 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFairness in Ranking under Uncertainty
Paper and Code
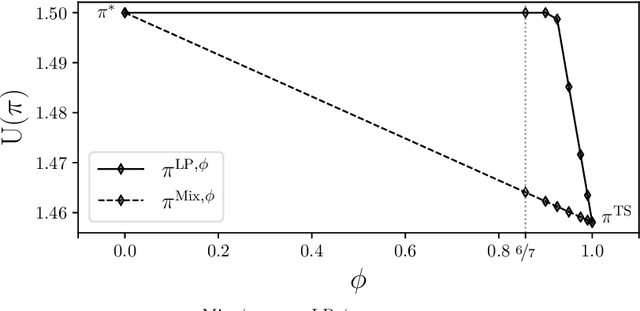
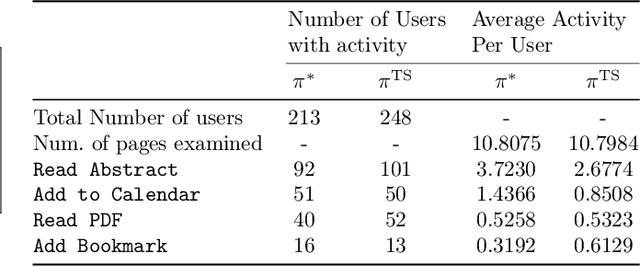
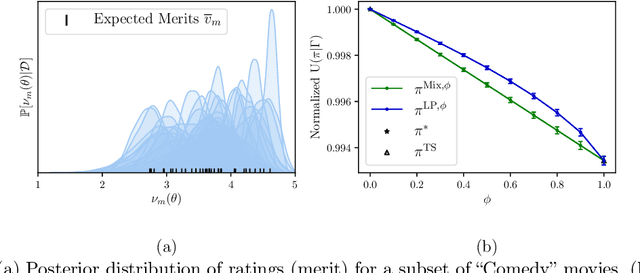
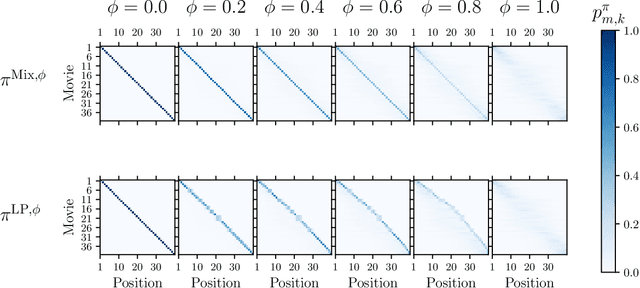
Fairness has emerged as an important consideration in algorithmic decision-making. Unfairness occurs when an agent with higher merit obtains a worse outcome than an agent with lower merit. Our central point is that a primary cause of unfairness is uncertainty. A principal or algorithm making decisions never has access to the agents' true merit, and instead uses proxy features that only imperfectly predict merit (e.g., GPA, star ratings, recommendation letters). None of these ever fully capture an agent's merit; yet existing approaches have mostly been defining fairness notions directly based on observed features and outcomes. Our primary point is that it is more principled to acknowledge and model the uncertainty explicitly. The role of observed features is to give rise to a posterior distribution of the agents' merits. We use this viewpoint to define a notion of approximate fairness in ranking. We call an algorithm $\phi$-fair (for $\phi \in [0,1]$) if it has the following property for all agents $x$ and all $k$: if agent $x$ is among the top $k$ agents with respect to merit with probability at least $\rho$ (according to the posterior merit distribution), then the algorithm places the agent among the top $k$ agents in its ranking with probability at least $\phi \rho$. We show how to compute rankings that optimally trade off approximate fairness against utility to the principal. In addition to the theoretical characterization, we present an empirical analysis of the potential impact of the approach in simulation studies. For real-world validation, we applied the approach in the context of a paper recommendation system that we built and fielded at a large conference.