 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelective Inference for Time-Varying Effect Moderation
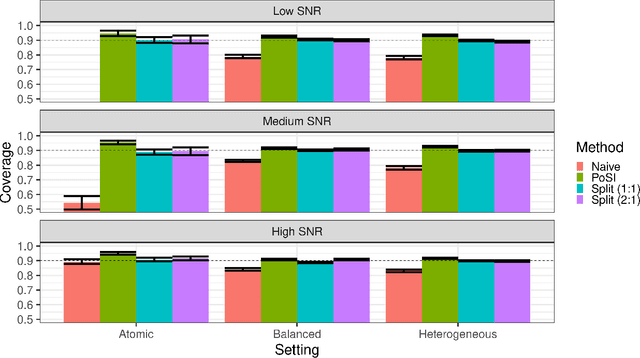
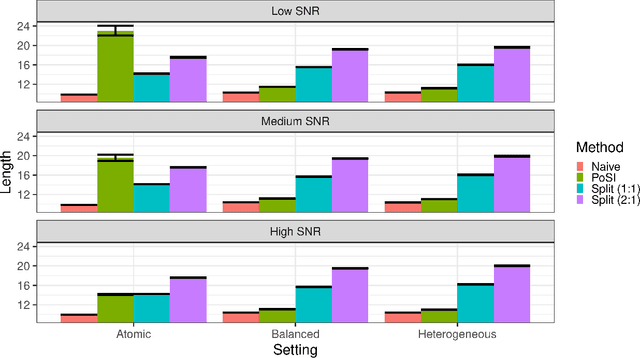
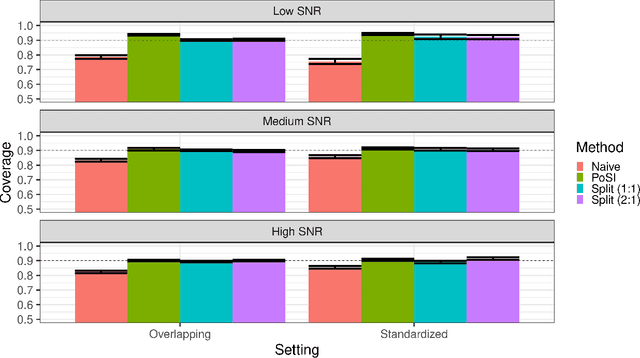
Nov 24, 2024Causal effect moderation investigates how the effect of interventions (or treatments) on outcome variables changes based on observed characteristics of individuals, known as potential effect moderators. With advances in data collection, datasets containing many observed features as potential moderators have become increasingly common. High-dimensional analyses often lack interpretability, with important moderators masked by noise, while low-dimensional, marginal analyses yield many false positives due to strong correlations with true moderators. In this paper, we propose a two-step method for selective inference on time-varying causal effect moderation that addresses the limitations of both high-dimensional and marginal analyses. Our method first selects a relatively smaller, more interpretable model to estimate a linear causal effect moderation using a Gaussian randomization approach. We then condition on the selection event to construct a pivot, enabling uniformly asymptotic semi-parametric inference in the selected model. Through simulations and real data analyses, we show that our method consistently achieves valid coverage rates, even when existing conditional methods and common sample splitting techniques fail. Moreover, our method yields shorter, bounded intervals, unlike existing methods that may produce infinitely long intervals.
Selective inference using randomized group lasso estimators for general models
Jun 24, 2023Selective inference methods are developed for group lasso estimators for use with a wide class of distributions and loss functions. The method includes the use of exponential family distributions, as well as quasi-likelihood modeling for overdispersed count data, for example, and allows for categorical or grouped covariates as well as continuous covariates. A randomized group-regularized optimization problem is studied. The added randomization allows us to construct a post-selection likelihood which we show to be adequate for selective inference when conditioning on the event of the selection of the grouped covariates. This likelihood also provides a selective point estimator, accounting for the selection by the group lasso. Confidence regions for the regression parameters in the selected model take the form of Wald-type regions and are shown to have bounded volume. The selective inference method for grouped lasso is illustrated on data from the national health and nutrition examination survey while simulations showcase its behaviour and favorable comparison with other methods.
Exact Selective Inference with Randomization
Jan 10, 2023We introduce a pivot for exact selective inference with randomization. Not only does our pivot lead to exact inference in Gaussian regression models, but it is also available in closed form. We reduce the problem of exact selective inference to a bivariate truncated Gaussian distribution. By doing so, we give up some power that is achieved with approximate inference in Panigrahi and Taylor (2022). Yet we always produce narrower confidence intervals than a closely related data-splitting procedure. For popular instances of Gaussian regression, this price -- in terms of power -- in exchange for exact selective inference is demonstrated in simulated experiments and in an HIV drug resistance analysis.
Selective Inference for Sparse Multitask Regression with Applications in Neuroimaging
May 27, 2022
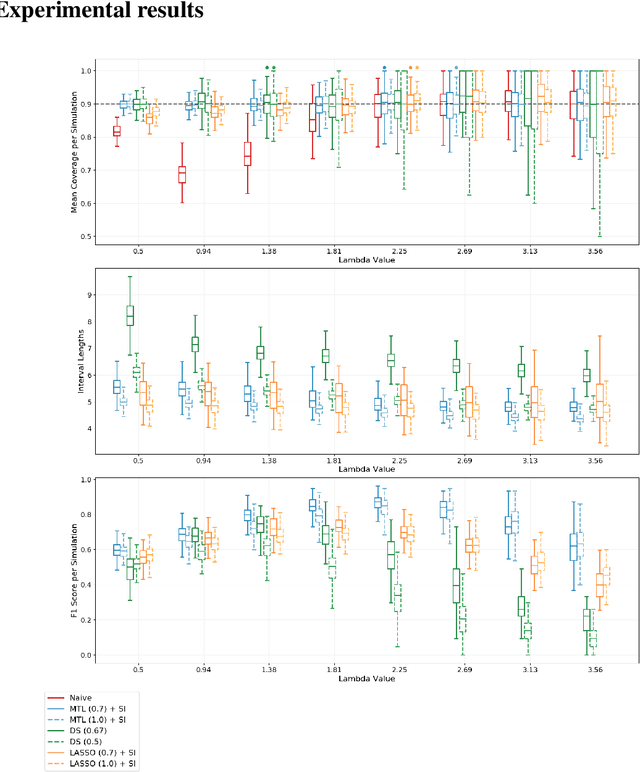
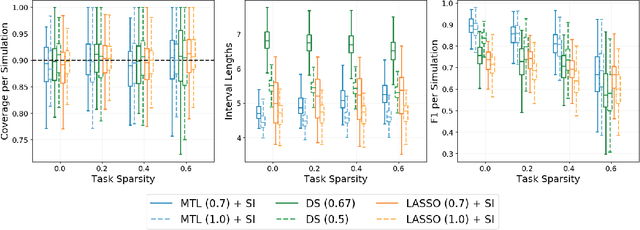
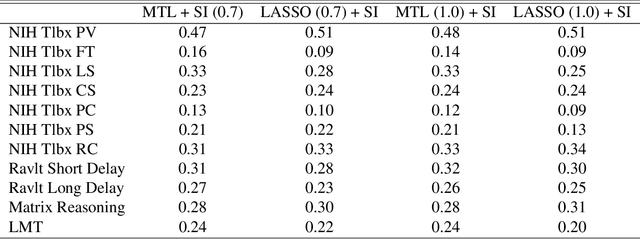
Multi-task learning is frequently used to model a set of related response variables from the same set of features, improving predictive performance and modeling accuracy relative to methods that handle each response variable separately. Despite the potential of multi-task learning to yield more powerful inference than single-task alternatives, prior work in this area has largely omitted uncertainty quantification. Our focus in this paper is a common multi-task problem in neuroimaging, where the goal is to understand the relationship between multiple cognitive task scores (or other subject-level assessments) and brain connectome data collected from imaging. We propose a framework for selective inference to address this problem, with the flexibility to: (i) jointly identify the relevant covariates for each task through a sparsity-inducing penalty, and (ii) conduct valid inference in a model based on the estimated sparsity structure. Our framework offers a new conditional procedure for inference, based on a refinement of the selection event that yields a tractable selection-adjusted likelihood. This gives an approximate system of estimating equations for maximum likelihood inference, solvable via a single convex optimization problem, and enables us to efficiently form confidence intervals with approximately the correct coverage. Applied to both simulated data and data from the Adolescent Cognitive Brain Development (ABCD) study, our selective inference methods yield tighter confidence intervals than commonly used alternatives, such as data splitting. We also demonstrate through simulations that multi-task learning with selective inference can more accurately recover true signals than single-task methods.
Inference post Selection of Group-sparse Regression Models
Dec 31, 2020
Conditional inference provides a rigorous approach to counter bias when data from automated model selections is reused for inference. We develop in this paper a statistically consistent Bayesian framework to assess uncertainties within linear models that are informed by grouped sparsities in covariates. Finding wide applications when genes, proteins, genetic variants, neuroimaging measurements are grouped respectively by their biological pathways, molecular functions, regulatory regions, cognitive roles, these models are selected through a useful class of group-sparse learning algorithms. An adjustment factor to account precisely for the selection of promising groups, deployed with a generalized version of Laplace-type approximations is the centerpiece of our new methods. Accommodating well known group-sparse models such as those selected by the Group LASSO, the overlapping Group LASSO, the sparse Group LASSO etc., we illustrate the efficacy of our methodology in extensive experiments and on data from a human neuroimaging application.
Causal Structure Discovery from Distributions Arising from Mixtures of DAGs
Jan 31, 2020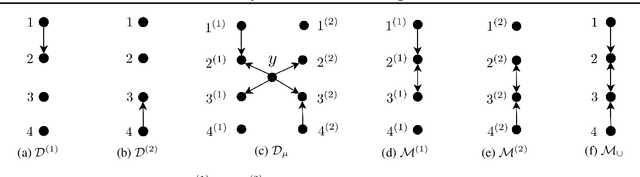
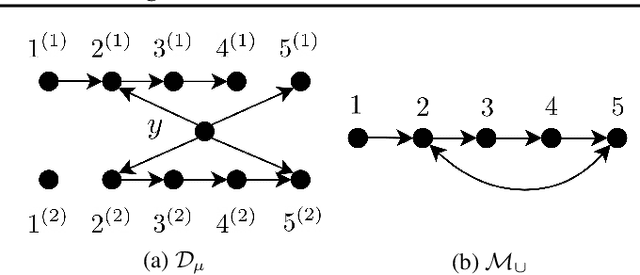
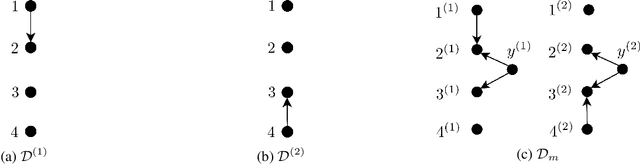
We consider distributions arising from a mixture of causal models, where each model is represented by a directed acyclic graph (DAG). We provide a graphical representation of such mixture distributions and prove that this representation encodes the conditional independence relations of the mixture distribution. We then consider the problem of structure learning based on samples from such distributions. Since the mixing variable is latent, we consider causal structure discovery algorithms such as FCI that can deal with latent variables. We show that such algorithms recover a "union" of the component DAGs and can identify variables whose conditional distribution across the component DAGs vary. We demonstrate our results on synthetic and real data showing that the inferred graph identifies nodes that vary between the different mixture components. As an immediate application, we demonstrate how retrieval of this causal information can be used to cluster samples according to each mixture component.
A relevance-scalability-interpretability tradeoff with temporally evolving user personas
Sep 13, 2017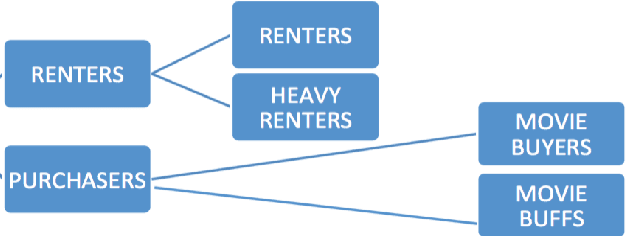
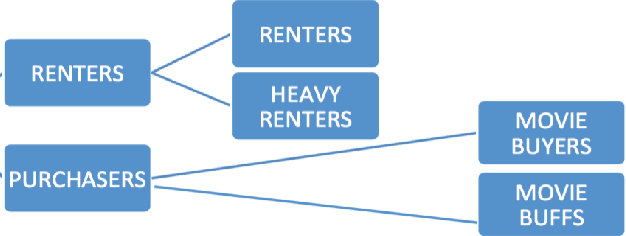
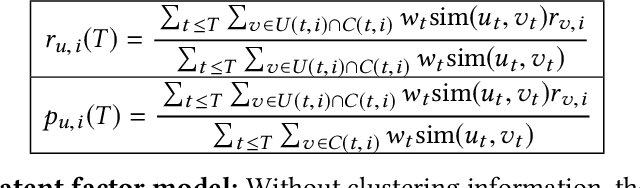
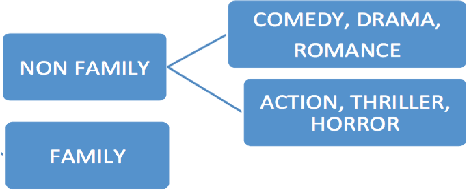
The current work characterizes the users of a VoD streaming space through user-personas based on a tenure timeline and temporal behavioral features in the absence of explicit user profiles. A combination of tenure timeline and temporal characteristics caters to business needs of understanding the evolution and phases of user behavior as their accounts age. The personas constructed in this work successfully represent both dominant and niche characterizations while providing insightful maturation of user behavior in the system. The two major highlights of our personas are demonstration of stability along tenure timelines on a population level, while exhibiting interesting migrations between labels on an individual granularity and clear interpretability of user labels. Finally, we show a trade-off between an indispensable trio of guarantees, relevance-scalability-interpretability by using summary information from personas in a CTR (Click through rate) predictive model. The proposed method of uncovering latent personas, consequent insights from these and application of information from personas to predictive models are broadly applicable to other streaming based products.