 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFruitNeRF++: A Generalized Multi-Fruit Counting Method Utilizing Contrastive Learning and Neural Radiance Fields
May 26, 2025
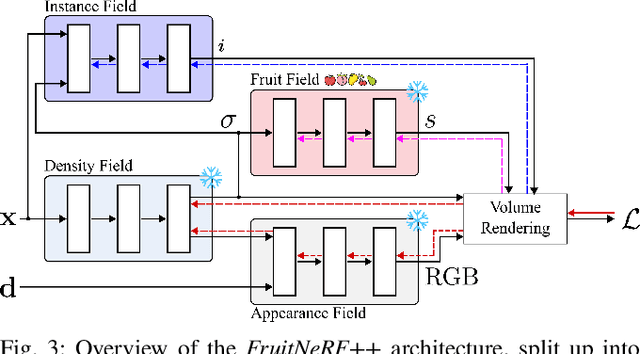


We introduce FruitNeRF++, a novel fruit-counting approach that combines contrastive learning with neural radiance fields to count fruits from unstructured input photographs of orchards. Our work is based on FruitNeRF, which employs a neural semantic field combined with a fruit-specific clustering approach. The requirement for adaptation for each fruit type limits the applicability of the method, and makes it difficult to use in practice. To lift this limitation, we design a shape-agnostic multi-fruit counting framework, that complements the RGB and semantic data with instance masks predicted by a vision foundation model. The masks are used to encode the identity of each fruit as instance embeddings into a neural instance field. By volumetrically sampling the neural fields, we extract a point cloud embedded with the instance features, which can be clustered in a fruit-agnostic manner to obtain the fruit count. We evaluate our approach using a synthetic dataset containing apples, plums, lemons, pears, peaches, and mangoes, as well as a real-world benchmark apple dataset. Our results demonstrate that FruitNeRF++ is easier to control and compares favorably to other state-of-the-art methods.
MAROON: A Framework for the Joint Characterization of Near-Field High-Resolution Radar and Optical Depth Imaging Techniques
Nov 01, 2024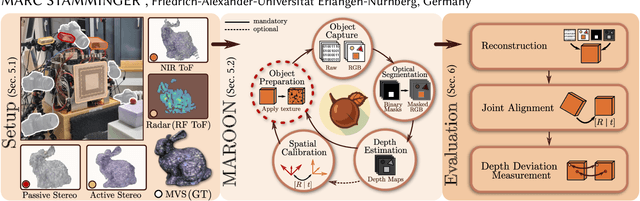
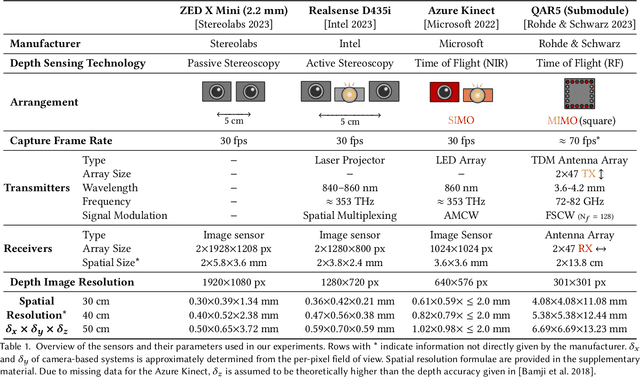
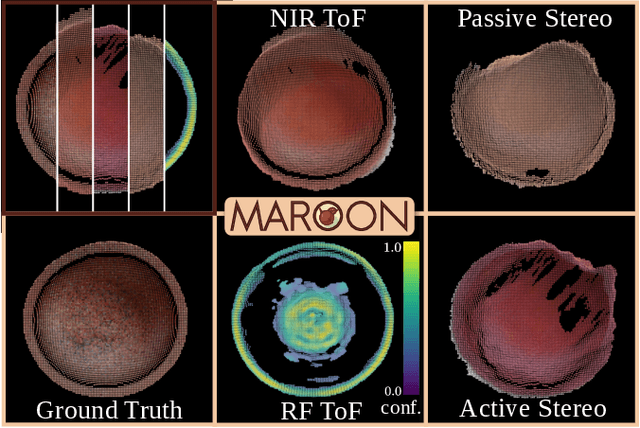

Utilizing the complementary strengths of wavelength-specific range or depth sensors is crucial for robust computer-assisted tasks such as autonomous driving. Despite this, there is still little research done at the intersection of optical depth sensors and radars operating close range, where the target is decimeters away from the sensors. Together with a growing interest in high-resolution imaging radars operating in the near field, the question arises how these sensors behave in comparison to their traditional optical counterparts. In this work, we take on the unique challenge of jointly characterizing depth imagers from both, the optical and radio-frequency domain using a multimodal spatial calibration. We collect data from four depth imagers, with three optical sensors of varying operation principle and an imaging radar. We provide a comprehensive evaluation of their depth measurements with respect to distinct object materials, geometries, and object-to-sensor distances. Specifically, we reveal scattering effects of partially transmissive materials and investigate the response of radio-frequency signals. All object measurements will be made public in form of a multimodal dataset, called MAROON.
Efficient Perspective-Correct 3D Gaussian Splatting Using Hybrid Transparency
Oct 10, 2024



3D Gaussian Splats (3DGS) have proven a versatile rendering primitive, both for inverse rendering as well as real-time exploration of scenes. In these applications, coherence across camera frames and multiple views is crucial, be it for robust convergence of a scene reconstruction or for artifact-free fly-throughs. Recent work started mitigating artifacts that break multi-view coherence, including popping artifacts due to inconsistent transparency sorting and perspective-correct outlines of (2D) splats. At the same time, real-time requirements forced such implementations to accept compromises in how transparency of large assemblies of 3D Gaussians is resolved, in turn breaking coherence in other ways. In our work, we aim at achieving maximum coherence, by rendering fully perspective-correct 3D Gaussians while using a high-quality approximation of accurate blending, hybrid transparency, on a per-pixel level, in order to retain real-time frame rates. Our fast and perspectively accurate approach for evaluation of 3D Gaussians does not require matrix inversions, thereby ensuring numerical stability and eliminating the need for special handling of degenerate splats, and the hybrid transparency formulation for blending maintains similar quality as fully resolved per-pixel transparencies at a fraction of the rendering costs. We further show that each of these two components can be independently integrated into Gaussian splatting systems. In combination, they achieve up to 2$\times$ higher frame rates, 2$\times$ faster optimization, and equal or better image quality with fewer rendering artifacts compared to traditional 3DGS on common benchmarks.
Lite2Relight: 3D-aware Single Image Portrait Relighting
Jul 15, 2024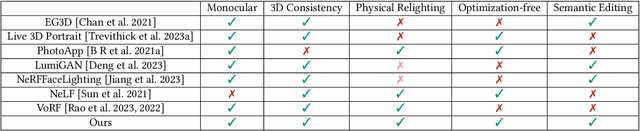
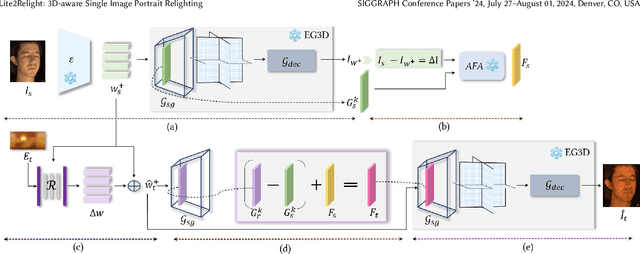
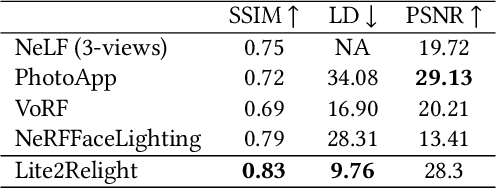

Achieving photorealistic 3D view synthesis and relighting of human portraits is pivotal for advancing AR/VR applications. Existing methodologies in portrait relighting demonstrate substantial limitations in terms of generalization and 3D consistency, coupled with inaccuracies in physically realistic lighting and identity preservation. Furthermore, personalization from a single view is difficult to achieve and often requires multiview images during the testing phase or involves slow optimization processes. This paper introduces Lite2Relight, a novel technique that can predict 3D consistent head poses of portraits while performing physically plausible light editing at interactive speed. Our method uniquely extends the generative capabilities and efficient volumetric representation of EG3D, leveraging a lightstage dataset to implicitly disentangle face reflectance and perform relighting under target HDRI environment maps. By utilizing a pre-trained geometry-aware encoder and a feature alignment module, we map input images into a relightable 3D space, enhancing them with a strong face geometry and reflectance prior. Through extensive quantitative and qualitative evaluations, we show that our method outperforms the state-of-the-art methods in terms of efficacy, photorealism, and practical application. This includes producing 3D-consistent results of the full head, including hair, eyes, and expressions. Lite2Relight paves the way for large-scale adoption of photorealistic portrait editing in various domains, offering a robust, interactive solution to a previously constrained problem. Project page: https://vcai.mpi-inf.mpg.de/projects/Lite2Relight/
Blind Localization and Clustering of Anomalies in Textures
Apr 18, 2024
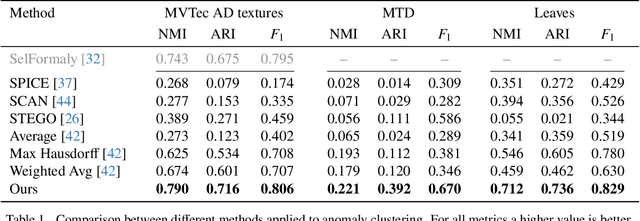

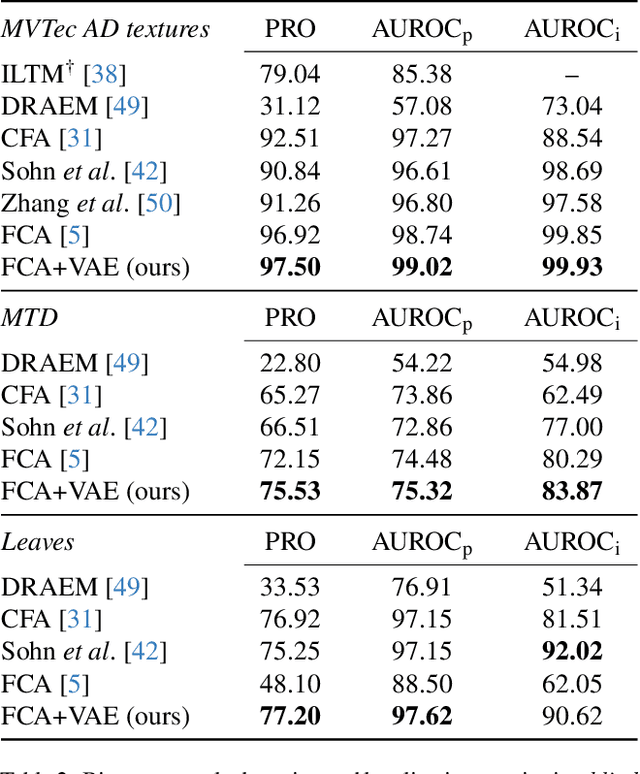
Anomaly detection and localization in images is a growing field in computer vision. In this area, a seemingly understudied problem is anomaly clustering, i.e., identifying and grouping different types of anomalies in a fully unsupervised manner. In this work, we propose a novel method for clustering anomalies in largely stationary images (textures) in a blind setting. That is, the input consists of normal and anomalous images without distinction and without labels. What contributes to the difficulty of the task is that anomalous regions are often small and may present only subtle changes in appearance, which can be easily overshadowed by the genuine variance in the texture. Moreover, each anomaly type may have a complex appearance distribution. We introduce a novel scheme for solving this task using a combination of blind anomaly localization and contrastive learning. By identifying the anomalous regions with high fidelity, we can restrict our focus to those regions of interest; then, contrastive learning is employed to increase the separability of different anomaly types and reduce the intra-class variation. Our experiments show that the proposed solution yields significantly better results compared to prior work, setting a new state of the art. Project page: https://reality.tf.fau.de/pub/ardelean2024blind.html.
Automatic Spatial Calibration of Near-Field MIMO Radar With Respect to Optical Sensors
Mar 16, 2024



Despite an emerging interest in MIMO radar, the utilization of its complementary strengths in combination with optical sensors has so far been limited to far-field applications, due to the challenges that arise from mutual sensor calibration in the near field. In fact, most related approaches in the autonomous industry propose target-based calibration methods using corner reflectors that have proven to be unsuitable for the near field. In contrast, we propose a novel, joint calibration approach for optical RGB-D sensors and MIMO radars that is designed to operate in the radar's near-field range, within decimeters from the sensors. Our pipeline consists of a bespoke calibration target, allowing for automatic target detection and localization, followed by the spatial calibration of the two sensor coordinate systems through target registration. We validate our approach using two different depth sensing technologies from the optical domain. The experiments show the efficiency and accuracy of our calibration for various target displacements, as well as its robustness of our localization in terms of signal ambiguities.
Achieving Efficient and Realistic Full-Radar Simulations and Automatic Data Annotation by exploiting Ray Meta Data of a Radar Ray Tracing Simulator
May 23, 2023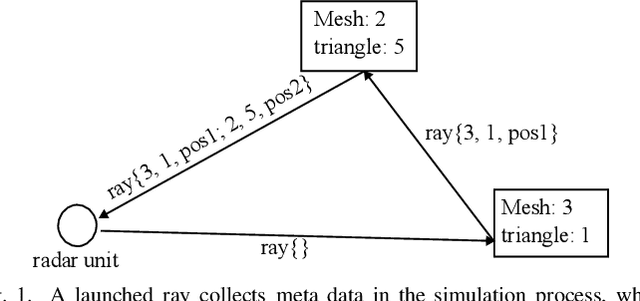
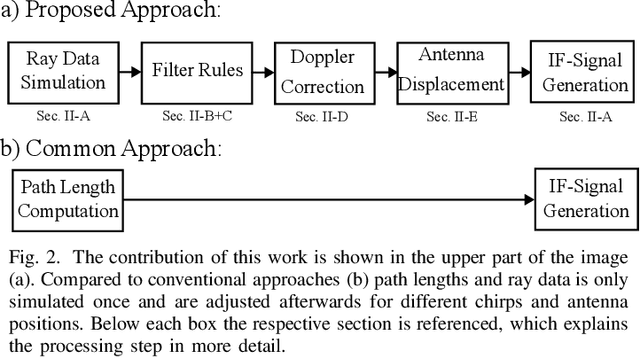
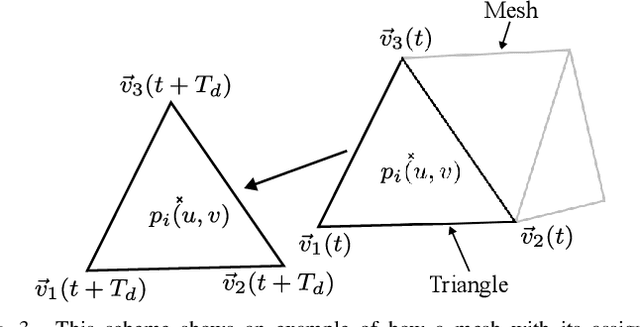
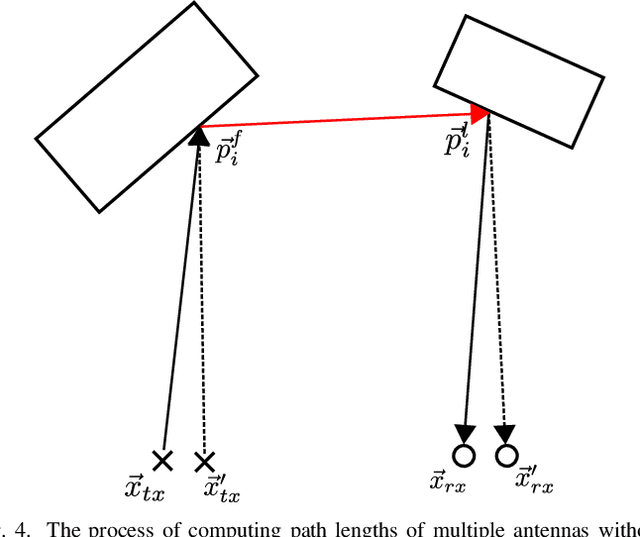
In this work a novel radar simulation concept is introduced that allows to simulate realistic radar data for Range, Doppler, and for arbitrary antenna positions in an efficient way. Further, it makes it possible to automatically annotate the simulated radar signal by allowing to decompose it into different parts. This approach allows not only almost perfect annotations possible, but also allows the annotation of exotic effects, such as multi-path effects or to label signal parts originating from different parts of an object. This is possible by adapting the computation process of a Monte Carlo shooting and bouncing rays (SBR) simulator. By considering the hits of each simulated ray, various meta data can be stored such as hit position, mesh pointer, object IDs, and many more. This collected meta data can then be utilized to predict the change of path lengths introduced by object motion to obtain Doppler information or to apply specific ray filter rules in order obtain radar signals that only fulfil specific conditions, such as multiple bounces or containing specific object IDs. Using this approach, perfect and otherwise almost impossible annotations schemes can be realized.
High-Fidelity Zero-Shot Texture Anomaly Localization Using Feature Correspondence Analysis
Apr 13, 2023

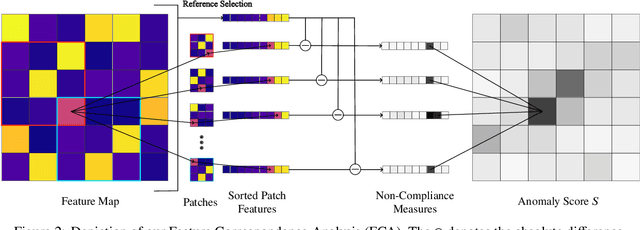
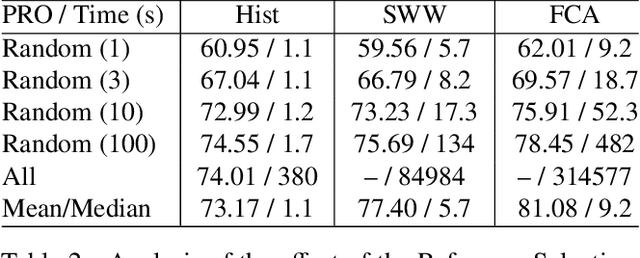
We propose a novel method for Zero-Shot Anomaly Localization that leverages a bidirectional mapping derived from the 1-dimensional Wasserstein Distance. The proposed approach allows pinpointing the anomalous regions in a texture with increased precision by aggregating the contribution of a pixel to the errors of all nearby patches. We validate our solution on several datasets and obtain more than a 40% reduction in error over the previous state of the art on the MVTec AD dataset in a zero-shot setting.
PhotoApp: Photorealistic Appearance Editing of Head Portraits
Mar 13, 2021
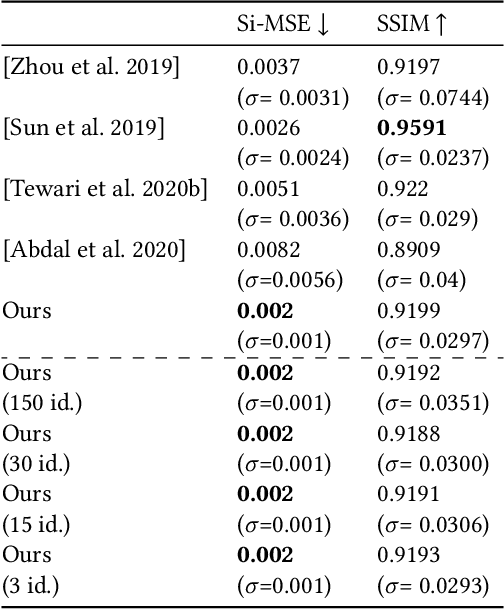
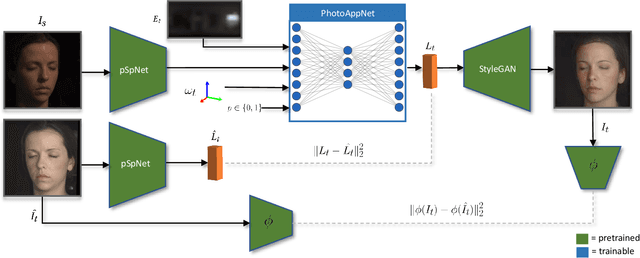
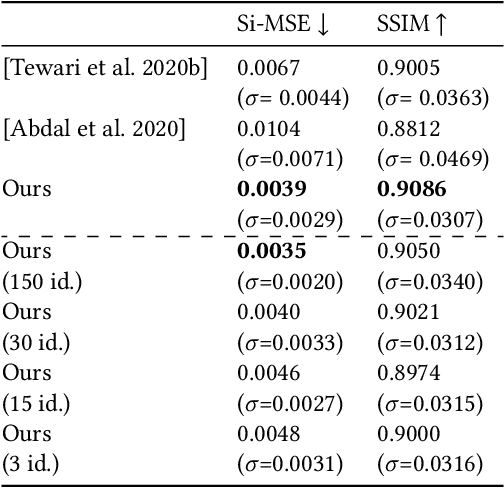
Photorealistic editing of portraits is a challenging task as humans are very sensitive to inconsistencies in faces. We present an approach for high-quality intuitive editing of the camera viewpoint and scene illumination in a portrait image. This requires our method to capture and control the full reflectance field of the person in the image. Most editing approaches rely on supervised learning using training data captured with setups such as light and camera stages. Such datasets are expensive to acquire, not readily available and do not capture all the rich variations of in-the-wild portrait images. In addition, most supervised approaches only focus on relighting, and do not allow camera viewpoint editing. Thus, they only capture and control a subset of the reflectance field. Recently, portrait editing has been demonstrated by operating in the generative model space of StyleGAN. While such approaches do not require direct supervision, there is a significant loss of quality when compared to the supervised approaches. In this paper, we present a method which learns from limited supervised training data. The training images only include people in a fixed neutral expression with eyes closed, without much hair or background variations. Each person is captured under 150 one-light-at-a-time conditions and under 8 camera poses. Instead of training directly in the image space, we design a supervised problem which learns transformations in the latent space of StyleGAN. This combines the best of supervised learning and generative adversarial modeling. We show that the StyleGAN prior allows for generalisation to different expressions, hairstyles and backgrounds. This produces high-quality photorealistic results for in-the-wild images and significantly outperforms existing methods. Our approach can edit the illumination and pose simultaneously, and runs at interactive rates.
Neural BRDF Representation and Importance Sampling
Feb 12, 2021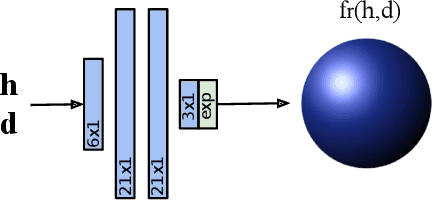
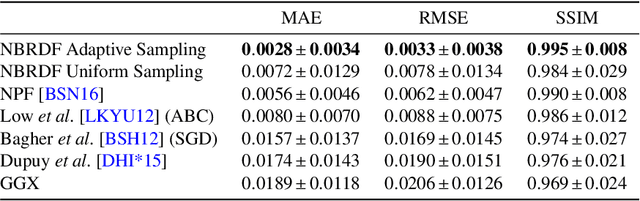


Controlled capture of real-world material appearance yields tabulated sets of highly realistic reflectance data. In practice, however, its high memory footprint requires compressing into a representation that can be used efficiently in rendering while remaining faithful to the original. Previous works in appearance encoding often prioritised one of these requirements at the expense of the other, by either applying high-fidelity array compression strategies not suited for efficient queries during rendering, or by fitting a compact analytic model that lacks expressiveness. We present a compact neural network-based representation of BRDF data that combines high-accuracy reconstruction with efficient practical rendering via built-in interpolation of reflectance. We encode BRDFs as lightweight networks, and propose a training scheme with adaptive angular sampling, critical for the accurate reconstruction of specular highlights. Additionally, we propose a novel approach to make our representation amenable to importance sampling: rather than inverting the trained networks, we learn an embedding that can be mapped to parameters of an analytic BRDF for which importance sampling is known. We evaluate encoding results on isotropic and anisotropic BRDFs from multiple real-world datasets, and importance sampling performance for isotropic BRDFs mapped to two different analytic models.