 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConvexity-based Pruning of Speech Representation Models
Paper and Code
Aug 16, 2024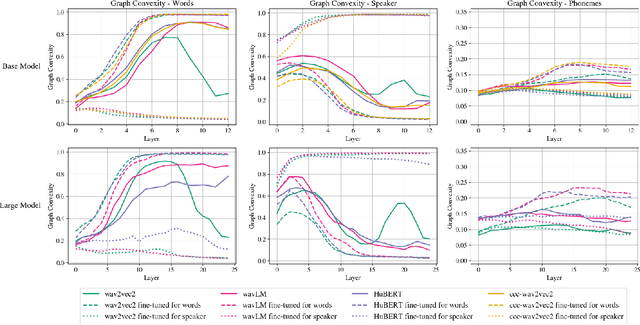
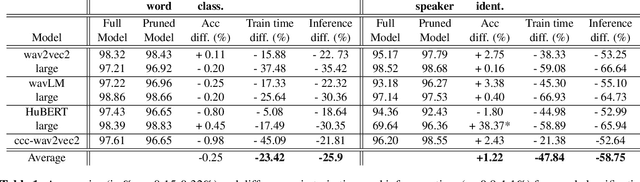
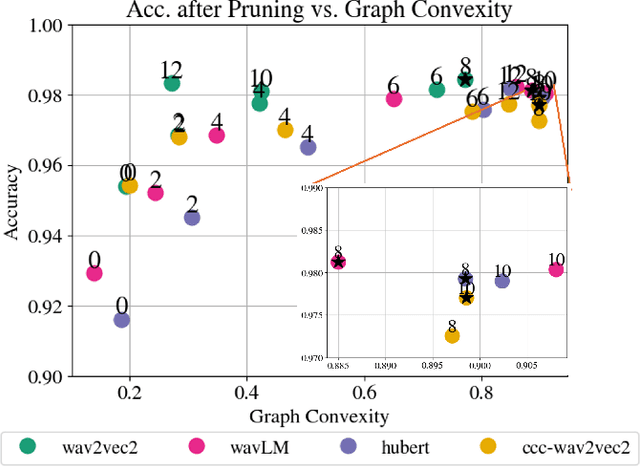
Speech representation models based on the transformer architecture and trained by self-supervised learning have shown great promise for solving tasks such as speech and speaker recognition, keyword spotting, emotion detection, and more. Typically, it is found that larger models lead to better performance. However, the significant computational effort involved in such large transformer systems is a challenge for embedded and real-world applications. Recent work has shown that there is significant redundancy in the transformer models for NLP and massive layer pruning is feasible (Sajjad et al., 2023). Here, we investigate layer pruning in audio models. We base the pruning decision on a convexity criterion. Convexity of classification regions has recently been proposed as an indicator of subsequent fine-tuning performance in a range of application domains, including NLP and audio. In empirical investigations, we find a massive reduction in the computational effort with no loss of performance or even improvements in certain cases.