 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Analysis of Human Alignment of Latent Diffusion Models
Paper and Code

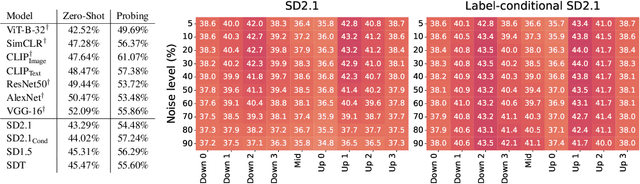


Diffusion models, trained on large amounts of data, showed remarkable performance for image synthesis. They have high error consistency with humans and low texture bias when used for classification. Furthermore, prior work demonstrated the decomposability of their bottleneck layer representations into semantic directions. In this work, we analyze how well such representations are aligned to human responses on a triplet odd-one-out task. We find that despite the aforementioned observations: I) The representational alignment with humans is comparable to that of models trained only on ImageNet-1k. II) The most aligned layers of the denoiser U-Net are intermediate layers and not the bottleneck. III) Text conditioning greatly improves alignment at high noise levels, hinting at the importance of abstract textual information, especially in the early stage of generation.