 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHyPINO: Multi-Physics Neural Operators via HyperPINNs and the Method of Manufactured Solutions
Sep 05, 2025We present HyPINO, a multi-physics neural operator designed for zero-shot generalization across a broad class of parametric PDEs without requiring task-specific fine-tuning. Our approach combines a Swin Transformer-based hypernetwork with mixed supervision: (i) labeled data from analytical solutions generated via the Method of Manufactured Solutions (MMS), and (ii) unlabeled samples optimized using physics-informed objectives. The model maps PDE parametrizations to target Physics-Informed Neural Networks (PINNs) and can handle linear elliptic, hyperbolic, and parabolic equations in two dimensions with varying source terms, geometries, and mixed Dirichlet/Neumann boundary conditions, including interior boundaries. HyPINO achieves strong zero-shot accuracy on seven benchmark problems from PINN literature, outperforming U-Nets, Poseidon, and Physics-Informed Neural Operators (PINO). Further, we introduce an iterative refinement procedure that compares the physics of the generated PINN to the requested PDE and uses the discrepancy to generate a "delta" PINN. Summing their contributions and repeating this process forms an ensemble whose combined solution progressively reduces the error on six benchmarks and achieves over 100x gain in average $L_2$ loss in the best case, while retaining forward-only inference. Additionally, we evaluate the fine-tuning behavior of PINNs initialized by HyPINO and show that they converge faster and to lower final error than both randomly initialized and Reptile-meta-learned PINNs on five benchmarks, performing on par on the remaining two. Our results highlight the potential of this scalable approach as a foundation for extending neural operators toward solving increasingly complex, nonlinear, and high-dimensional PDE problems with significantly improved accuracy and reduced computational cost.
BiGS: Bidirectional Gaussian Primitives for Relightable 3D Gaussian Splatting
Aug 23, 2024



We present Bidirectional Gaussian Primitives, an image-based novel view synthesis technique designed to represent and render 3D objects with surface and volumetric materials under dynamic illumination. Our approach integrates light intrinsic decomposition into the Gaussian splatting framework, enabling real-time relighting of 3D objects. To unify surface and volumetric material within a cohesive appearance model, we adopt a light- and view-dependent scattering representation via bidirectional spherical harmonics. Our model does not use a specific surface normal-related reflectance function, making it more compatible with volumetric representations like Gaussian splatting, where the normals are undefined. We demonstrate our method by reconstructing and rendering objects with complex materials. Using One-Light-At-a-Time (OLAT) data as input, we can reproduce photorealistic appearances under novel lighting conditions in real time.
Lite2Relight: 3D-aware Single Image Portrait Relighting
Jul 15, 2024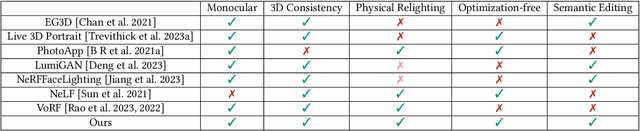
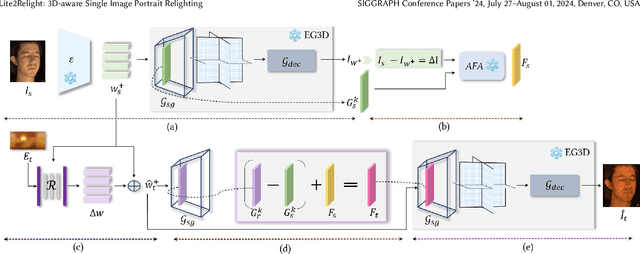
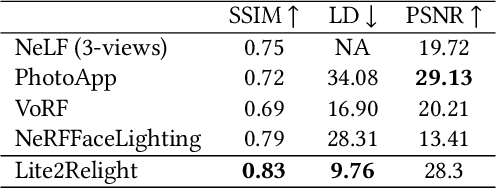

Achieving photorealistic 3D view synthesis and relighting of human portraits is pivotal for advancing AR/VR applications. Existing methodologies in portrait relighting demonstrate substantial limitations in terms of generalization and 3D consistency, coupled with inaccuracies in physically realistic lighting and identity preservation. Furthermore, personalization from a single view is difficult to achieve and often requires multiview images during the testing phase or involves slow optimization processes. This paper introduces Lite2Relight, a novel technique that can predict 3D consistent head poses of portraits while performing physically plausible light editing at interactive speed. Our method uniquely extends the generative capabilities and efficient volumetric representation of EG3D, leveraging a lightstage dataset to implicitly disentangle face reflectance and perform relighting under target HDRI environment maps. By utilizing a pre-trained geometry-aware encoder and a feature alignment module, we map input images into a relightable 3D space, enhancing them with a strong face geometry and reflectance prior. Through extensive quantitative and qualitative evaluations, we show that our method outperforms the state-of-the-art methods in terms of efficacy, photorealism, and practical application. This includes producing 3D-consistent results of the full head, including hair, eyes, and expressions. Lite2Relight paves the way for large-scale adoption of photorealistic portrait editing in various domains, offering a robust, interactive solution to a previously constrained problem. Project page: https://vcai.mpi-inf.mpg.de/projects/Lite2Relight/
MACS: Mass Conditioned 3D Hand and Object Motion Synthesis
Dec 22, 2023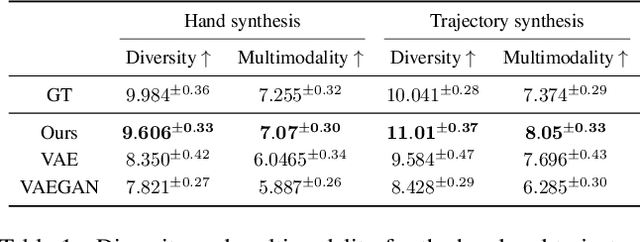
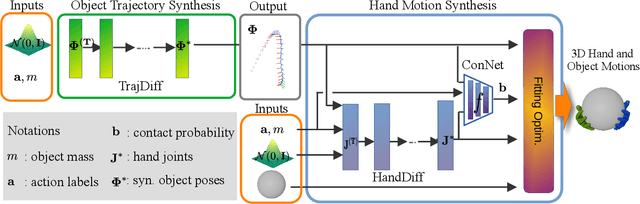
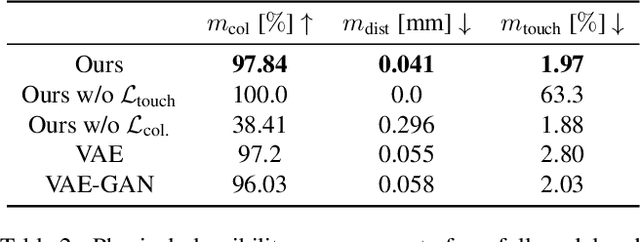

The physical properties of an object, such as mass, significantly affect how we manipulate it with our hands. Surprisingly, this aspect has so far been neglected in prior work on 3D motion synthesis. To improve the naturalness of the synthesized 3D hand object motions, this work proposes MACS the first MAss Conditioned 3D hand and object motion Synthesis approach. Our approach is based on cascaded diffusion models and generates interactions that plausibly adjust based on the object mass and interaction type. MACS also accepts a manually drawn 3D object trajectory as input and synthesizes the natural 3D hand motions conditioned by the object mass. This flexibility enables MACS to be used for various downstream applications, such as generating synthetic training data for ML tasks, fast animation of hands for graphics workflows, and generating character interactions for computer games. We show experimentally that a small-scale dataset is sufficient for MACS to reasonably generalize across interpolated and extrapolated object masses unseen during the training. Furthermore, MACS shows moderate generalization to unseen objects, thanks to the mass-conditioned contact labels generated by our surface contact synthesis model ConNet. Our comprehensive user study confirms that the synthesized 3D hand-object interactions are highly plausible and realistic.
Unsupervised Video Prediction from a Single Frame by Estimating 3D Dynamic Scene Structure
Jun 16, 2021


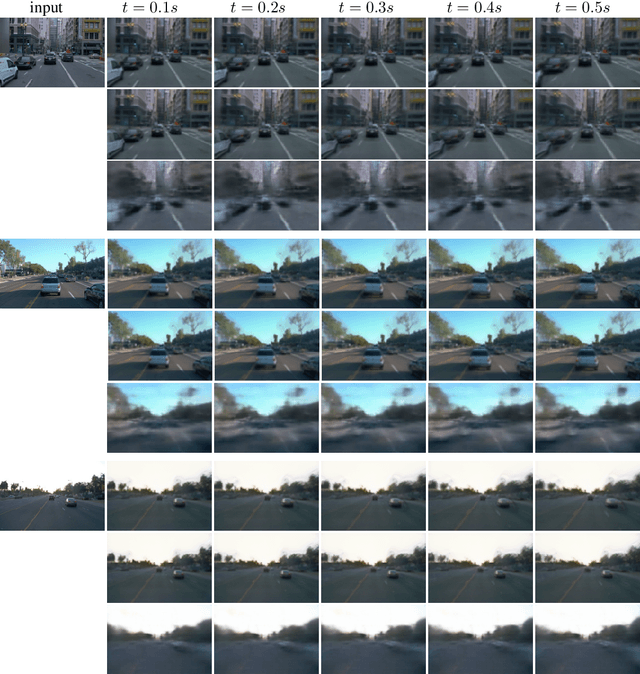
Our goal in this work is to generate realistic videos given just one initial frame as input. Existing unsupervised approaches to this task do not consider the fact that a video typically shows a 3D environment, and that this should remain coherent from frame to frame even as the camera and objects move. We address this by developing a model that first estimates the latent 3D structure of the scene, including the segmentation of any moving objects. It then predicts future frames by simulating the object and camera dynamics, and rendering the resulting views. Importantly, it is trained end-to-end using only the unsupervised objective of predicting future frames, without any 3D information nor segmentation annotations. Experiments on two challenging datasets of natural videos show that our model can estimate 3D structure and motion segmentation from a single frame, and hence generate plausible and varied predictions.
PhotoApp: Photorealistic Appearance Editing of Head Portraits
Mar 13, 2021
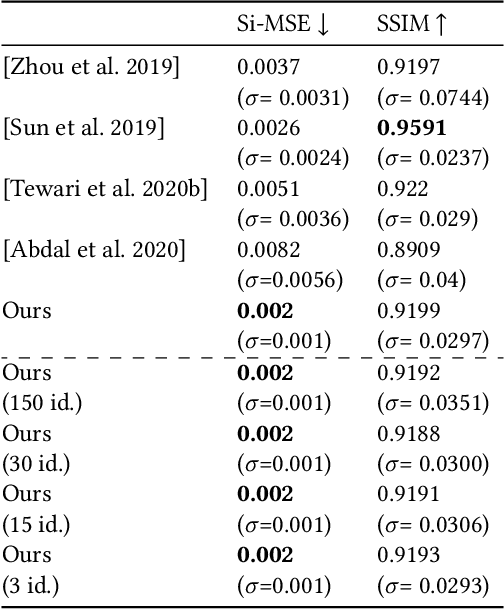
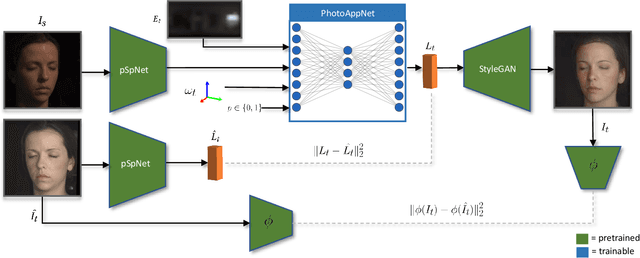
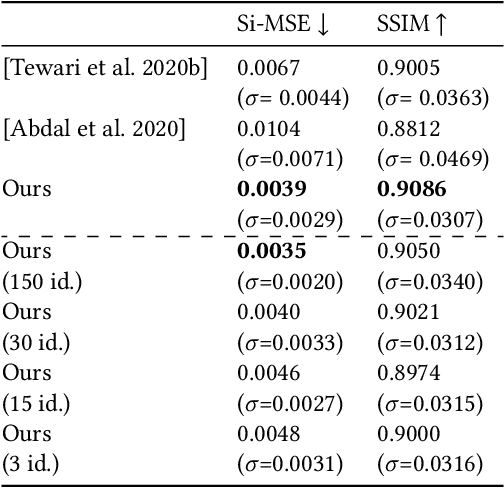
Photorealistic editing of portraits is a challenging task as humans are very sensitive to inconsistencies in faces. We present an approach for high-quality intuitive editing of the camera viewpoint and scene illumination in a portrait image. This requires our method to capture and control the full reflectance field of the person in the image. Most editing approaches rely on supervised learning using training data captured with setups such as light and camera stages. Such datasets are expensive to acquire, not readily available and do not capture all the rich variations of in-the-wild portrait images. In addition, most supervised approaches only focus on relighting, and do not allow camera viewpoint editing. Thus, they only capture and control a subset of the reflectance field. Recently, portrait editing has been demonstrated by operating in the generative model space of StyleGAN. While such approaches do not require direct supervision, there is a significant loss of quality when compared to the supervised approaches. In this paper, we present a method which learns from limited supervised training data. The training images only include people in a fixed neutral expression with eyes closed, without much hair or background variations. Each person is captured under 150 one-light-at-a-time conditions and under 8 camera poses. Instead of training directly in the image space, we design a supervised problem which learns transformations in the latent space of StyleGAN. This combines the best of supervised learning and generative adversarial modeling. We show that the StyleGAN prior allows for generalisation to different expressions, hairstyles and backgrounds. This produces high-quality photorealistic results for in-the-wild images and significantly outperforms existing methods. Our approach can edit the illumination and pose simultaneously, and runs at interactive rates.
Computational Design of Cold Bent Glass Façades
Sep 08, 2020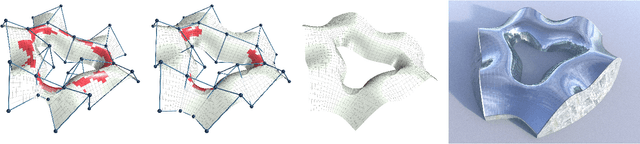


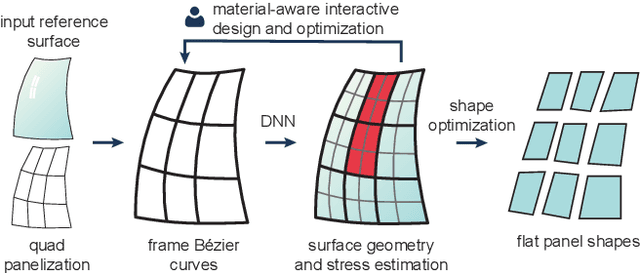
Cold bent glass is a promising and cost-efficient method for realizing doubly curved glass fa\c{c}ades. They are produced by attaching planar glass sheets to curved frames and require keeping the occurring stress within safe limits. However, it is very challenging to navigate the design space of cold bent glass panels due to the fragility of the material, which impedes the form-finding for practically feasible and aesthetically pleasing cold bent glass fa\c{c}ades. We propose an interactive, data-driven approach for designing cold bent glass fa\c{c}ades that can be seamlessly integrated into a typical architectural design pipeline. Our method allows non-expert users to interactively edit a parametric surface while providing real-time feedback on the deformed shape and maximum stress of cold bent glass panels. Designs are automatically refined to minimize several fairness criteria while maximal stresses are kept within glass limits. We achieve interactive frame rates by using a differentiable Mixture Density Network trained from more than a million simulations. Given a curved boundary, our regression model is capable of handling multistable configurations and accurately predicting the equilibrium shape of the panel and its corresponding maximal stress. We show predictions are highly accurate and validate our results with a physical realization of a cold bent glass surface.
Monocular Reconstruction of Neural Face Reflectance Fields
Aug 24, 2020
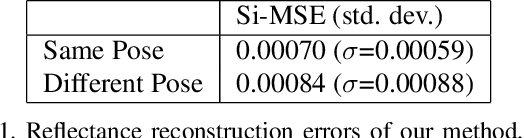


The reflectance field of a face describes the reflectance properties responsible for complex lighting effects including diffuse, specular, inter-reflection and self shadowing. Most existing methods for estimating the face reflectance from a monocular image assume faces to be diffuse with very few approaches adding a specular component. This still leaves out important perceptual aspects of reflectance as higher-order global illumination effects and self-shadowing are not modeled. We present a new neural representation for face reflectance where we can estimate all components of the reflectance responsible for the final appearance from a single monocular image. Instead of modeling each component of the reflectance separately using parametric models, our neural representation allows us to generate a basis set of faces in a geometric deformation-invariant space, parameterized by the input light direction, viewpoint and face geometry. We learn to reconstruct this reflectance field of a face just from a monocular image, which can be used to render the face from any viewpoint in any light condition. Our method is trained on a light-stage training dataset, which captures 300 people illuminated with 150 light conditions from 8 viewpoints. We show that our method outperforms existing monocular reflectance reconstruction methods, in terms of photorealism due to better capturing of physical premitives, such as sub-surface scattering, specularities, self-shadows and other higher-order effects.