 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRepresentation Online Matters: Practical End-to-End Diversification in Search and Recommender Systems
May 26, 2023As the use of online platforms continues to grow across all demographics, users often express a desire to feel represented in the content. To improve representation in search results and recommendations, we introduce end-to-end diversification, ensuring that diverse content flows throughout the various stages of these systems, from retrieval to ranking. We develop, experiment, and deploy scalable diversification mechanisms in multiple production surfaces on the Pinterest platform, including Search, Related Products, and New User Homefeed, to improve the representation of different skin tones in beauty and fashion content. Diversification in production systems includes three components: identifying requests that will trigger diversification, ensuring diverse content is retrieved from the large content corpus during the retrieval stage, and finally, balancing the diversity-utility trade-off in a self-adjusting manner in the ranking stage. Our approaches, which evolved from using Strong-OR logical operator to bucketized retrieval at the retrieval stage and from greedy re-rankers to multi-objective optimization using determinantal point processes for the ranking stage, balances diversity and utility while enabling fast iterations and scalable expansion to diversification over multiple dimensions. Our experiments indicate that these approaches significantly improve diversity metrics, with a neutral to a positive impact on utility metrics and improved user satisfaction, both qualitatively and quantitatively, in production. An accessible PDF of this article is available at https://drive.google.com/file/d/1p5PkqC-sdtX19Y_IAjZCtiSxSEX1IP3q/view
Recommending Dream Jobs in a Biased Real World
May 10, 2019



Machine learning models learn what we teach them to learn. Machine learning is at the heart of recommender systems. If a machine learning model is trained on biased data, the resulting recommender system may reflect the biases in its recommendations. Biases arise at different stages in a recommender system, from existing societal biases in the data such as the professional gender gap, to biases introduced by the data collection or modeling processes. These biases impact the performance of various components of recommender systems, from offline training, to evaluation and online serving of recommendations in production systems. Specific techniques can help reduce bias at each stage of a recommender system. Reducing bias in our recommender systems is crucial to successfully recommending dream jobs to hundreds of millions members worldwide, while being true to LinkedIn's vision: "To create economic opportunity for every member of the global workforce".
* Accepted and presented at Grace Hopper Conference, GHC 2017
A relevance-scalability-interpretability tradeoff with temporally evolving user personas
Sep 13, 2017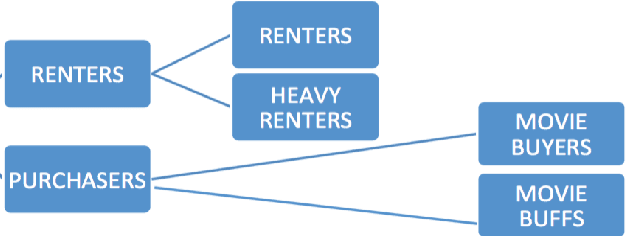
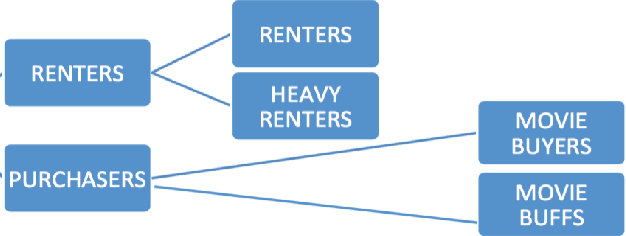
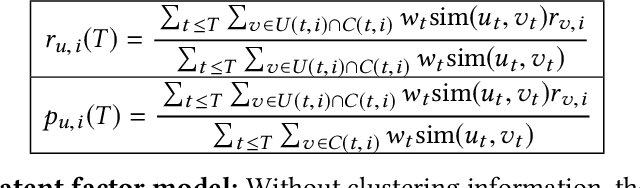
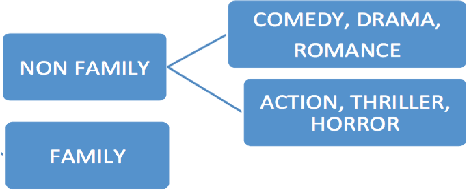
The current work characterizes the users of a VoD streaming space through user-personas based on a tenure timeline and temporal behavioral features in the absence of explicit user profiles. A combination of tenure timeline and temporal characteristics caters to business needs of understanding the evolution and phases of user behavior as their accounts age. The personas constructed in this work successfully represent both dominant and niche characterizations while providing insightful maturation of user behavior in the system. The two major highlights of our personas are demonstration of stability along tenure timelines on a population level, while exhibiting interesting migrations between labels on an individual granularity and clear interpretability of user labels. Finally, we show a trade-off between an indispensable trio of guarantees, relevance-scalability-interpretability by using summary information from personas in a CTR (Click through rate) predictive model. The proposed method of uncovering latent personas, consequent insights from these and application of information from personas to predictive models are broadly applicable to other streaming based products.
Sequential Relevance Maximization with Binary Feedback
Mar 06, 2015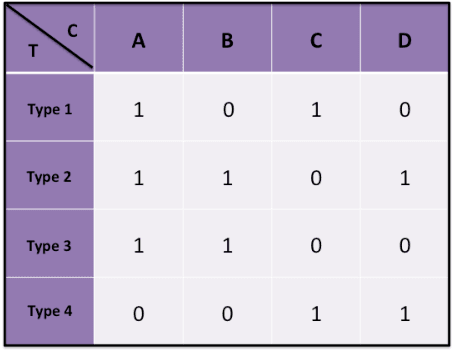
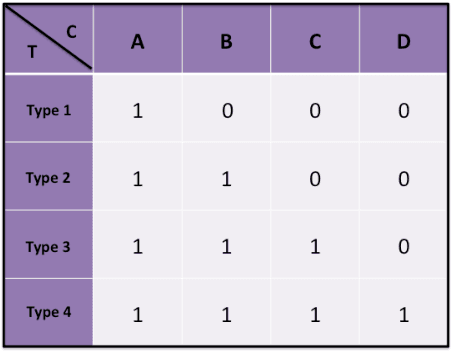
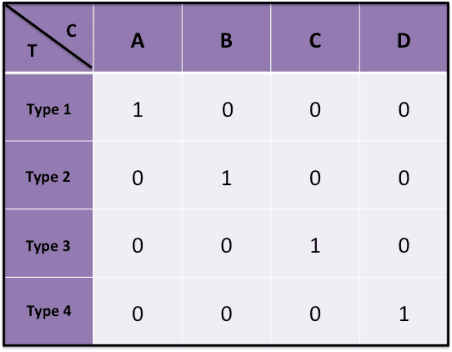
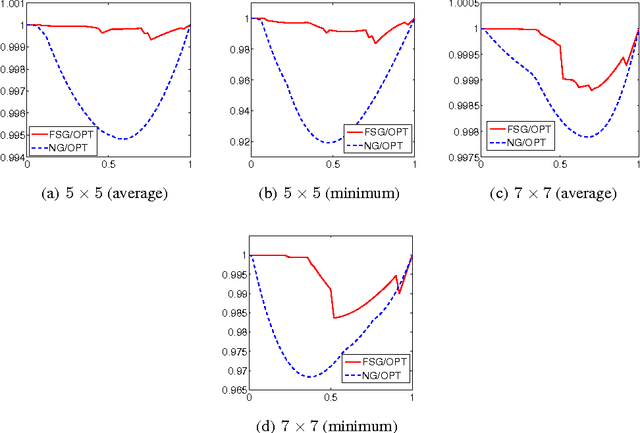
Motivated by online settings where users can provide explicit feedback about the relevance of products that are sequentially presented to them, we look at the recommendation process as a problem of dynamically optimizing this relevance feedback. Such an algorithm optimizes the fine tradeoff between presenting the products that are most likely to be relevant, and learning the preferences of the user so that more relevant recommendations can be made in the future. We assume a standard predictive model inspired by collaborative filtering, in which a user is sampled from a distribution over a set of possible types. For every product category, each type has an associated relevance feedback that is assumed to be binary: the category is either relevant or irrelevant. Assuming that the user stays for each additional recommendation opportunity with probability $\beta$ independent of the past, the problem is to find a policy that maximizes the expected number of recommendations that are deemed relevant in a session. We analyze this problem and prove key structural properties of the optimal policy. Based on these properties, we first present an algorithm that strikes a balance between recursion and dynamic programming to compute this policy. We further propose and analyze two heuristic policies: a `farsighted' greedy policy that attains at least $1-\beta$ factor of the optimal payoff, and a naive greedy policy that attains at least $\frac{1-\beta}{1+\beta}$ factor of the optimal payoff in the worst case. Extensive simulations show that these heuristics are very close to optimal in practice.
Guess Who Rated This Movie: Identifying Users Through Subspace Clustering
Aug 09, 2014
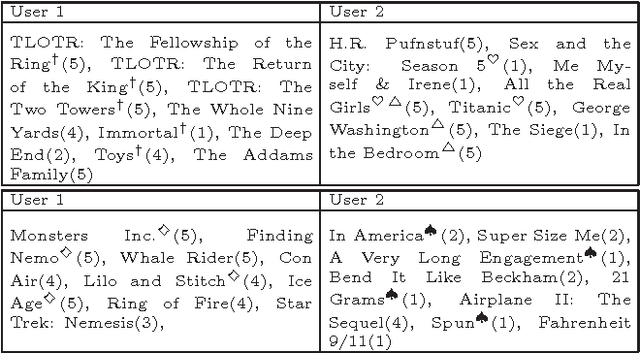

It is often the case that, within an online recommender system, multiple users share a common account. Can such shared accounts be identified solely on the basis of the userprovided ratings? Once a shared account is identified, can the different users sharing it be identified as well? Whenever such user identification is feasible, it opens the way to possible improvements in personalized recommendations, but also raises privacy concerns. We develop a model for composite accounts based on unions of linear subspaces, and use subspace clustering for carrying out the identification task. We show that a significant fraction of such accounts is identifiable in a reliable manner, and illustrate potential uses for personalized recommendation.
Privacy Tradeoffs in Predictive Analytics
Mar 31, 2014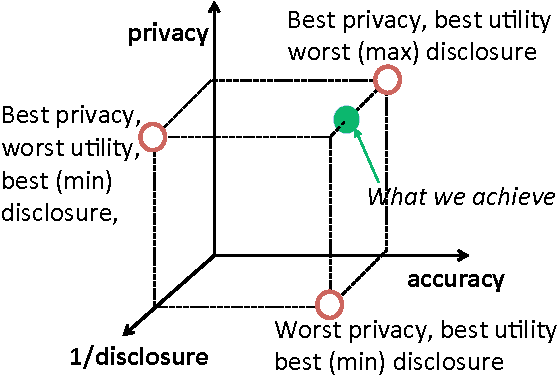
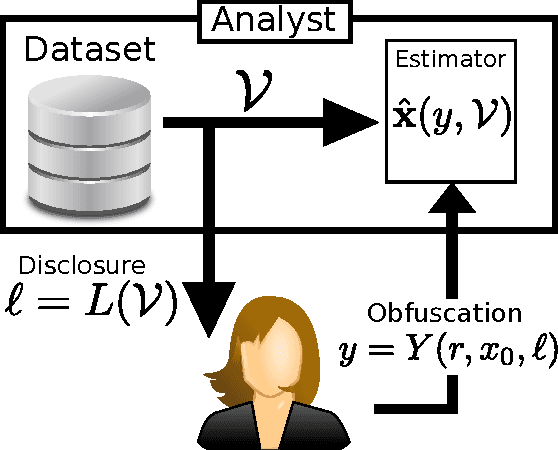
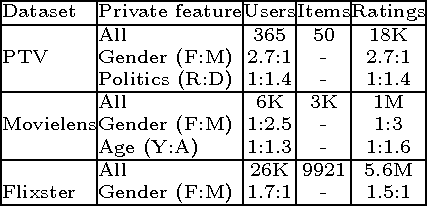
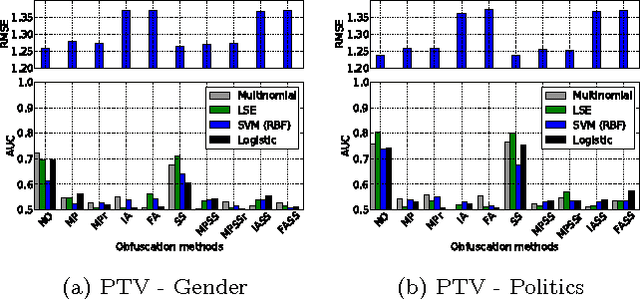
Online services routinely mine user data to predict user preferences, make recommendations, and place targeted ads. Recent research has demonstrated that several private user attributes (such as political affiliation, sexual orientation, and gender) can be inferred from such data. Can a privacy-conscious user benefit from personalization while simultaneously protecting her private attributes? We study this question in the context of a rating prediction service based on matrix factorization. We construct a protocol of interactions between the service and users that has remarkable optimality properties: it is privacy-preserving, in that no inference algorithm can succeed in inferring a user's private attribute with a probability better than random guessing; it has maximal accuracy, in that no other privacy-preserving protocol improves rating prediction; and, finally, it involves a minimal disclosure, as the prediction accuracy strictly decreases when the service reveals less information. We extensively evaluate our protocol using several rating datasets, demonstrating that it successfully blocks the inference of gender, age and political affiliation, while incurring less than 5% decrease in the accuracy of rating prediction.
Identifying Users From Their Rating Patterns
Jul 26, 2012
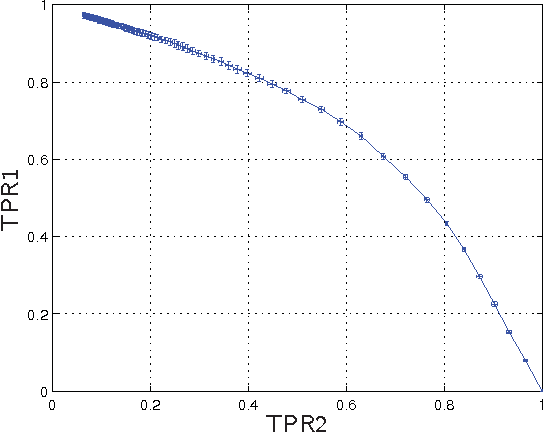


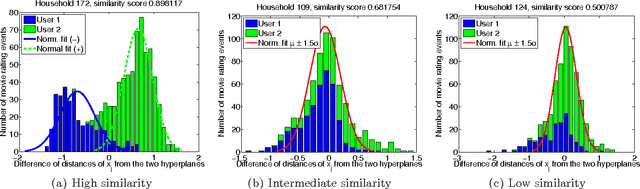
This paper reports on our analysis of the 2011 CAMRa Challenge dataset (Track 2) for context-aware movie recommendation systems. The train dataset comprises 4,536,891 ratings provided by 171,670 users on 23,974$ movies, as well as the household groupings of a subset of the users. The test dataset comprises 5,450 ratings for which the user label is missing, but the household label is provided. The challenge required to identify the user labels for the ratings in the test set. Our main finding is that temporal information (time labels of the ratings) is significantly more useful for achieving this objective than the user preferences (the actual ratings). Using a model that leverages on this fact, we are able to identify users within a known household with an accuracy of approximately 96% (i.e. misclassification rate around 4%).