 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVisual Disentangled Diffusion Autoencoders: Scalable Counterfactual Generation for Foundation Models
Jan 29, 2026Foundation models, despite their robust zero-shot capabilities, remain vulnerable to spurious correlations and 'Clever Hans' strategies. Existing mitigation methods often rely on unavailable group labels or computationally expensive gradient-based adversarial optimization. To address these limitations, we propose Visual Disentangled Diffusion Autoencoders (DiDAE), a novel framework integrating frozen foundation models with disentangled dictionary learning for efficient, gradient-free counterfactual generation directly for the foundation model. DiDAE first edits foundation model embeddings in interpretable disentangled directions of the disentangled dictionary and then decodes them via a diffusion autoencoder. This allows the generation of multiple diverse, disentangled counterfactuals for each factual, much faster than existing baselines, which generate single entangled counterfactuals. When paired with Counterfactual Knowledge Distillation, DiDAE-CFKD achieves state-of-the-art performance in mitigating shortcut learning, improving downstream performance on unbalanced datasets.
Beyond the final layer: Attentive multilayer fusion for vision transformers
Jan 14, 2026With the rise of large-scale foundation models, efficiently adapting them to downstream tasks remains a central challenge. Linear probing, which freezes the backbone and trains a lightweight head, is computationally efficient but often restricted to last-layer representations. We show that task-relevant information is distributed across the network hierarchy rather than solely encoded in any of the last layers. To leverage this distribution of information, we apply an attentive probing mechanism that dynamically fuses representations from all layers of a Vision Transformer. This mechanism learns to identify the most relevant layers for a target task and combines low-level structural cues with high-level semantic abstractions. Across 20 diverse datasets and multiple pretrained foundation models, our method achieves consistent, substantial gains over standard linear probes. Attention heatmaps further reveal that tasks different from the pre-training domain benefit most from intermediate representations. Overall, our findings underscore the value of intermediate layer information and demonstrate a principled, task aware approach for unlocking their potential in probing-based adaptation.
Training objective drives the consistency of representational similarity across datasets
Nov 08, 2024



The Platonic Representation Hypothesis claims that recent foundation models are converging to a shared representation space as a function of their downstream task performance, irrespective of the objectives and data modalities used to train these models. Representational similarity is generally measured for individual datasets and is not necessarily consistent across datasets. Thus, one may wonder whether this convergence of model representations is confounded by the datasets commonly used in machine learning. Here, we propose a systematic way to measure how representational similarity between models varies with the set of stimuli used to construct the representations. We find that the objective function is the most crucial factor in determining the consistency of representational similarities across datasets. Specifically, self-supervised vision models learn representations whose relative pairwise similarities generalize better from one dataset to another compared to those of image classification or image-text models. Moreover, the correspondence between representational similarities and the models' task behavior is dataset-dependent, being most strongly pronounced for single-domain datasets. Our work provides a framework for systematically measuring similarities of model representations across datasets and linking those similarities to differences in task behavior.
Enhancing Brain Source Reconstruction through Physics-Informed 3D Neural Networks
Oct 31, 2024Reconstructing brain sources is a fundamental challenge in neuroscience, crucial for understanding brain function and dysfunction. Electroencephalography (EEG) signals have a high temporal resolution. However, identifying the correct spatial location of brain sources from these signals remains difficult due to the ill-posed structure of the problem. Traditional methods predominantly rely on manually crafted priors, missing the flexibility of data-driven learning, while recent deep learning approaches focus on end-to-end learning, typically using the physical information of the forward model only for generating training data. We propose the novel hybrid method 3D-PIUNet for EEG source localization that effectively integrates the strengths of traditional and deep learning techniques. 3D-PIUNet starts from an initial physics-informed estimate by using the pseudo inverse to map from measurements to source space. Secondly, by viewing the brain as a 3D volume, we use a 3D convolutional U-Net to capture spatial dependencies and refine the solution according to the learned data prior. Training the model relies on simulated pseudo-realistic brain source data, covering different source distributions. Trained on this data, our model significantly improves spatial accuracy, demonstrating superior performance over both traditional and end-to-end data-driven methods. Additionally, we validate our findings with real EEG data from a visual task, where 3D-PIUNet successfully identifies the visual cortex and reconstructs the expected temporal behavior, thereby showcasing its practical applicability.
An Analysis of Human Alignment of Latent Diffusion Models
Mar 13, 2024
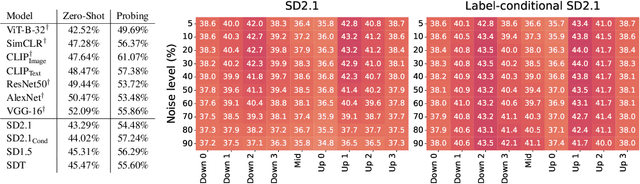


Diffusion models, trained on large amounts of data, showed remarkable performance for image synthesis. They have high error consistency with humans and low texture bias when used for classification. Furthermore, prior work demonstrated the decomposability of their bottleneck layer representations into semantic directions. In this work, we analyze how well such representations are aligned to human responses on a triplet odd-one-out task. We find that despite the aforementioned observations: I) The representational alignment with humans is comparable to that of models trained only on ImageNet-1k. II) The most aligned layers of the denoiser U-Net are intermediate layers and not the bottleneck. III) Text conditioning greatly improves alignment at high noise levels, hinting at the importance of abstract textual information, especially in the early stage of generation.
Controlling Fairness and Bias in Dynamic Learning-to-Rank
May 29, 2020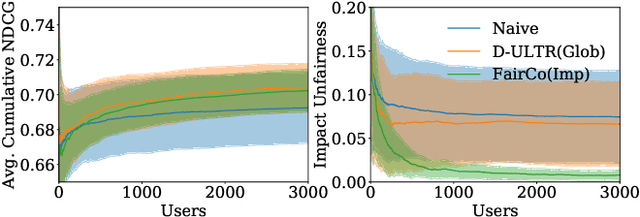

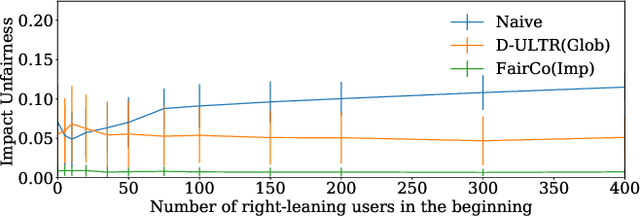
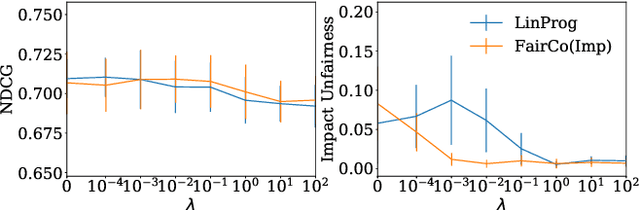
Rankings are the primary interface through which many online platforms match users to items (e.g. news, products, music, video). In these two-sided markets, not only the users draw utility from the rankings, but the rankings also determine the utility (e.g. exposure, revenue) for the item providers (e.g. publishers, sellers, artists, studios). It has already been noted that myopically optimizing utility to the users, as done by virtually all learning-to-rank algorithms, can be unfair to the item providers. We, therefore, present a learning-to-rank approach for explicitly enforcing merit-based fairness guarantees to groups of items (e.g. articles by the same publisher, tracks by the same artist). In particular, we propose a learning algorithm that ensures notions of amortized group fairness, while simultaneously learning the ranking function from implicit feedback data. The algorithm takes the form of a controller that integrates unbiased estimators for both fairness and utility, dynamically adapting both as more data becomes available. In addition to its rigorous theoretical foundation and convergence guarantees, we find empirically that the algorithm is highly practical and robust.