deciding which experiment to perform next. However, not much work has addressed the effect of uncertainty on the performance of the BO algorithm and to what extent calibrated uncertainties improve the ability to find the global optimum. In this work, we provide an extensive study of the relationship between the BO performance (regret) and uncertainty calibration for popular surrogate models and compare them across both synthetic and real-world experiments. Our results confirm that Gaussian Processes are strong surrogate models and that they tend to outperform other popular models. Our results further show a positive association between calibration error and regret, but interestingly, this association disappears when we control for the type of model in the analysis. We also studied the effect of re-calibration and demonstrate that it generally does not lead to improved regret. Finally, we provide theoretical justification for why uncertainty calibration might be difficult to combine with BO due to the small sample sizes commonly used.
SolarDK: A high-resolution urban solar panel image classification and localization dataset
Dec 02, 2022



The body of research on classification of solar panel arrays from aerial imagery is increasing, yet there are still not many public benchmark datasets. This paper introduces two novel benchmark datasets for classifying and localizing solar panel arrays in Denmark: A human annotated dataset for classification and segmentation, as well as a classification dataset acquired using self-reported data from the Danish national building registry. We explore the performance of prior works on the new benchmark dataset, and present results after fine-tuning models using a similar approach as recent works. Furthermore, we train models of newer architectures and provide benchmark baselines to our datasets in several scenarios. We believe the release of these datasets may improve future research in both local and global geospatial domains for identifying and mapping of solar panel arrays from aerial imagery. The data is accessible at https://osf.io/aj539/.