 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKeypoint Counting Classifiers: Turning Vision Transformers into Self-Explainable Models Without Training
Dec 19, 2025
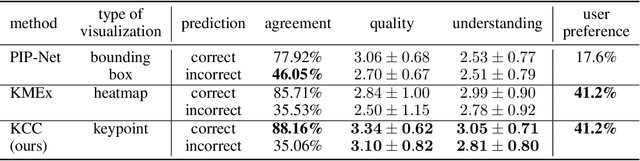

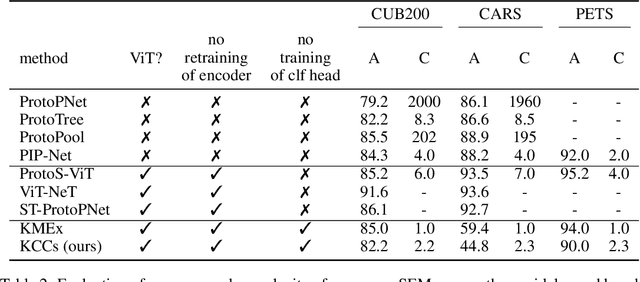
Current approaches for designing self-explainable models (SEMs) require complicated training procedures and specific architectures which makes them impractical. With the advance of general purpose foundation models based on Vision Transformers (ViTs), this impracticability becomes even more problematic. Therefore, new methods are necessary to provide transparency and reliability to ViT-based foundation models. In this work, we present a new method for turning any well-trained ViT-based model into a SEM without retraining, which we call Keypoint Counting Classifiers (KCCs). Recent works have shown that ViTs can automatically identify matching keypoints between images with high precision, and we build on these results to create an easily interpretable decision process that is inherently visualizable in the input. We perform an extensive evaluation which show that KCCs improve the human-machine communication compared to recent baselines. We believe that KCCs constitute an important step towards making ViT-based foundation models more transparent and reliable.
From Colors to Classes: Emergence of Concepts in Vision Transformers
Mar 31, 2025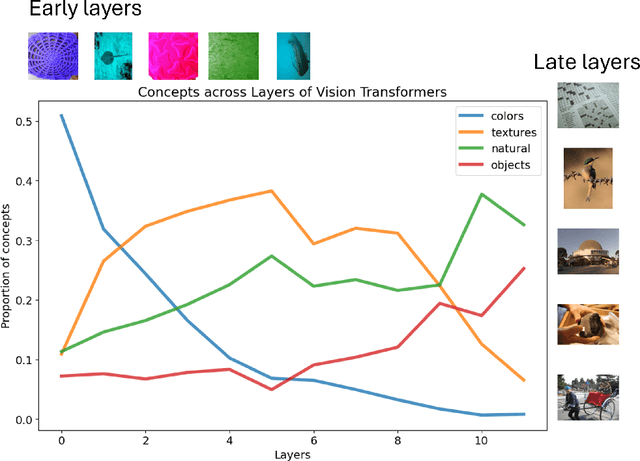
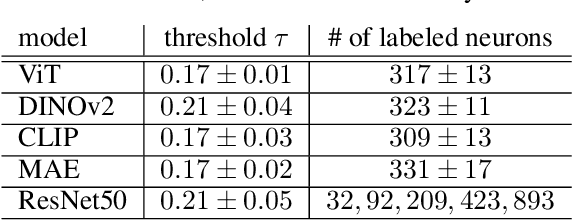
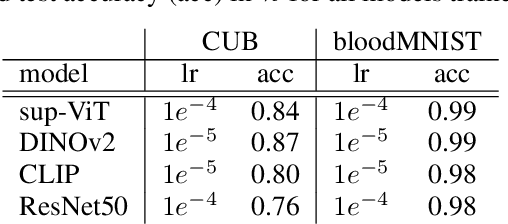
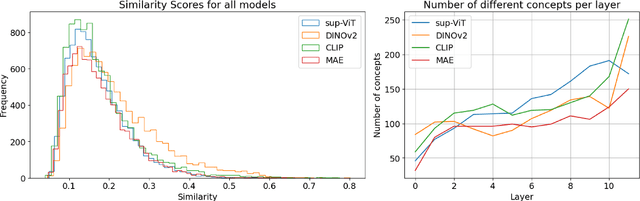
Vision Transformers (ViTs) are increasingly utilized in various computer vision tasks due to their powerful representation capabilities. However, it remains understudied how ViTs process information layer by layer. Numerous studies have shown that convolutional neural networks (CNNs) extract features of increasing complexity throughout their layers, which is crucial for tasks like domain adaptation and transfer learning. ViTs, lacking the same inductive biases as CNNs, can potentially learn global dependencies from the first layers due to their attention mechanisms. Given the increasing importance of ViTs in computer vision, there is a need to improve the layer-wise understanding of ViTs. In this work, we present a novel, layer-wise analysis of concepts encoded in state-of-the-art ViTs using neuron labeling. Our findings reveal that ViTs encode concepts with increasing complexity throughout the network. Early layers primarily encode basic features such as colors and textures, while later layers represent more specific classes, including objects and animals. As the complexity of encoded concepts increases, the number of concepts represented in each layer also rises, reflecting a more diverse and specific set of features. Additionally, different pretraining strategies influence the quantity and category of encoded concepts, with finetuning to specific downstream tasks generally reducing the number of encoded concepts and shifting the concepts to more relevant categories.
Connecting Concept Convexity and Human-Machine Alignment in Deep Neural Networks
Sep 10, 2024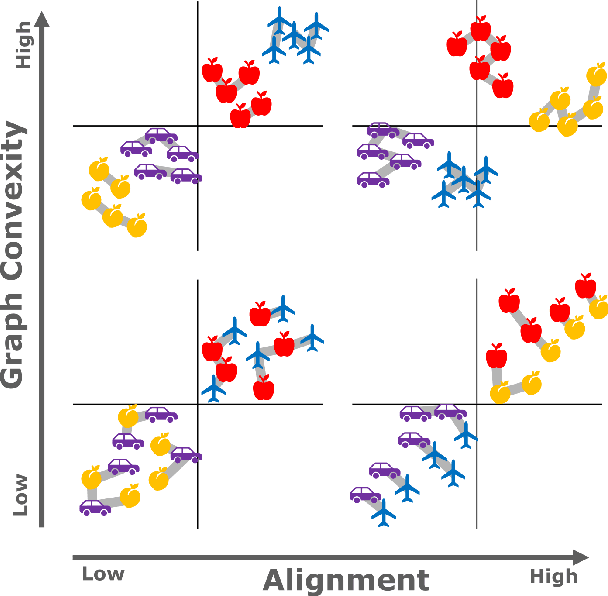
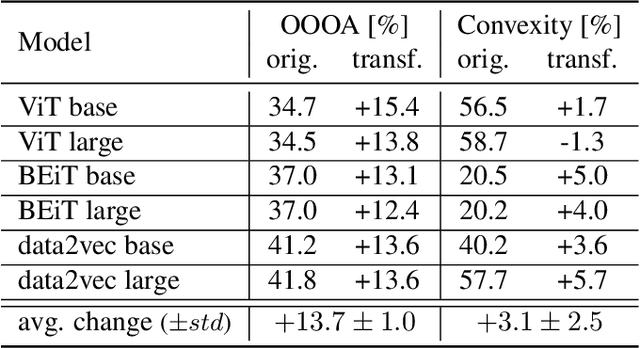
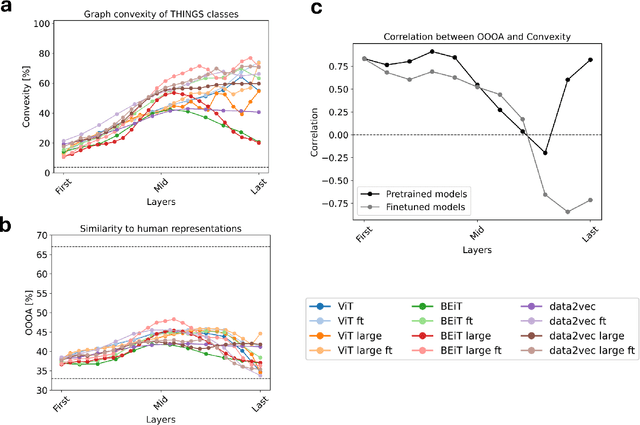
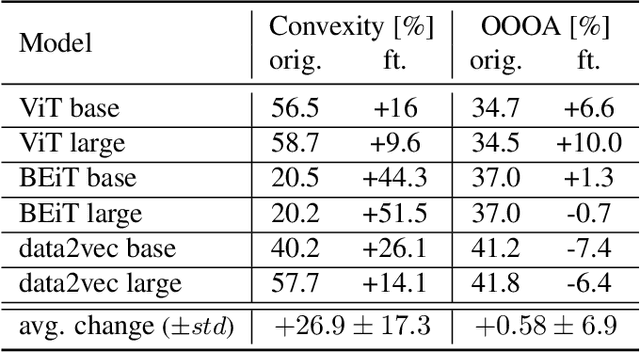
Understanding how neural networks align with human cognitive processes is a crucial step toward developing more interpretable and reliable AI systems. Motivated by theories of human cognition, this study examines the relationship between \emph{convexity} in neural network representations and \emph{human-machine alignment} based on behavioral data. We identify a correlation between these two dimensions in pretrained and fine-tuned vision transformer models. Our findings suggest that the convex regions formed in latent spaces of neural networks to some extent align with human-defined categories and reflect the similarity relations humans use in cognitive tasks. While optimizing for alignment generally enhances convexity, increasing convexity through fine-tuning yields inconsistent effects on alignment, which suggests a complex relationship between the two. This study presents a first step toward understanding the relationship between the convexity of latent representations and human-machine alignment.
Convexity-based Pruning of Speech Representation Models
Aug 16, 2024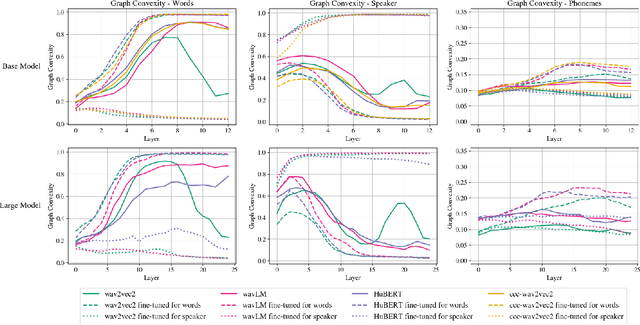
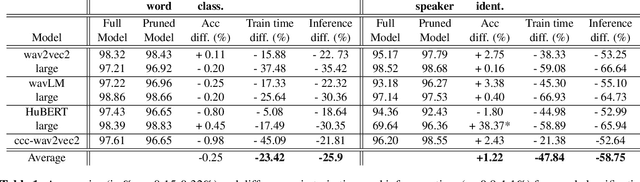
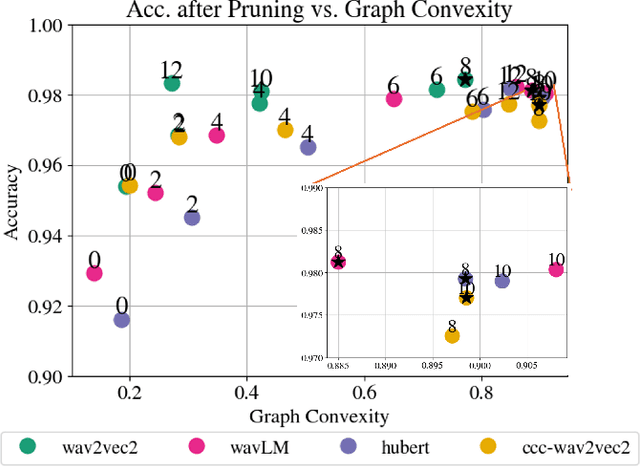
Speech representation models based on the transformer architecture and trained by self-supervised learning have shown great promise for solving tasks such as speech and speaker recognition, keyword spotting, emotion detection, and more. Typically, it is found that larger models lead to better performance. However, the significant computational effort involved in such large transformer systems is a challenge for embedded and real-world applications. Recent work has shown that there is significant redundancy in the transformer models for NLP and massive layer pruning is feasible (Sajjad et al., 2023). Here, we investigate layer pruning in audio models. We base the pruning decision on a convexity criterion. Convexity of classification regions has recently been proposed as an indicator of subsequent fine-tuning performance in a range of application domains, including NLP and audio. In empirical investigations, we find a massive reduction in the computational effort with no loss of performance or even improvements in certain cases.