 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVisTIRA: Closing the Image-Text Modality Gap in Visual Math Reasoning via Structured Tool Integration
Jan 20, 2026Vision-language models (VLMs) lag behind text-only language models on mathematical reasoning when the same problems are presented as images rather than text. We empirically characterize this as a modality gap: the same question in text form yields markedly higher accuracy than its visually typeset counterpart, due to compounded failures in reading dense formulas, layout, and mixed symbolic-diagrammatic context. First, we introduce VisTIRA (Vision and Tool-Integrated Reasoning Agent), a tool-integrated reasoning framework that enables structured problem solving by iteratively decomposing a given math problem (as an image) into natural language rationales and executable Python steps to determine the final answer. Second, we build a framework to measure and improve visual math reasoning: a LaTeX-based pipeline that converts chain-of-thought math corpora (e.g., NuminaMath) into challenging image counterparts, and a large set of synthetic tool-use trajectories derived from a real-world, homework-style image dataset (called SnapAsk) for fine-tuning VLMs. Our experiments show that tool-integrated supervision improves image-based reasoning, and OCR grounding can further narrow the gap for smaller models, although its benefit diminishes at scale. These findings highlight that modality gap severity inversely correlates with model size, and that structured reasoning and OCR-based grounding are complementary strategies for advancing visual mathematical reasoning.
RecRec: Algorithmic Recourse for Recommender Systems
Aug 28, 2023



Recommender systems play an essential role in the choices people make in domains such as entertainment, shopping, food, news, employment, and education. The machine learning models underlying these recommender systems are often enormously large and black-box in nature for users, content providers, and system developers alike. It is often crucial for all stakeholders to understand the model's rationale behind making certain predictions and recommendations. This is especially true for the content providers whose livelihoods depend on the recommender system. Drawing motivation from the practitioners' need, in this work, we propose a recourse framework for recommender systems, targeted towards the content providers. Algorithmic recourse in the recommendation setting is a set of actions that, if executed, would modify the recommendations (or ranking) of an item in the desired manner. A recourse suggests actions of the form: "if a feature changes X to Y, then the ranking of that item for a set of users will change to Z." Furthermore, we demonstrate that RecRec is highly effective in generating valid, sparse, and actionable recourses through an empirical evaluation of recommender systems trained on three real-world datasets. To the best of our knowledge, this work is the first to conceptualize and empirically test a generalized framework for generating recourses for recommender systems.
Representation Online Matters: Practical End-to-End Diversification in Search and Recommender Systems
May 26, 2023As the use of online platforms continues to grow across all demographics, users often express a desire to feel represented in the content. To improve representation in search results and recommendations, we introduce end-to-end diversification, ensuring that diverse content flows throughout the various stages of these systems, from retrieval to ranking. We develop, experiment, and deploy scalable diversification mechanisms in multiple production surfaces on the Pinterest platform, including Search, Related Products, and New User Homefeed, to improve the representation of different skin tones in beauty and fashion content. Diversification in production systems includes three components: identifying requests that will trigger diversification, ensuring diverse content is retrieved from the large content corpus during the retrieval stage, and finally, balancing the diversity-utility trade-off in a self-adjusting manner in the ranking stage. Our approaches, which evolved from using Strong-OR logical operator to bucketized retrieval at the retrieval stage and from greedy re-rankers to multi-objective optimization using determinantal point processes for the ranking stage, balances diversity and utility while enabling fast iterations and scalable expansion to diversification over multiple dimensions. Our experiments indicate that these approaches significantly improve diversity metrics, with a neutral to a positive impact on utility metrics and improved user satisfaction, both qualitatively and quantitatively, in production. An accessible PDF of this article is available at https://drive.google.com/file/d/1p5PkqC-sdtX19Y_IAjZCtiSxSEX1IP3q/view
Fairness in Ranking under Uncertainty
Jul 14, 2021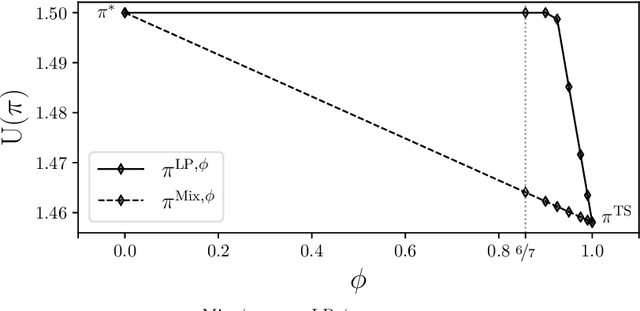
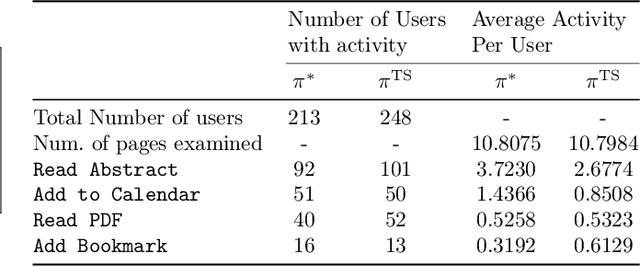
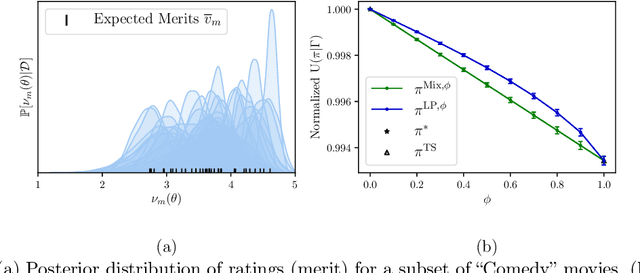
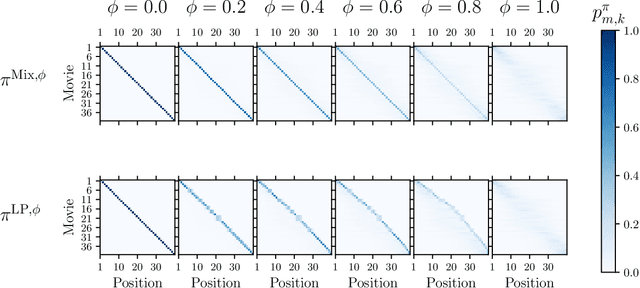
Fairness has emerged as an important consideration in algorithmic decision-making. Unfairness occurs when an agent with higher merit obtains a worse outcome than an agent with lower merit. Our central point is that a primary cause of unfairness is uncertainty. A principal or algorithm making decisions never has access to the agents' true merit, and instead uses proxy features that only imperfectly predict merit (e.g., GPA, star ratings, recommendation letters). None of these ever fully capture an agent's merit; yet existing approaches have mostly been defining fairness notions directly based on observed features and outcomes. Our primary point is that it is more principled to acknowledge and model the uncertainty explicitly. The role of observed features is to give rise to a posterior distribution of the agents' merits. We use this viewpoint to define a notion of approximate fairness in ranking. We call an algorithm $\phi$-fair (for $\phi \in [0,1]$) if it has the following property for all agents $x$ and all $k$: if agent $x$ is among the top $k$ agents with respect to merit with probability at least $\rho$ (according to the posterior merit distribution), then the algorithm places the agent among the top $k$ agents in its ranking with probability at least $\phi \rho$. We show how to compute rankings that optimally trade off approximate fairness against utility to the principal. In addition to the theoretical characterization, we present an empirical analysis of the potential impact of the approach in simulation studies. For real-world validation, we applied the approach in the context of a paper recommendation system that we built and fielded at a large conference.
Controlling Fairness and Bias in Dynamic Learning-to-Rank
May 29, 2020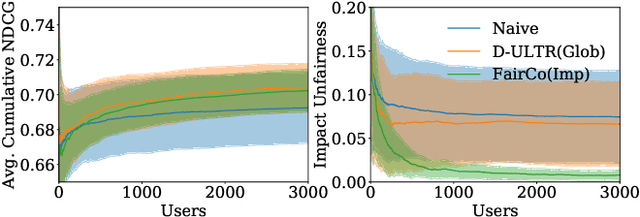

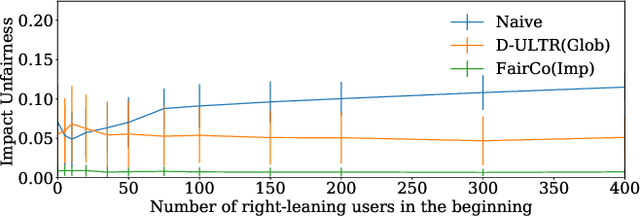
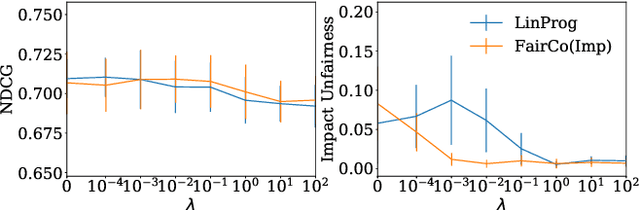
Rankings are the primary interface through which many online platforms match users to items (e.g. news, products, music, video). In these two-sided markets, not only the users draw utility from the rankings, but the rankings also determine the utility (e.g. exposure, revenue) for the item providers (e.g. publishers, sellers, artists, studios). It has already been noted that myopically optimizing utility to the users, as done by virtually all learning-to-rank algorithms, can be unfair to the item providers. We, therefore, present a learning-to-rank approach for explicitly enforcing merit-based fairness guarantees to groups of items (e.g. articles by the same publisher, tracks by the same artist). In particular, we propose a learning algorithm that ensures notions of amortized group fairness, while simultaneously learning the ranking function from implicit feedback data. The algorithm takes the form of a controller that integrates unbiased estimators for both fairness and utility, dynamically adapting both as more data becomes available. In addition to its rigorous theoretical foundation and convergence guarantees, we find empirically that the algorithm is highly practical and robust.
Policy Learning for Fairness in Ranking
Feb 11, 2019
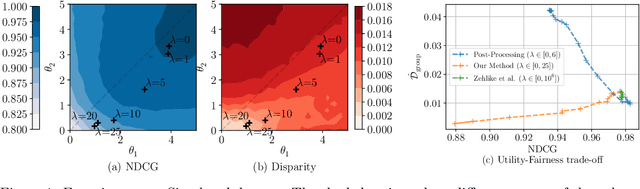
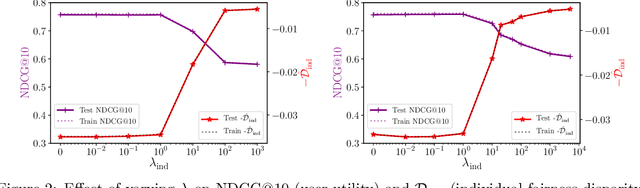
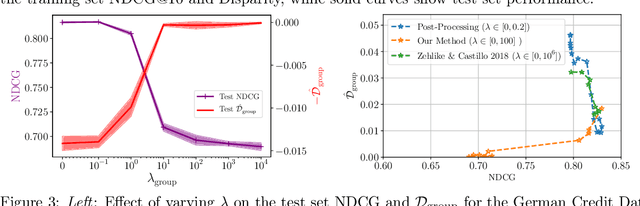
Conventional Learning-to-Rank (LTR) methods optimize the utility of the rankings to the users, but they are oblivious to their impact on the ranked items. However, there has been a growing understanding that the latter is important to consider for a wide range of ranking applications (e.g. online marketplaces, job placement, admissions). To address this need, we propose a general LTR framework that can optimize a wide range of utility metrics (e.g. NDCG) while satisfying fairness of exposure constraints with respect to the items. This framework expands the class of learnable ranking functions to stochastic ranking policies, which provides a language for rigorously expressing fairness specifications. Furthermore, we provide a new LTR algorithm called Fair-PG-Rank for directly searching the space of fair ranking policies via a policy-gradient approach. Beyond the theoretical evidence in deriving the framework and the algorithm, we provide empirical results on simulated and real-world datasets verifying the effectiveness of the approach in individual and group-fairness settings.
Recommendations as Treatments: Debiasing Learning and Evaluation
May 27, 2016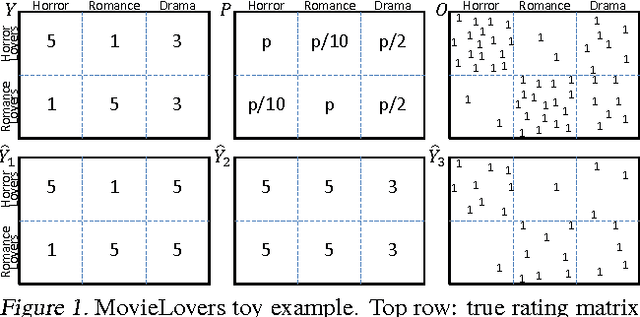

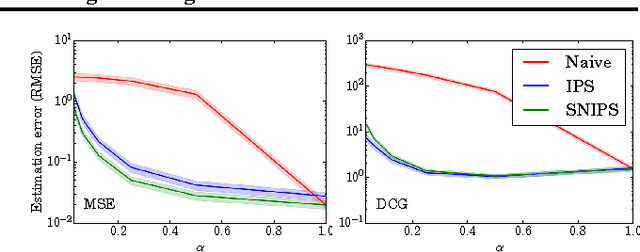
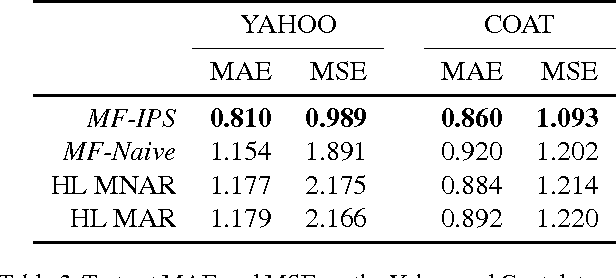
Most data for evaluating and training recommender systems is subject to selection biases, either through self-selection by the users or through the actions of the recommendation system itself. In this paper, we provide a principled approach to handling selection biases, adapting models and estimation techniques from causal inference. The approach leads to unbiased performance estimators despite biased data, and to a matrix factorization method that provides substantially improved prediction performance on real-world data. We theoretically and empirically characterize the robustness of the approach, finding that it is highly practical and scalable.
A Semantic Approach to Summarization
Jun 04, 2014

Sentence extraction based summarization methods has some limitations as it doesn't go into the semantics of the document. Also, it lacks the capability of sentence generation which is intuitive to humans. Here we present a novel method to summarize text documents taking the process to semantic levels with the use of WordNet and other resources, and using a technique for sentence generation. We involve semantic role labeling to get the semantic representation of text and use of segmentation to form clusters of the related pieces of text. Picking out the centroids and sentence generation completes the task. We evaluate our system against human composed summaries and also present an evaluation done by humans to measure the quality attributes of our summaries.