 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Bag of Tricks for Efficient Implicit Neural Point Clouds
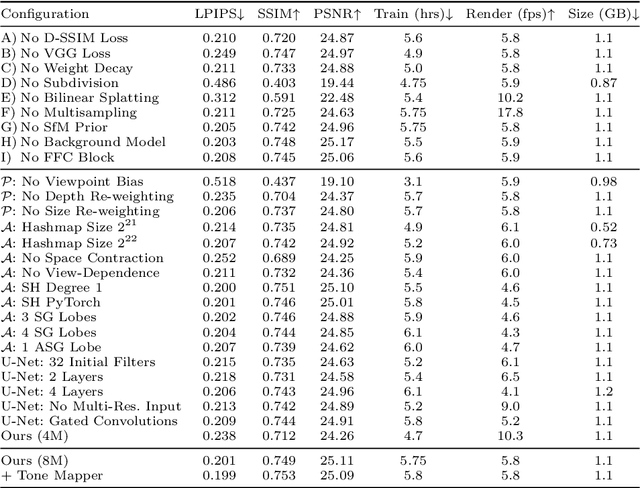
Aug 26, 2025Implicit Neural Point Cloud (INPC) is a recent hybrid representation that combines the expressiveness of neural fields with the efficiency of point-based rendering, achieving state-of-the-art image quality in novel view synthesis. However, as with other high-quality approaches that query neural networks during rendering, the practical usability of INPC is limited by comparatively slow rendering. In this work, we present a collection of optimizations that significantly improve both the training and inference performance of INPC without sacrificing visual fidelity. The most significant modifications are an improved rasterizer implementation, more effective sampling techniques, and the incorporation of pre-training for the convolutional neural network used for hole-filling. Furthermore, we demonstrate that points can be modeled as small Gaussians during inference to further improve quality in extrapolated, e.g., close-up views of the scene. We design our implementations to be broadly applicable beyond INPC and systematically evaluate each modification in a series of experiments. Our optimized INPC pipeline achieves up to 25% faster training, 2x faster rendering, and 20% reduced VRAM usage paired with slight image quality improvements.
VR-Splatting: Foveated Radiance Field Rendering via 3D Gaussian Splatting and Neural Points
Oct 23, 2024



Recent advances in novel view synthesis (NVS), particularly neural radiance fields (NeRF) and Gaussian splatting (3DGS), have demonstrated impressive results in photorealistic scene rendering. These techniques hold great potential for applications in virtual tourism and teleportation, where immersive realism is crucial. However, the high-performance demands of virtual reality (VR) systems present challenges in directly utilizing even such fast-to-render scene representations like 3DGS due to latency and computational constraints. In this paper, we propose foveated rendering as a promising solution to these obstacles. We analyze state-of-the-art NVS methods with respect to their rendering performance and compatibility with the human visual system. Our approach introduces a novel foveated rendering approach for Virtual Reality, that leverages the sharp, detailed output of neural point rendering for the foveal region, fused with a smooth rendering of 3DGS for the peripheral vision. Our evaluation confirms that perceived sharpness and detail-richness are increased by our approach compared to a standard VR-ready 3DGS configuration. Our system meets the necessary performance requirements for real-time VR interactions, ultimately enhancing the user's immersive experience. Project page: https://lfranke.github.io/vr_splatting
Efficient Perspective-Correct 3D Gaussian Splatting Using Hybrid Transparency
Oct 10, 2024



3D Gaussian Splats (3DGS) have proven a versatile rendering primitive, both for inverse rendering as well as real-time exploration of scenes. In these applications, coherence across camera frames and multiple views is crucial, be it for robust convergence of a scene reconstruction or for artifact-free fly-throughs. Recent work started mitigating artifacts that break multi-view coherence, including popping artifacts due to inconsistent transparency sorting and perspective-correct outlines of (2D) splats. At the same time, real-time requirements forced such implementations to accept compromises in how transparency of large assemblies of 3D Gaussians is resolved, in turn breaking coherence in other ways. In our work, we aim at achieving maximum coherence, by rendering fully perspective-correct 3D Gaussians while using a high-quality approximation of accurate blending, hybrid transparency, on a per-pixel level, in order to retain real-time frame rates. Our fast and perspectively accurate approach for evaluation of 3D Gaussians does not require matrix inversions, thereby ensuring numerical stability and eliminating the need for special handling of degenerate splats, and the hybrid transparency formulation for blending maintains similar quality as fully resolved per-pixel transparencies at a fraction of the rendering costs. We further show that each of these two components can be independently integrated into Gaussian splatting systems. In combination, they achieve up to 2$\times$ higher frame rates, 2$\times$ faster optimization, and equal or better image quality with fewer rendering artifacts compared to traditional 3DGS on common benchmarks.
Refinement of Monocular Depth Maps via Multi-View Differentiable Rendering
Oct 04, 2024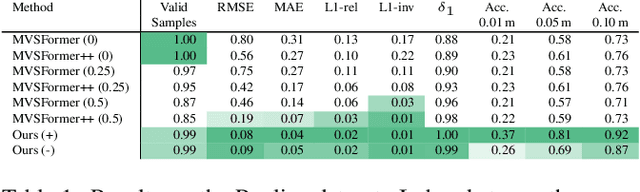
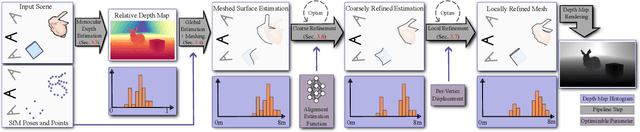
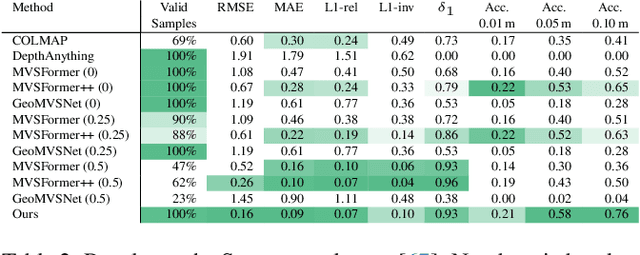

The accurate reconstruction of per-pixel depth for an image is vital for many tasks in computer graphics, computer vision, and robotics. In this paper, we present a novel approach to generate view consistent and detailed depth maps from a number of posed images. We leverage advances in monocular depth estimation, which generate topologically complete, but metrically inaccurate depth maps and refine them in a two-stage optimization process based on a differentiable renderer. Taking the monocular depth map as input, we first scale this map to absolute distances based on structure-from-motion and transform the depths to a triangle surface mesh. We then refine this depth mesh in a local optimization, enforcing photometric and geometric consistency. Our evaluation shows that our method is able to generate dense, detailed, high-quality depth maps, also in challenging indoor scenarios, and outperforms state-of-the-art depth reconstruction approaches. Overview and supplemental material of this project can be found at https://lorafib.github.io/ref_depth/.
INPC: Implicit Neural Point Clouds for Radiance Field Rendering
Mar 25, 2024
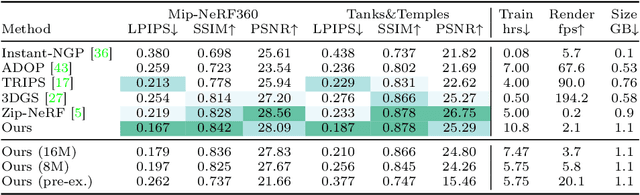
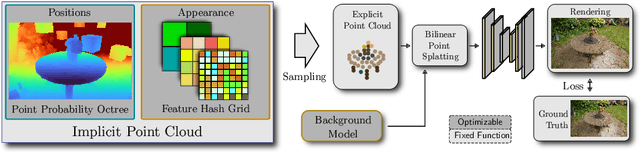
We introduce a new approach for reconstruction and novel-view synthesis of unbounded real-world scenes. In contrast to previous methods using either volumetric fields, grid-based models, or discrete point cloud proxies, we propose a hybrid scene representation, which implicitly encodes a point cloud in a continuous octree-based probability field and a multi-resolution hash grid. In doing so, we combine the benefits of both worlds by retaining favorable behavior during optimization: Our novel implicit point cloud representation and differentiable bilinear rasterizer enable fast rendering while preserving fine geometric detail without depending on initial priors like structure-from-motion point clouds. Our method achieves state-of-the-art image quality on several common benchmark datasets. Furthermore, we achieve fast inference at interactive frame rates, and can extract explicit point clouds to further enhance performance.
TRIPS: Trilinear Point Splatting for Real-Time Radiance Field Rendering
Jan 11, 2024Point-based radiance field rendering has demonstrated impressive results for novel view synthesis, offering a compelling blend of rendering quality and computational efficiency. However, also latest approaches in this domain are not without their shortcomings. 3D Gaussian Splatting [Kerbl and Kopanas et al. 2023] struggles when tasked with rendering highly detailed scenes, due to blurring and cloudy artifacts. On the other hand, ADOP [R\"uckert et al. 2022] can accommodate crisper images, but the neural reconstruction network decreases performance, it grapples with temporal instability and it is unable to effectively address large gaps in the point cloud. In this paper, we present TRIPS (Trilinear Point Splatting), an approach that combines ideas from both Gaussian Splatting and ADOP. The fundamental concept behind our novel technique involves rasterizing points into a screen-space image pyramid, with the selection of the pyramid layer determined by the projected point size. This approach allows rendering arbitrarily large points using a single trilinear write. A lightweight neural network is then used to reconstruct a hole-free image including detail beyond splat resolution. Importantly, our render pipeline is entirely differentiable, allowing for automatic optimization of both point sizes and positions. Our evaluation demonstrate that TRIPS surpasses existing state-of-the-art methods in terms of rendering quality while maintaining a real-time frame rate of 60 frames per second on readily available hardware. This performance extends to challenging scenarios, such as scenes featuring intricate geometry, expansive landscapes, and auto-exposed footage.
LiveNVS: Neural View Synthesis on Live RGB-D Streams
Nov 29, 2023



Existing real-time RGB-D reconstruction approaches, like Kinect Fusion, lack real-time photo-realistic visualization. This is due to noisy, oversmoothed or incomplete geometry and blurry textures which are fused from imperfect depth maps and camera poses. Recent neural rendering methods can overcome many of such artifacts but are mostly optimized for offline usage, hindering the integration into a live reconstruction pipeline. In this paper, we present LiveNVS, a system that allows for neural novel view synthesis on a live RGB-D input stream with very low latency and real-time rendering. Based on the RGB-D input stream, novel views are rendered by projecting neural features into the target view via a densely fused depth map and aggregating the features in image-space to a target feature map. A generalizable neural network then translates the target feature map into a high-quality RGB image. LiveNVS achieves state-of-the-art neural rendering quality of unknown scenes during capturing, allowing users to virtually explore the scene and assess reconstruction quality in real-time.
VET: Visual Error Tomography for Point Cloud Completion and High-Quality Neural Rendering
Nov 08, 2023

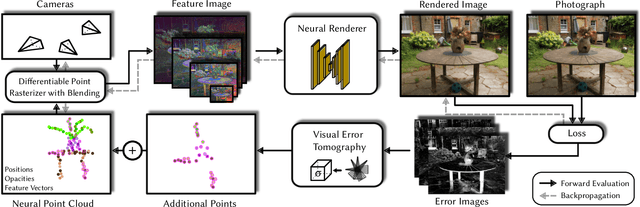

In the last few years, deep neural networks opened the doors for big advances in novel view synthesis. Many of these approaches are based on a (coarse) proxy geometry obtained by structure from motion algorithms. Small deficiencies in this proxy can be fixed by neural rendering, but larger holes or missing parts, as they commonly appear for thin structures or for glossy regions, still lead to distracting artifacts and temporal instability. In this paper, we present a novel neural-rendering-based approach to detect and fix such deficiencies. As a proxy, we use a point cloud, which allows us to easily remove outlier geometry and to fill in missing geometry without complicated topological operations. Keys to our approach are (i) a differentiable, blending point-based renderer that can blend out redundant points, as well as (ii) the concept of Visual Error Tomography (VET), which allows us to lift 2D error maps to identify 3D-regions lacking geometry and to spawn novel points accordingly. Furthermore, (iii) by adding points as nested environment maps, our approach allows us to generate high-quality renderings of the surroundings in the same pipeline. In our results, we show that our approach can improve the quality of a point cloud obtained by structure from motion and thus increase novel view synthesis quality significantly. In contrast to point growing techniques, the approach can also fix large-scale holes and missing thin structures effectively. Rendering quality outperforms state-of-the-art methods and temporal stability is significantly improved, while rendering is possible at real-time frame rates.
ADOP: Approximate Differentiable One-Pixel Point Rendering
Oct 15, 2021



We present a novel point-based, differentiable neural rendering pipeline for scene refinement and novel view synthesis. The input are an initial estimate of the point cloud and the camera parameters. The output are synthesized images from arbitrary camera poses. The point cloud rendering is performed by a differentiable renderer using multi-resolution one-pixel point rasterization. Spatial gradients of the discrete rasterization are approximated by the novel concept of ghost geometry. After rendering, the neural image pyramid is passed through a deep neural network for shading calculations and hole-filling. A differentiable, physically-based tonemapper then converts the intermediate output to the target image. Since all stages of the pipeline are differentiable, we optimize all of the scene's parameters i.e. camera model, camera pose, point position, point color, environment map, rendering network weights, vignetting, camera response function, per image exposure, and per image white balance. We show that our system is able to synthesize sharper and more consistent novel views than existing approaches because the initial reconstruction is refined during training. The efficient one-pixel point rasterization allows us to use arbitrary camera models and display scenes with well over 100M points in real time.