 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCat, Rat, Meow: On the Alignment of Language Model and Human Term-Similarity Judgments
Apr 10, 2025Small and mid-sized generative language models have gained increasing attention. Their size and availability make them amenable to being analyzed at a behavioral as well as a representational level, allowing investigations of how these levels interact. We evaluate 32 publicly available language models for their representational and behavioral alignment with human similarity judgments on a word triplet task. This provides a novel evaluation setting to probe semantic associations in language beyond common pairwise comparisons. We find that (1) even the representations of small language models can achieve human-level alignment, (2) instruction-tuned model variants can exhibit substantially increased agreement, (3) the pattern of alignment across layers is highly model dependent, and (4) alignment based on models' behavioral responses is highly dependent on model size, matching their representational alignment only for the largest evaluated models.
Latent Diffusion U-Net Representations Contain Positional Embeddings and Anomalies
Apr 09, 2025Diffusion models have demonstrated remarkable capabilities in synthesizing realistic images, spurring interest in using their representations for various downstream tasks. To better understand the robustness of these representations, we analyze popular Stable Diffusion models using representational similarity and norms. Our findings reveal three phenomena: (1) the presence of a learned positional embedding in intermediate representations, (2) high-similarity corner artifacts, and (3) anomalous high-norm artifacts. These findings underscore the need to further investigate the properties of diffusion model representations before considering them for downstream tasks that require robust features. Project page: https://jonasloos.github.io/sd-representation-anomalies
Training objective drives the consistency of representational similarity across datasets
Nov 08, 2024



The Platonic Representation Hypothesis claims that recent foundation models are converging to a shared representation space as a function of their downstream task performance, irrespective of the objectives and data modalities used to train these models. Representational similarity is generally measured for individual datasets and is not necessarily consistent across datasets. Thus, one may wonder whether this convergence of model representations is confounded by the datasets commonly used in machine learning. Here, we propose a systematic way to measure how representational similarity between models varies with the set of stimuli used to construct the representations. We find that the objective function is the most crucial factor in determining the consistency of representational similarities across datasets. Specifically, self-supervised vision models learn representations whose relative pairwise similarities generalize better from one dataset to another compared to those of image classification or image-text models. Moreover, the correspondence between representational similarities and the models' task behavior is dataset-dependent, being most strongly pronounced for single-domain datasets. Our work provides a framework for systematically measuring similarities of model representations across datasets and linking those similarities to differences in task behavior.
Connecting Concept Convexity and Human-Machine Alignment in Deep Neural Networks
Sep 10, 2024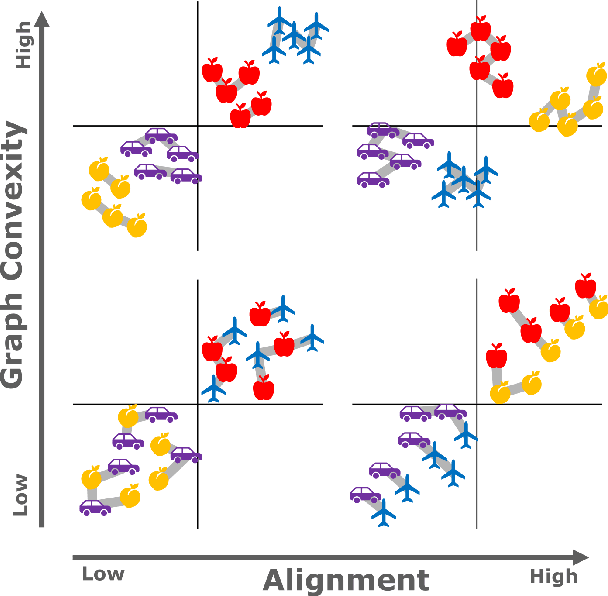
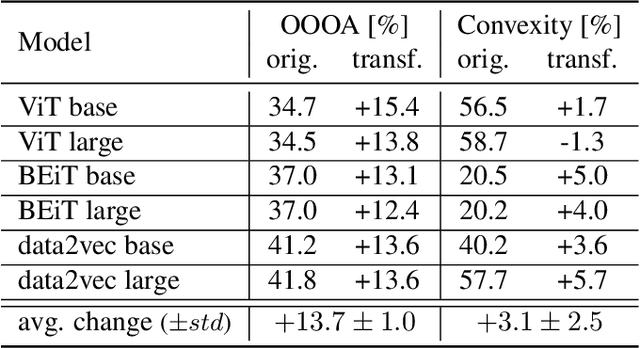
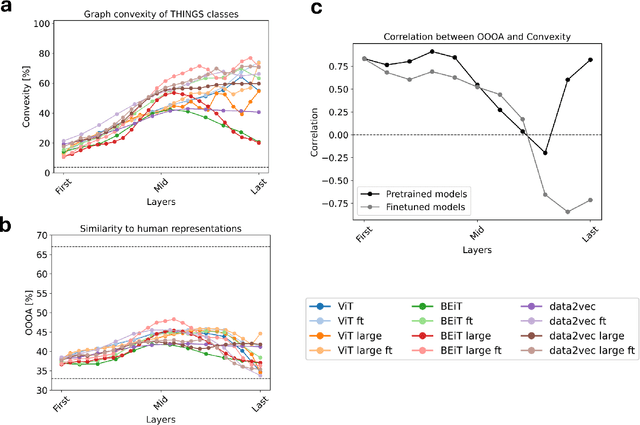
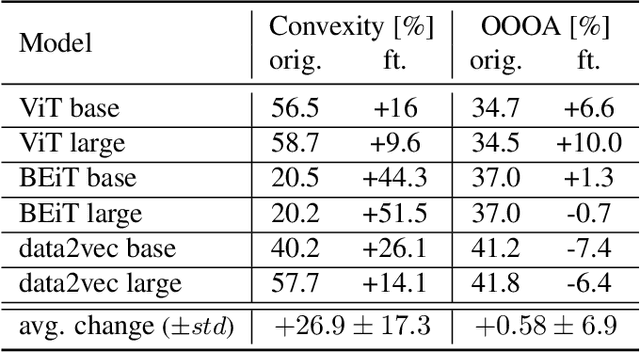
Understanding how neural networks align with human cognitive processes is a crucial step toward developing more interpretable and reliable AI systems. Motivated by theories of human cognition, this study examines the relationship between \emph{convexity} in neural network representations and \emph{human-machine alignment} based on behavioral data. We identify a correlation between these two dimensions in pretrained and fine-tuned vision transformer models. Our findings suggest that the convex regions formed in latent spaces of neural networks to some extent align with human-defined categories and reflect the similarity relations humans use in cognitive tasks. While optimizing for alignment generally enhances convexity, increasing convexity through fine-tuning yields inconsistent effects on alignment, which suggests a complex relationship between the two. This study presents a first step toward understanding the relationship between the convexity of latent representations and human-machine alignment.
An Analysis of Human Alignment of Latent Diffusion Models
Mar 13, 2024
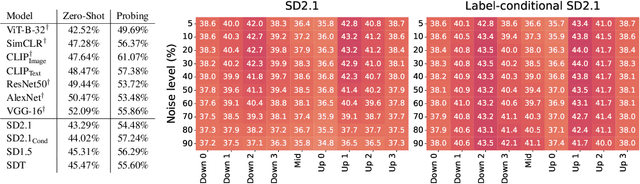


Diffusion models, trained on large amounts of data, showed remarkable performance for image synthesis. They have high error consistency with humans and low texture bias when used for classification. Furthermore, prior work demonstrated the decomposability of their bottleneck layer representations into semantic directions. In this work, we analyze how well such representations are aligned to human responses on a triplet odd-one-out task. We find that despite the aforementioned observations: I) The representational alignment with humans is comparable to that of models trained only on ImageNet-1k. II) The most aligned layers of the denoiser U-Net are intermediate layers and not the bottleneck. III) Text conditioning greatly improves alignment at high noise levels, hinting at the importance of abstract textual information, especially in the early stage of generation.
Improving neural network representations using human similarity judgments
Jun 07, 2023

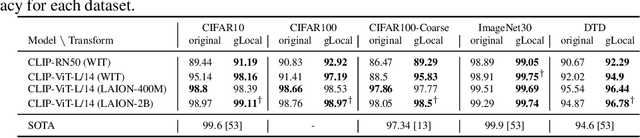
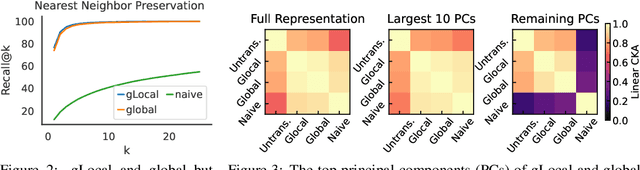
Deep neural networks have reached human-level performance on many computer vision tasks. However, the objectives used to train these networks enforce only that similar images are embedded at similar locations in the representation space, and do not directly constrain the global structure of the resulting space. Here, we explore the impact of supervising this global structure by linearly aligning it with human similarity judgments. We find that a naive approach leads to large changes in local representational structure that harm downstream performance. Thus, we propose a novel method that aligns the global structure of representations while preserving their local structure. This global-local transform considerably improves accuracy across a variety of few-shot learning and anomaly detection tasks. Our results indicate that human visual representations are globally organized in a way that facilitates learning from few examples, and incorporating this global structure into neural network representations improves performance on downstream tasks.
Preemptively Pruning Clever-Hans Strategies in Deep Neural Networks
Apr 12, 2023



Explainable AI has become a popular tool for validating machine learning models. Mismatches between the explained model's decision strategy and the user's domain knowledge (e.g. Clever Hans effects) have also been recognized as a starting point for improving faulty models. However, it is less clear what to do when the user and the explanation agree. In this paper, we demonstrate that acceptance of explanations by the user is not a guarantee for a ML model to function well, in particular, some Clever Hans effects may remain undetected. Such hidden flaws of the model can nevertheless be mitigated, and we demonstrate this by contributing a new method, Explanation-Guided Exposure Minimization (EGEM), that premptively prunes variations in the ML model that have not been the subject of positive explanation feedback. Experiments on natural image data demonstrate that our approach leads to models that strongly reduce their reliance on hidden Clever Hans strategies, and consequently achieve higher accuracy on new data.
Human alignment of neural network representations
Nov 21, 2022Today's computer vision models achieve human or near-human level performance across a wide variety of vision tasks. However, their architectures, data, and learning algorithms differ in numerous ways from those that give rise to human vision. In this paper, we investigate the factors that affect alignment between the representations learned by neural networks and human concept representations. Human representations are inferred from behavioral responses in an odd-one-out triplet task, where humans were presented with three images and had to select the odd-one-out. We find that model scale and architecture have essentially no effect on alignment with human behavioral responses, whereas the training dataset and objective function have a much larger impact. Using a sparse Bayesian model of human conceptual representations, we partition triplets by the concept that distinguishes the two similar images from the odd-one-out, finding that some concepts such as food and animals are well-represented in neural network representations whereas others such as royal or sports-related objects are not. Overall, although models trained on larger, more diverse datasets achieve better alignment with humans than models trained on ImageNet alone, our results indicate that scaling alone is unlikely to be sufficient to train neural networks with conceptual representations that match those used by humans.
Learning Counterfactual Representations for Estimating Individual Dose-Response Curves
Feb 03, 2019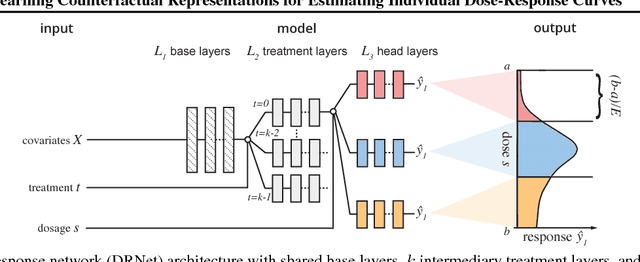
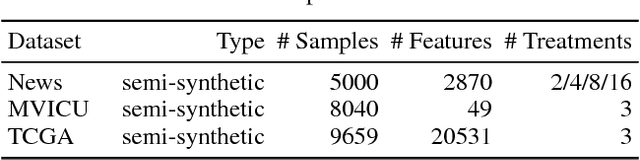
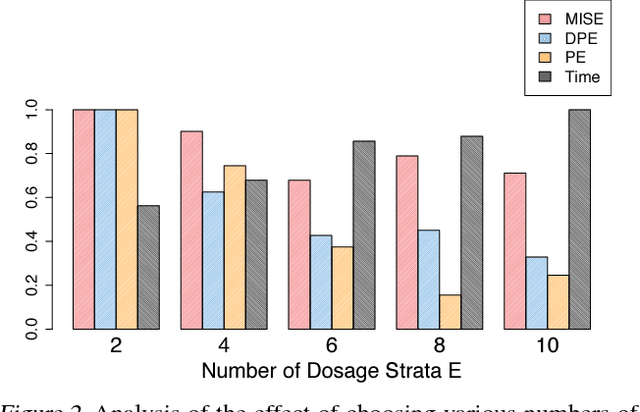
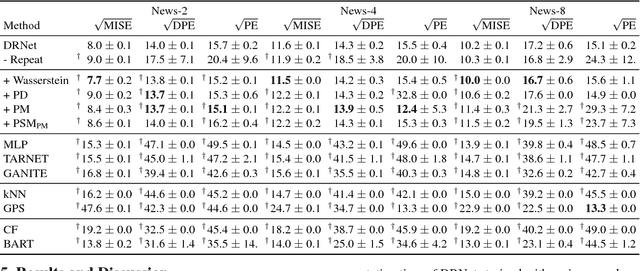
Estimating what would be an individual's potential response to varying levels of exposure to a treatment is of high practical relevance for several important fields, such as healthcare, economics and public policy. However, existing methods for learning to estimate such counterfactual outcomes from observational data are either focused on estimating average dose-response curves, limited to settings in which treatments do not have an associated dosage parameter, or both. Here, we present a novel machine-learning framework towards learning counterfactual representations for estimating individual dose-response curves for any number of treatment options with continuous dosage parameters. Building on the established potential outcomes framework, we introduce new performance metrics, model selection criteria, model architectures, and open benchmarks for estimating individual dose-response curves. Our experiments show that the methods developed in this work set a new state-of-the-art in estimating individual dose-response curves.
Perfect Match: A Simple Method for Learning Representations For Counterfactual Inference With Neural Networks
Nov 01, 2018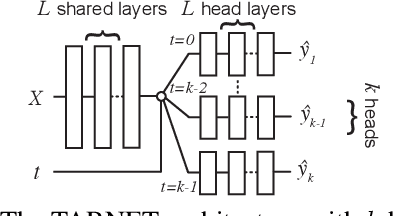
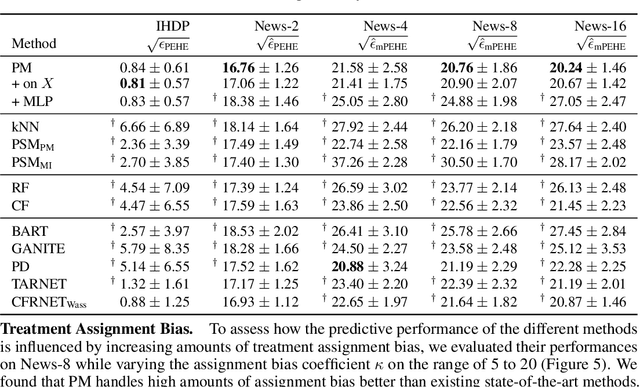
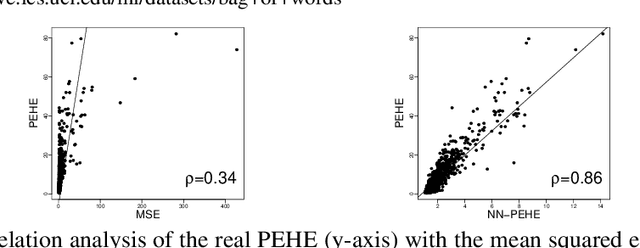
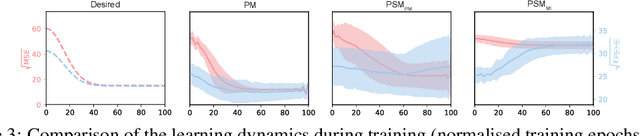
Learning representations for counterfactual inference from observational data is of high practical relevance for many domains, such as healthcare, public policy and economics. Counterfactual inference enables one to answer "What if...?" questions, such as "What would be the outcome if we gave this patient treatment $t_1$?". However, current methods for training neural networks for counterfactual inference on observational data are either overly complex, limited to settings with only two available treatment options, or both. Here, we present Perfect Match (PM), a method for training neural networks for counterfactual inference that is easy to implement, compatible with any architecture, does not add computational complexity or hyperparameters, and extends to any number of treatments. PM is based on the idea of augmenting samples within a minibatch with their propensity-matched nearest neighbours. Our experiments demonstrate that PM outperforms a number of more complex state-of-the-art methods in inferring counterfactual outcomes across several real-world and semi-synthetic datasets.