 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOne-Click Upgrade from 2D to 3D: Sandwiched RGB-D Video Compression for Stereoscopic Teleconferencing
Apr 15, 2024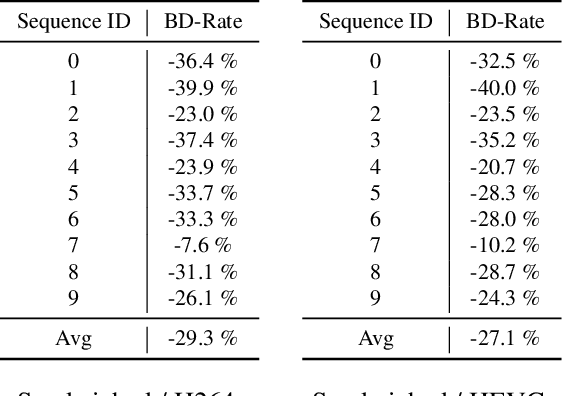
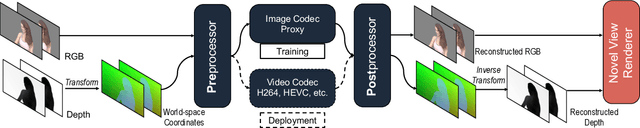
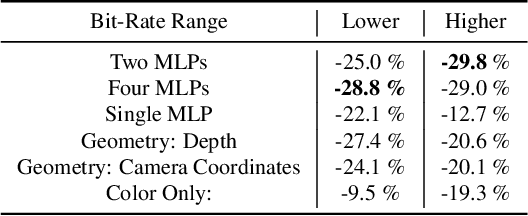
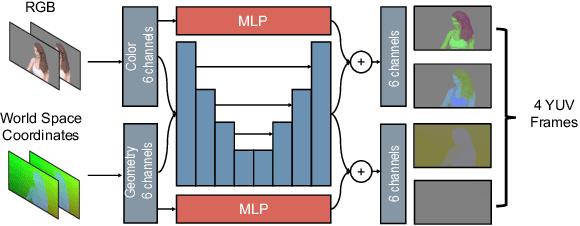
Stereoscopic video conferencing is still challenging due to the need to compress stereo RGB-D video in real-time. Though hardware implementations of standard video codecs such as H.264 / AVC and HEVC are widely available, they are not designed for stereoscopic videos and suffer from reduced quality and performance. Specific multiview or 3D extensions of these codecs are complex and lack efficient implementations. In this paper, we propose a new approach to upgrade a 2D video codec to support stereo RGB-D video compression, by wrapping it with a neural pre- and post-processor pair. The neural networks are end-to-end trained with an image codec proxy, and shown to work with a more sophisticated video codec. We also propose a geometry-aware loss function to improve rendering quality. We train the neural pre- and post-processors on a synthetic 4D people dataset, and evaluate it on both synthetic and real-captured stereo RGB-D videos. Experimental results show that the neural networks generalize well to unseen data and work out-of-box with various video codecs. Our approach saves about 30% bit-rate compared to a conventional video coding scheme and MV-HEVC at the same level of rendering quality from a novel view, without the need of a task-specific hardware upgrade.
Sandwiched Compression: Repurposing Standard Codecs with Neural Network Wrappers
Feb 08, 2024
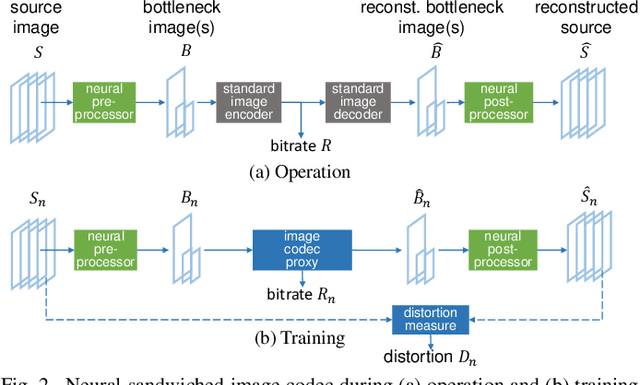
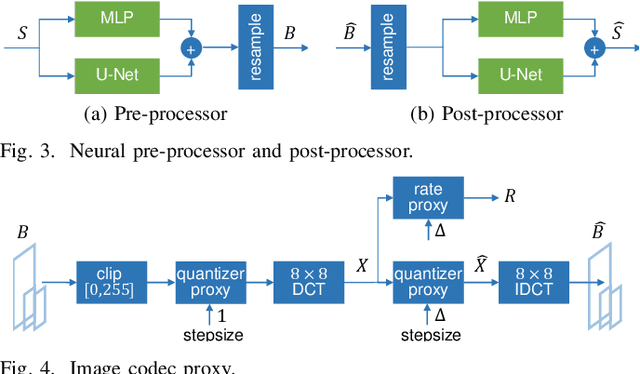
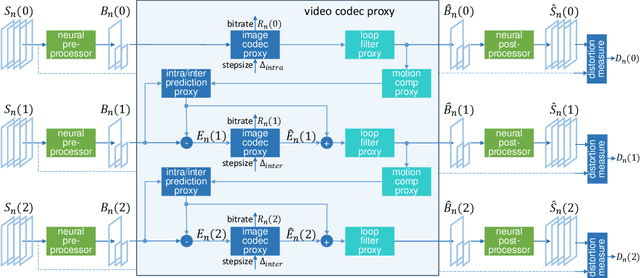
We propose sandwiching standard image and video codecs between pre- and post-processing neural networks. The networks are jointly trained through a differentiable codec proxy to minimize a given rate-distortion loss. This sandwich architecture not only improves the standard codec's performance on its intended content, it can effectively adapt the codec to other types of image/video content and to other distortion measures. Essentially, the sandwich learns to transmit ``neural code images'' that optimize overall rate-distortion performance even when the overall problem is well outside the scope of the codec's design. Through a variety of examples, we apply the sandwich architecture to sources with different numbers of channels, higher resolution, higher dynamic range, and perceptual distortion measures. The results demonstrate substantial improvements (up to 9 dB gains or up to 30\% bitrate reductions) compared to alternative adaptations. We derive VQ equivalents for the sandwich, establish optimality properties, and design differentiable codec proxies approximating current standard codecs. We further analyze model complexity, visual quality under perceptual metrics, as well as sandwich configurations that offer interesting potentials in image/video compression and streaming.
MACS: Mass Conditioned 3D Hand and Object Motion Synthesis
Dec 22, 2023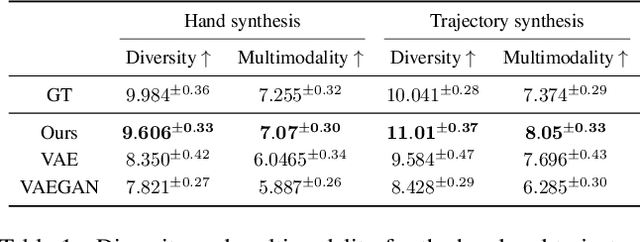
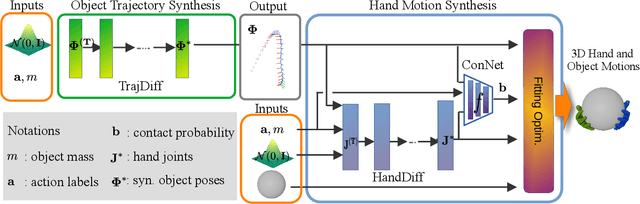
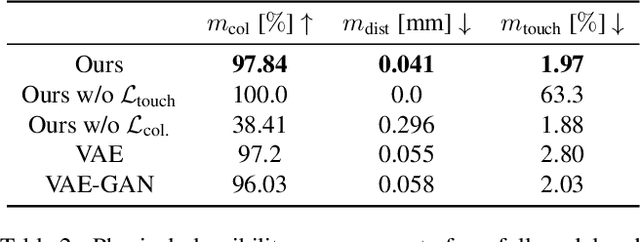

The physical properties of an object, such as mass, significantly affect how we manipulate it with our hands. Surprisingly, this aspect has so far been neglected in prior work on 3D motion synthesis. To improve the naturalness of the synthesized 3D hand object motions, this work proposes MACS the first MAss Conditioned 3D hand and object motion Synthesis approach. Our approach is based on cascaded diffusion models and generates interactions that plausibly adjust based on the object mass and interaction type. MACS also accepts a manually drawn 3D object trajectory as input and synthesizes the natural 3D hand motions conditioned by the object mass. This flexibility enables MACS to be used for various downstream applications, such as generating synthetic training data for ML tasks, fast animation of hands for graphics workflows, and generating character interactions for computer games. We show experimentally that a small-scale dataset is sufficient for MACS to reasonably generalize across interpolated and extrapolated object masses unseen during the training. Furthermore, MACS shows moderate generalization to unseen objects, thanks to the mass-conditioned contact labels generated by our surface contact synthesis model ConNet. Our comprehensive user study confirms that the synthesized 3D hand-object interactions are highly plausible and realistic.
Spectral Graphormer: Spectral Graph-based Transformer for Egocentric Two-Hand Reconstruction using Multi-View Color Images
Aug 21, 2023We propose a novel transformer-based framework that reconstructs two high fidelity hands from multi-view RGB images. Unlike existing hand pose estimation methods, where one typically trains a deep network to regress hand model parameters from single RGB image, we consider a more challenging problem setting where we directly regress the absolute root poses of two-hands with extended forearm at high resolution from egocentric view. As existing datasets are either infeasible for egocentric viewpoints or lack background variations, we create a large-scale synthetic dataset with diverse scenarios and collect a real dataset from multi-calibrated camera setup to verify our proposed multi-view image feature fusion strategy. To make the reconstruction physically plausible, we propose two strategies: (i) a coarse-to-fine spectral graph convolution decoder to smoothen the meshes during upsampling and (ii) an optimisation-based refinement stage at inference to prevent self-penetrations. Through extensive quantitative and qualitative evaluations, we show that our framework is able to produce realistic two-hand reconstructions and demonstrate the generalisation of synthetic-trained models to real data, as well as real-time AR/VR applications.
Sandwiched Video Compression: Efficiently Extending the Reach of Standard Codecs with Neural Wrappers
Mar 20, 2023
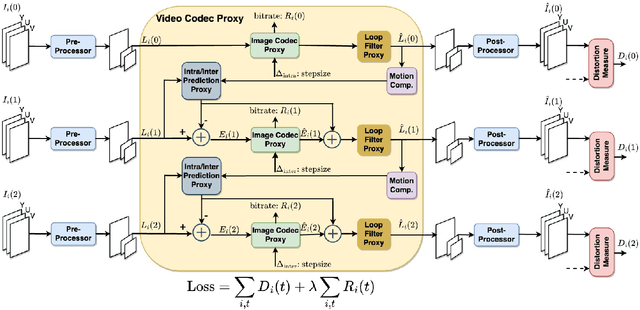

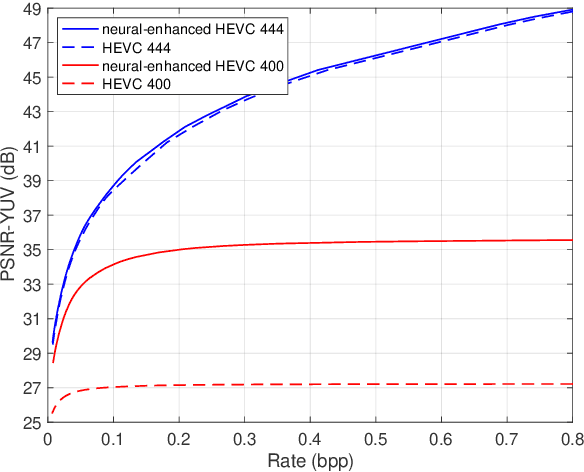
We propose sandwiched video compression -- a video compression system that wraps neural networks around a standard video codec. The sandwich framework consists of a neural pre- and post-processor with a standard video codec between them. The networks are trained jointly to optimize a rate-distortion loss function with the goal of significantly improving over the standard codec in various compression scenarios. End-to-end training in this setting requires a differentiable proxy for the standard video codec, which incorporates temporal processing with motion compensation, inter/intra mode decisions, and in-loop filtering. We propose differentiable approximations to key video codec components and demonstrate that the neural codes of the sandwich lead to significantly better rate-distortion performance compared to compressing the original frames of the input video in two important scenarios. When transporting high-resolution video via low-resolution HEVC, the sandwich system obtains 6.5 dB improvements over standard HEVC. More importantly, using the well-known perceptual similarity metric, LPIPS, we observe $~30 \%$ improvements in rate at the same quality over HEVC. Last but not least we show that pre- and post-processors formed by very modestly-parameterized, light-weight networks can closely approximate these results.
Exact Selective Inference with Randomization
Jan 10, 2023We introduce a pivot for exact selective inference with randomization. Not only does our pivot lead to exact inference in Gaussian regression models, but it is also available in closed form. We reduce the problem of exact selective inference to a bivariate truncated Gaussian distribution. By doing so, we give up some power that is achieved with approximate inference in Panigrahi and Taylor (2022). Yet we always produce narrower confidence intervals than a closely related data-splitting procedure. For popular instances of Gaussian regression, this price -- in terms of power -- in exchange for exact selective inference is demonstrated in simulated experiments and in an HIV drug resistance analysis.
Developing a Series of AI Challenges for the United States Department of the Air Force
Jul 14, 2022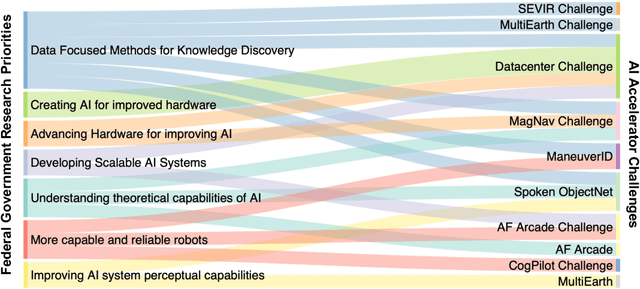

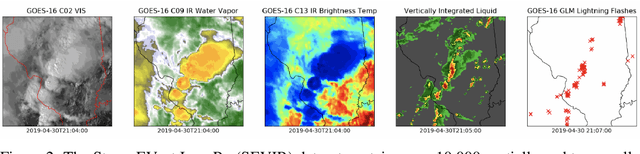
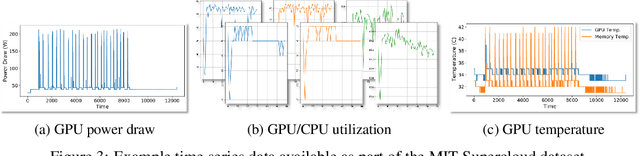
Through a series of federal initiatives and orders, the U.S. Government has been making a concerted effort to ensure American leadership in AI. These broad strategy documents have influenced organizations such as the United States Department of the Air Force (DAF). The DAF-MIT AI Accelerator is an initiative between the DAF and MIT to bridge the gap between AI researchers and DAF mission requirements. Several projects supported by the DAF-MIT AI Accelerator are developing public challenge problems that address numerous Federal AI research priorities. These challenges target priorities by making large, AI-ready datasets publicly available, incentivizing open-source solutions, and creating a demand signal for dual use technologies that can stimulate further research. In this article, we describe these public challenges being developed and how their application contributes to scientific advances.
Black-box Selective Inference via Bootstrapping
Mar 28, 2022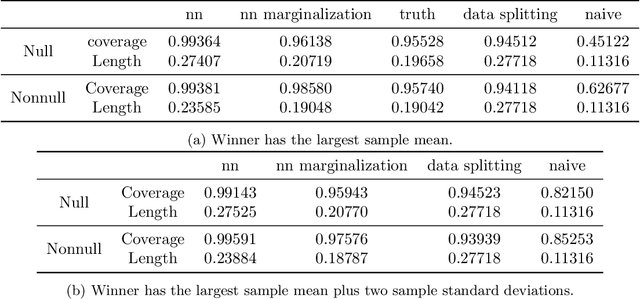
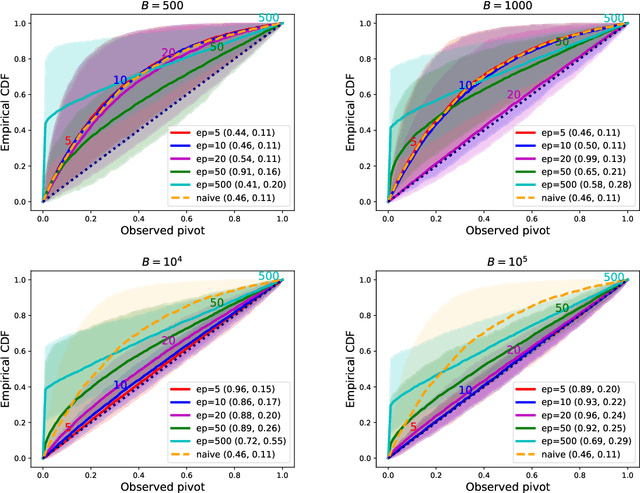
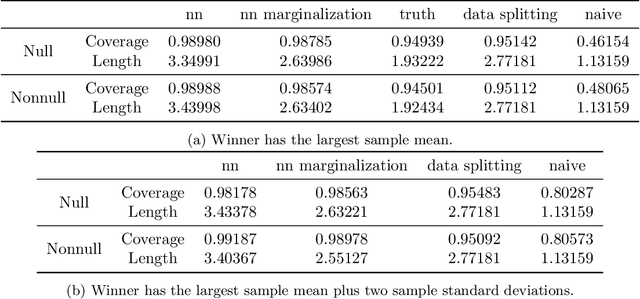
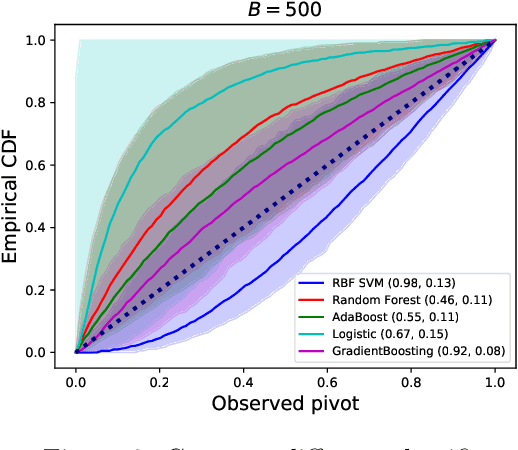
We propose a method for selective inference after a model selection procedure that is potentially a black box. In the conditional post-selection inference framework, a crucial quantity in determining the post-selection distribution of a test statistic is the probability of selecting the model conditional on the statistic. By repeatedly running the model selection procedure on bootstrapped datasets, we can generate training data with binary responses indicating the selection event as well as specially designed covariates, which are then used to learn the selection probability. We prove that the constructed confidence intervals are asymptotically valid if we can learn the selection probability sufficiently well around a neighborhood of the target parameter. The validity of the proposed algorithm is verified by several examples.
VoLux-GAN: A Generative Model for 3D Face Synthesis with HDRI Relighting
Jan 13, 2022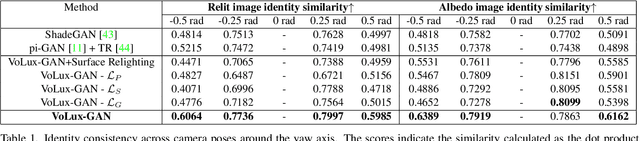
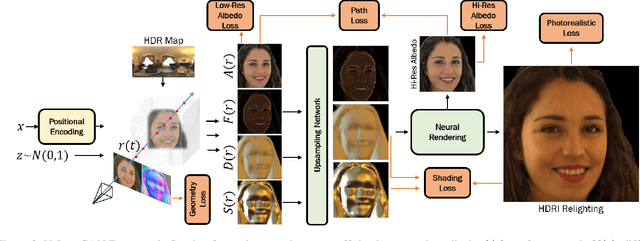
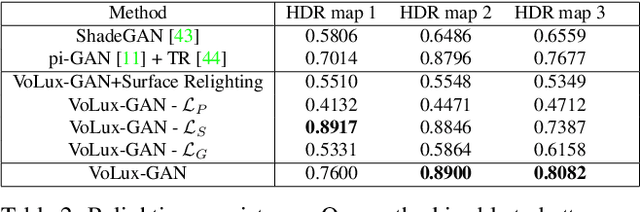

We propose VoLux-GAN, a generative framework to synthesize 3D-aware faces with convincing relighting. Our main contribution is a volumetric HDRI relighting method that can efficiently accumulate albedo, diffuse and specular lighting contributions along each 3D ray for any desired HDR environmental map. Additionally, we show the importance of supervising the image decomposition process using multiple discriminators. In particular, we propose a data augmentation technique that leverages recent advances in single image portrait relighting to enforce consistent geometry, albedo, diffuse and specular components. Multiple experiments and comparisons with other generative frameworks show how our model is a step forward towards photorealistic relightable 3D generative models.
Signal Enhancement for Magnetic Navigation Challenge Problem
Jul 23, 2020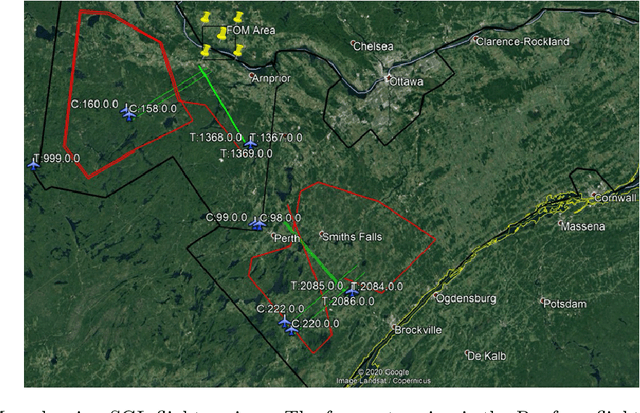


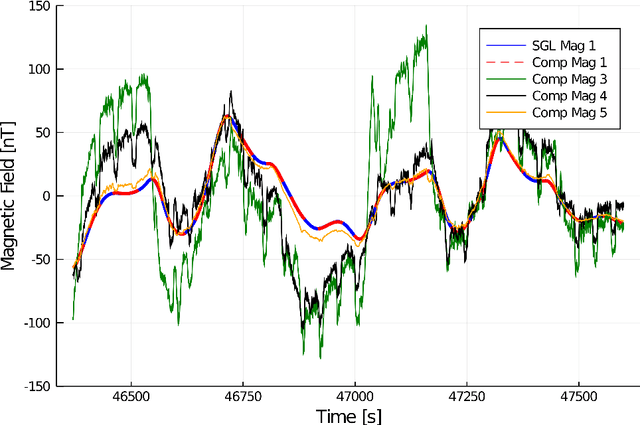
Harnessing the magnetic field of the earth for navigation has shown promise as a viable alternative to other navigation systems. A magnetic navigation system collects its own magnetic field data using a magnetometer and uses magnetic anomaly maps to determine the current location. The greatest challenge with magnetic navigation arises when the magnetic field data from the magnetometer on the navigation system encompass the magnetic field from not just the earth, but also from the vehicle on which it is mounted. It is difficult to separate the earth magnetic anomaly field magnitude, which is crucial for navigation, from the total magnetic field magnitude reading from the sensor. The purpose of this challenge problem is to decouple the earth and aircraft magnetic signals in order to derive a clean signal from which to perform magnetic navigation. Baseline testing on the dataset shows that the earth magnetic field can be extracted from the total magnetic field using machine learning (ML). The challenge is to remove the aircraft magnetic field from the total magnetic field using a trained neural network. These challenges offer an opportunity to construct an effective neural network for removing the aircraft magnetic field from the dataset, using an ML algorithm integrated with physics of magnetic navigation.