 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVisual Disentangled Diffusion Autoencoders: Scalable Counterfactual Generation for Foundation Models
Jan 29, 2026Foundation models, despite their robust zero-shot capabilities, remain vulnerable to spurious correlations and 'Clever Hans' strategies. Existing mitigation methods often rely on unavailable group labels or computationally expensive gradient-based adversarial optimization. To address these limitations, we propose Visual Disentangled Diffusion Autoencoders (DiDAE), a novel framework integrating frozen foundation models with disentangled dictionary learning for efficient, gradient-free counterfactual generation directly for the foundation model. DiDAE first edits foundation model embeddings in interpretable disentangled directions of the disentangled dictionary and then decodes them via a diffusion autoencoder. This allows the generation of multiple diverse, disentangled counterfactuals for each factual, much faster than existing baselines, which generate single entangled counterfactuals. When paired with Counterfactual Knowledge Distillation, DiDAE-CFKD achieves state-of-the-art performance in mitigating shortcut learning, improving downstream performance on unbalanced datasets.
Imbalanced Classification through the Lens of Spurious Correlations
Oct 31, 2025Class imbalance poses a fundamental challenge in machine learning, frequently leading to unreliable classification performance. While prior methods focus on data- or loss-reweighting schemes, we view imbalance as a data condition that amplifies Clever Hans (CH) effects by underspecification of minority classes. In a counterfactual explanations-based approach, we propose to leverage Explainable AI to jointly identify and eliminate CH effects emerging under imbalance. Our method achieves competitive classification performance on three datasets and demonstrates how CH effects emerge under imbalance, a perspective largely overlooked by existing approaches.
Towards Desiderata-Driven Design of Visual Counterfactual Explainers
Jun 17, 2025Visual counterfactual explainers (VCEs) are a straightforward and promising approach to enhancing the transparency of image classifiers. VCEs complement other types of explanations, such as feature attribution, by revealing the specific data transformations to which a machine learning model responds most strongly. In this paper, we argue that existing VCEs focus too narrowly on optimizing sample quality or change minimality; they fail to consider the more holistic desiderata for an explanation, such as fidelity, understandability, and sufficiency. To address this shortcoming, we explore new mechanisms for counterfactual generation and investigate how they can help fulfill these desiderata. We combine these mechanisms into a novel 'smooth counterfactual explorer' (SCE) algorithm and demonstrate its effectiveness through systematic evaluations on synthetic and real data.
Diffusion Counterfactuals for Image Regressors
Mar 26, 2025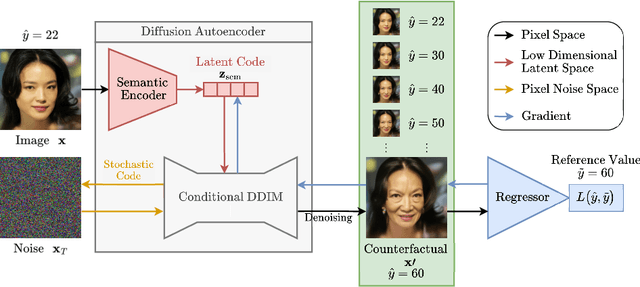


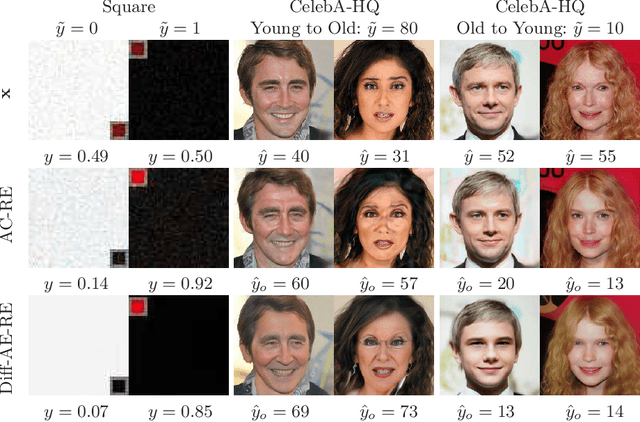
Counterfactual explanations have been successfully applied to create human interpretable explanations for various black-box models. They are handy for tasks in the image domain, where the quality of the explanations benefits from recent advances in generative models. Although counterfactual explanations have been widely applied to classification models, their application to regression tasks remains underexplored. We present two methods to create counterfactual explanations for image regression tasks using diffusion-based generative models to address challenges in sparsity and quality: 1) one based on a Denoising Diffusion Probabilistic Model that operates directly in pixel-space and 2) another based on a Diffusion Autoencoder operating in latent space. Both produce realistic, semantic, and smooth counterfactuals on CelebA-HQ and a synthetic data set, providing easily interpretable insights into the decision-making process of the regression model and reveal spurious correlations. We find that for regression counterfactuals, changes in features depend on the region of the predicted value. Large semantic changes are needed for significant changes in predicted values, making it harder to find sparse counterfactuals than with classifiers. Moreover, pixel space counterfactuals are more sparse while latent space counterfactuals are of higher quality and allow bigger semantic changes.
An Analysis of Human Alignment of Latent Diffusion Models
Mar 13, 2024
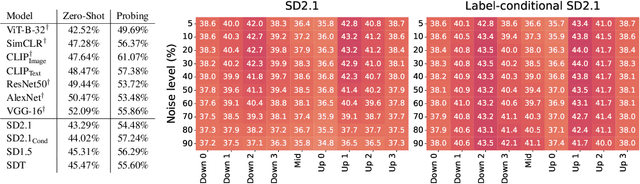


Diffusion models, trained on large amounts of data, showed remarkable performance for image synthesis. They have high error consistency with humans and low texture bias when used for classification. Furthermore, prior work demonstrated the decomposability of their bottleneck layer representations into semantic directions. In this work, we analyze how well such representations are aligned to human responses on a triplet odd-one-out task. We find that despite the aforementioned observations: I) The representational alignment with humans is comparable to that of models trained only on ImageNet-1k. II) The most aligned layers of the denoiser U-Net are intermediate layers and not the bottleneck. III) Text conditioning greatly improves alignment at high noise levels, hinting at the importance of abstract textual information, especially in the early stage of generation.
Towards Fixing Clever-Hans Predictors with Counterfactual Knowledge Distillation
Oct 03, 2023This paper introduces a novel technique called counterfactual knowledge distillation (CFKD) to detect and remove reliance on confounders in deep learning models with the help of human expert feedback. Confounders are spurious features that models tend to rely on, which can result in unexpected errors in regulated or safety-critical domains. The paper highlights the benefit of CFKD in such domains and shows some advantages of counterfactual explanations over other types of explanations. We propose an experiment scheme to quantitatively evaluate the success of CFKD and different teachers that can give feedback to the model. We also introduce a new metric that is better correlated with true test performance than validation accuracy. The paper demonstrates the effectiveness of CFKD on synthetically augmented datasets and on real-world histopathological datasets.
Cycle-Consistent World Models for Domain Independent Latent Imagination
Oct 02, 2021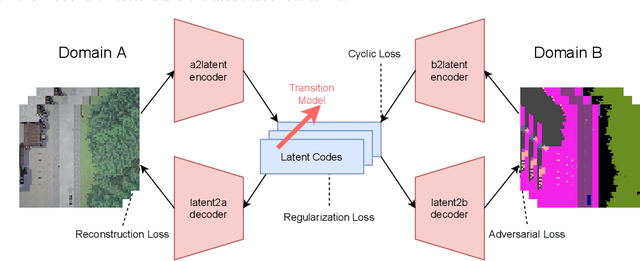


End-to-end autonomous driving seeks to solve the perception, decision, and control problems in an integrated way, which can be easier to generalize at scale and be more adapting to new scenarios. However, high costs and risks make it very hard to train autonomous cars in the real world. Simulations can therefore be a powerful tool to enable training. Due to slightly different observations, agents trained and evaluated solely in simulation often perform well there but have difficulties in real-world environments. To tackle this problem, we propose a novel model-based reinforcement learning approach called Cycleconsistent World Models. Contrary to related approaches, our model can embed two modalities in a shared latent space and thereby learn from samples in one modality (e.g., simulated data) and be used for inference in different domain (e.g., real-world data). Our experiments using different modalities in the CARLA simulator showed that this enables CCWM to outperform state-of-the-art domain adaptation approaches. Furthermore, we show that CCWM can decode a given latent representation into semantically coherent observations in both modalities.