 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSteering LLMs? Actually, Sparse Autoencoders can outperform simple baselines
May 29, 2026Sparse Autoencoders (SAEs) have been seen as a promising avenue for exploring the internals of Large Language Models (LLMs) and for steering model output generation. When AxBench - a model steering benchmark - was introduced in Wu et al. (2025), SAEs did not seem to live up to their original hype due to poor steering performance relative to a set of simple baselines. This work serves as a partial rebuttal for Sparse Autoencoders and suggests that the results of Wu et al. (2025) did not do them full justice. We find that Sparse Autoencoders can, in fact, perform close to on par with the reference LoRA performance on the AxBench benchmark, when features are selected and labelled with our supervised pipeline. We also find that our pipeline selects features that are surprisingly causal of their identified labels when using only its interpretability-based components. Lastly, we present evidence that high sparsity (low l0) may not be crucial for successful steering based on interpretability, which is in contrast to the earlier findings in Wang et al. (2025).
Mechanistic Interpretability of EEG Foundation Models via Sparse Autoencoders
May 13, 2026EEG foundation models achieve state-of-the-art clinical performance, yet the internal computations driving their predictions remain opaque: a barrier to clinical trust. We apply TopK Sparse Autoencoders (SAEs) across three architecturally distinct EEG transformers: SleepFM, REVE, and LaBraM to extract sparse feature dictionaries from their embeddings. By grounding these features in a clinical taxonomy (abnormality, age, sex, and medication), we benchmark monosemanticity and entanglement across architectures. A single hyperparameter procedure, driven by an intrinsic dictionary health audit, transfers robustly across all three architectures. Via concept steering, we introduce a "target vs. off-target" probe area metric to quantify steering selectivity and reveal three operational regimes: selectively steerable, encoded but entangled, and non-encoded. This framework exposes critical representational failures: "wrecking-ball" interventions that collapse global model performance, and clinical entanglements, such as age-pathology confounding, where it is impossible to suppress one concept without corrupting the other. Finally, a spectral decoder maps these interventions back to the amplitude spectrum, translating latent manipulations into physiologically interpretable frequency signatures, such as pathological slow-wave suppression and $α$-band restoration.
Pretraining on Sleep Data Improves non-Sleep Biosignal Tasks
May 04, 2026Sleep foundation models have recently demonstrated strong performance on in-domain polysomnography tasks, including sleep staging, apnea detection, and disease risk prediction. In this work, we investigate whether sleep biosignals can serve as an effective pretraining distribution for learning representations that transfer beyond sleep to adjacent domains. Following sleep foundation models, we perform sleep-only multimodal contrastive pretraining (with a leave-one-out objective) and evaluate transfer to non-sleep EEG and ECG, two well-benchmarked biosignal modalities with heterogeneous datasets and clinically meaningful downstream tasks. Across eight downstream tasks spanning multiple EEG and ECG datasets, sleep pretraining consistently improves performance relative to training from scratch. Moreover, on several tasks, we achieve performance competitive with or surpassing prior specialized state-of-the-art and foundation models.
Missing-Data-Induced Phase Transitions in Spectral PLS for Multimodal Learning
Jan 29, 2026Partial Least Squares (PLS) learns shared structure from paired data via the top singular vectors of the empirical cross-covariance (PLS-SVD), but multimodal datasets often have missing entries in both views. We study PLS-SVD under independent entry-wise missing-completely-at-random masking in a proportional high-dimensional spiked model. After appropriate normalization, the masked cross-covariance behaves like a spiked rectangular random matrix whose effective signal strength is attenuated by $\sqrtρ$, where $ρ$ is the joint entry retention probability. As a result, PLS-SVD exhibits a sharp BBP-type phase transition: below a critical signal-to-noise threshold the leading singular vectors are asymptotically uninformative, while above it they achieve nontrivial alignment with the latent shared directions, with closed-form asymptotic overlap formulas. Simulations and semi-synthetic multimodal experiments corroborate the predicted phase diagram and recovery curves across aspect ratios, signal strengths, and missingness levels.
Large Vision Models Can Solve Mental Rotation Problems
Sep 18, 2025Mental rotation is a key test of spatial reasoning in humans and has been central to understanding how perception supports cognition. Despite the success of modern vision transformers, it is still unclear how well these models develop similar abilities. In this work, we present a systematic evaluation of ViT, CLIP, DINOv2, and DINOv3 across a range of mental-rotation tasks, from simple block structures similar to those used by Shepard and Metzler to study human cognition, to more complex block figures, three types of text, and photo-realistic objects. By probing model representations layer by layer, we examine where and how these networks succeed. We find that i) self-supervised ViTs capture geometric structure better than supervised ViTs; ii) intermediate layers perform better than final layers; iii) task difficulty increases with rotation complexity and occlusion, mirroring human reaction times and suggesting similar constraints in embedding space representations.
Minimizing False-Positive Attributions in Explanations of Non-Linear Models
May 16, 2025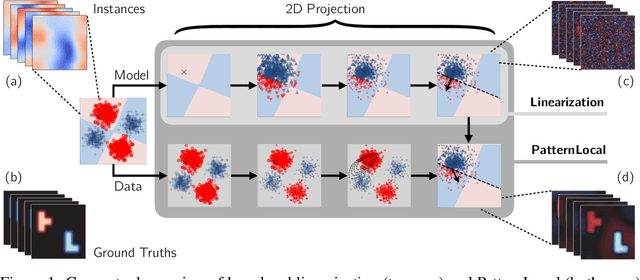
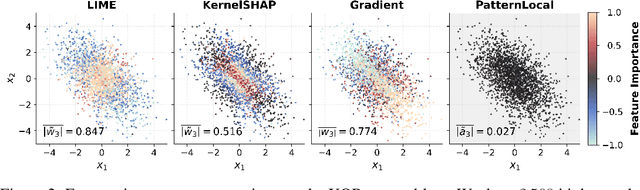
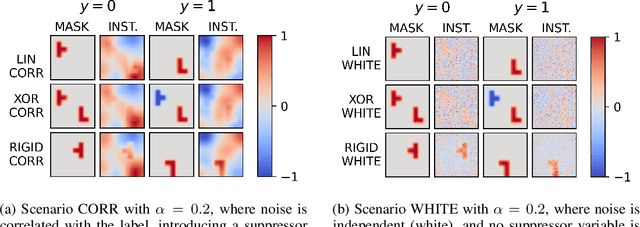
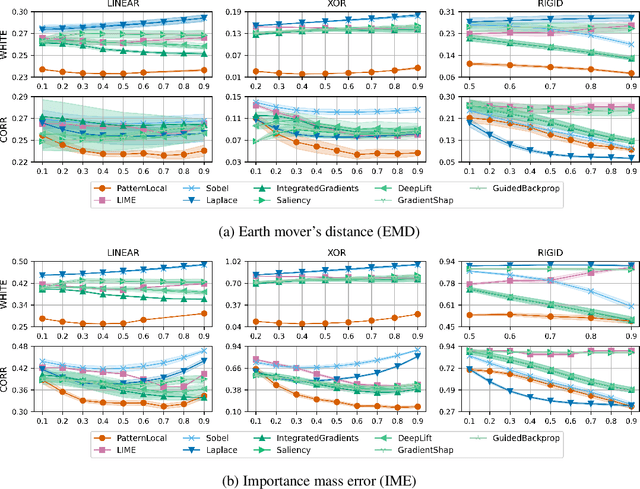
Suppressor variables can influence model predictions without being dependent on the target outcome and they pose a significant challenge for Explainable AI (XAI) methods. These variables may cause false-positive feature attributions, undermining the utility of explanations. Although effective remedies exist for linear models, their extension to non-linear models and to instance-based explanations has remained limited. We introduce PatternLocal, a novel XAI technique that addresses this gap. PatternLocal begins with a locally linear surrogate, e.g. LIME, KernelSHAP, or gradient-based methods, and transforms the resulting discriminative model weights into a generative representation, thereby suppressing the influence of suppressor variables while preserving local fidelity. In extensive hyperparameter optimization on the XAI-TRIS benchmark, PatternLocal consistently outperformed other XAI methods and reduced false-positive attributions when explaining non-linear tasks, thereby enabling more reliable and actionable insights.
From Colors to Classes: Emergence of Concepts in Vision Transformers
Mar 31, 2025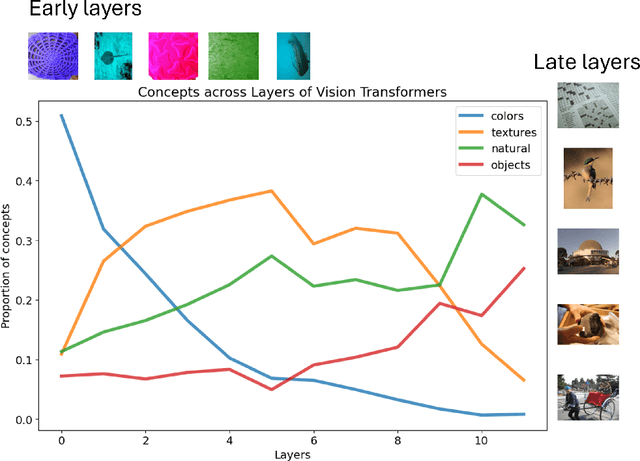
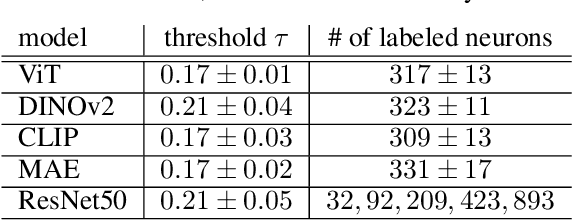
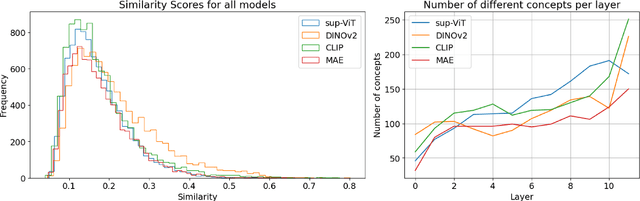
Vision Transformers (ViTs) are increasingly utilized in various computer vision tasks due to their powerful representation capabilities. However, it remains understudied how ViTs process information layer by layer. Numerous studies have shown that convolutional neural networks (CNNs) extract features of increasing complexity throughout their layers, which is crucial for tasks like domain adaptation and transfer learning. ViTs, lacking the same inductive biases as CNNs, can potentially learn global dependencies from the first layers due to their attention mechanisms. Given the increasing importance of ViTs in computer vision, there is a need to improve the layer-wise understanding of ViTs. In this work, we present a novel, layer-wise analysis of concepts encoded in state-of-the-art ViTs using neuron labeling. Our findings reveal that ViTs encode concepts with increasing complexity throughout the network. Early layers primarily encode basic features such as colors and textures, while later layers represent more specific classes, including objects and animals. As the complexity of encoded concepts increases, the number of concepts represented in each layer also rises, reflecting a more diverse and specific set of features. Additionally, different pretraining strategies influence the quantity and category of encoded concepts, with finetuning to specific downstream tasks generally reducing the number of encoded concepts and shifting the concepts to more relevant categories.
Danoliteracy of Generative, Large Language Models
Oct 30, 2024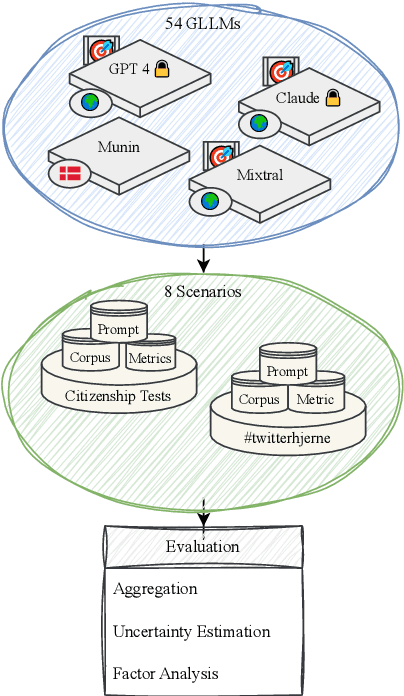
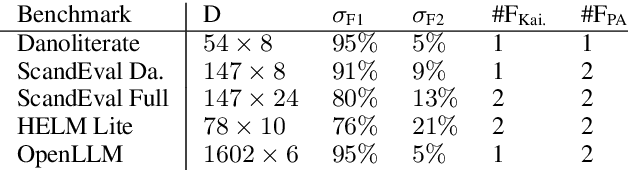
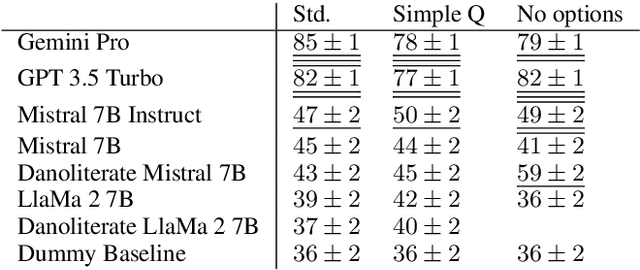
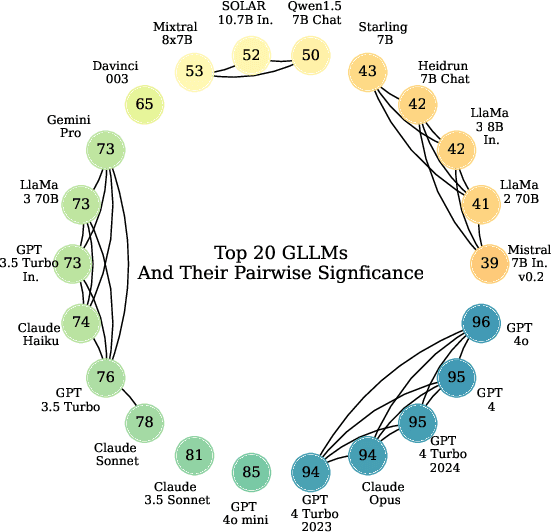
The language technology moonshot moment of Generative, Large Language Models (GLLMs) was not limited to English: These models brought a surge of technological applications, investments and hype to low-resource languages as well. However, the capabilities of these models in languages such as Danish were until recently difficult to verify beyond qualitative demonstrations due to a lack of applicable evaluation corpora. We present a GLLM benchmark to evaluate Danoliteracy, a measure of Danish language and cultural competency, across eight diverse scenarios such Danish citizenship tests and abstractive social media question answering. This limited-size benchmark is found to produce a robust ranking that correlates to human feedback at $\rho \sim 0.8$ with GPT-4 and Claude Opus models achieving the highest rankings. Analyzing these model results across scenarios, we find one strong underlying factor explaining $95\%$ of scenario performance variance for GLLMs in Danish, suggesting a $g$ factor of model consistency in language adaption.
BiSSL: Bilevel Optimization for Self-Supervised Pre-Training and Fine-Tuning
Oct 03, 2024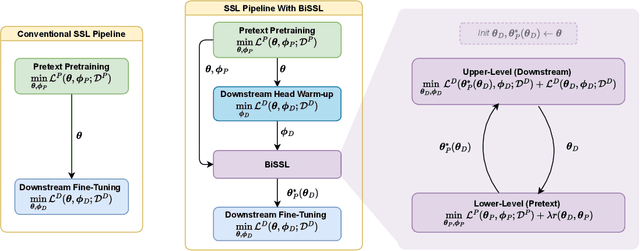
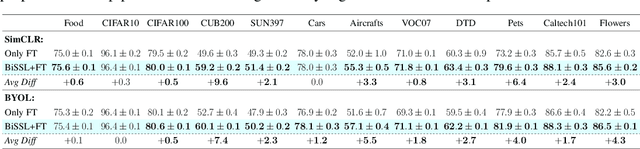

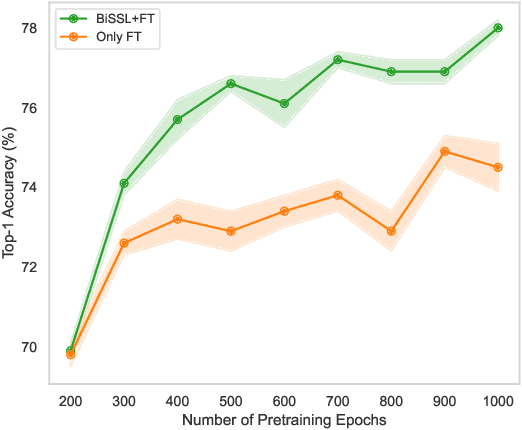
In this work, we present BiSSL, a first-of-its-kind training framework that introduces bilevel optimization to enhance the alignment between the pretext pre-training and downstream fine-tuning stages in self-supervised learning. BiSSL formulates the pretext and downstream task objectives as the lower- and upper-level objectives in a bilevel optimization problem and serves as an intermediate training stage within the self-supervised learning pipeline. By more explicitly modeling the interdependence of these training stages, BiSSL facilitates enhanced information sharing between them, ultimately leading to a backbone parameter initialization that is better suited for the downstream task. We propose a training algorithm that alternates between optimizing the two objectives defined in BiSSL. Using a ResNet-18 backbone pre-trained with SimCLR on the STL10 dataset, we demonstrate that our proposed framework consistently achieves improved or competitive classification accuracies across various downstream image classification datasets compared to the conventional self-supervised learning pipeline. Qualitative analyses of the backbone features further suggest that BiSSL enhances the alignment of downstream features in the backbone prior to fine-tuning.
Connecting Concept Convexity and Human-Machine Alignment in Deep Neural Networks
Sep 10, 2024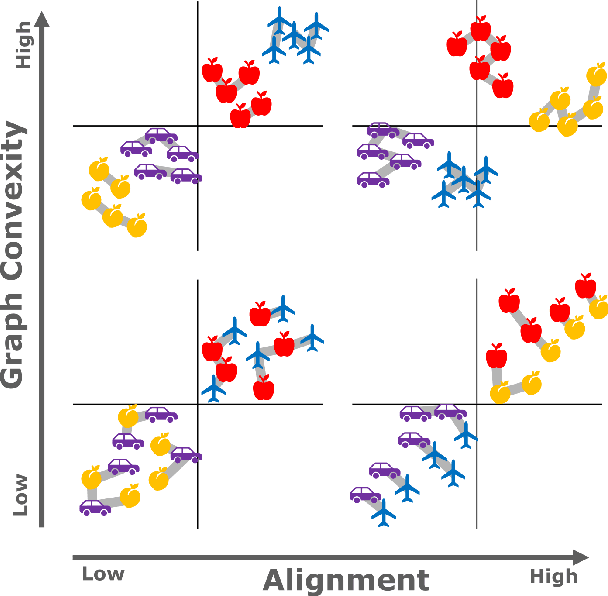
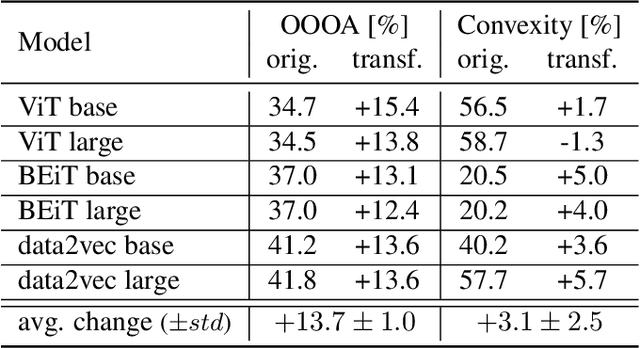
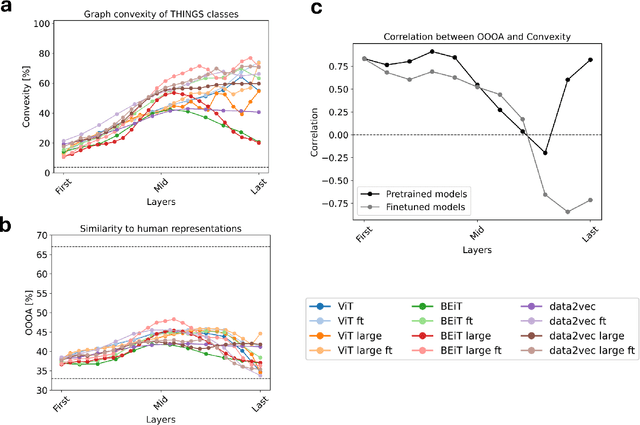
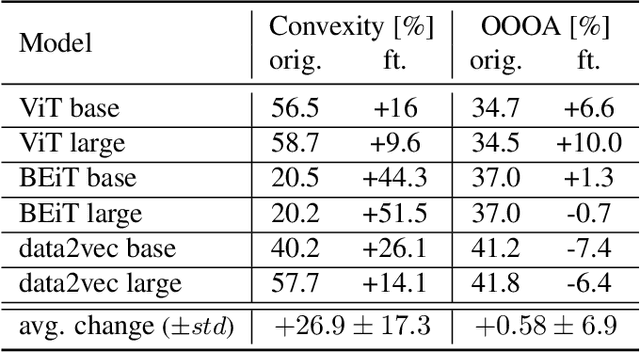
Understanding how neural networks align with human cognitive processes is a crucial step toward developing more interpretable and reliable AI systems. Motivated by theories of human cognition, this study examines the relationship between \emph{convexity} in neural network representations and \emph{human-machine alignment} based on behavioral data. We identify a correlation between these two dimensions in pretrained and fine-tuned vision transformer models. Our findings suggest that the convex regions formed in latent spaces of neural networks to some extent align with human-defined categories and reflect the similarity relations humans use in cognitive tasks. While optimizing for alignment generally enhances convexity, increasing convexity through fine-tuning yields inconsistent effects on alignment, which suggests a complex relationship between the two. This study presents a first step toward understanding the relationship between the convexity of latent representations and human-machine alignment.