 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Bag of Tricks for Efficient Implicit Neural Point Clouds
Aug 26, 2025Implicit Neural Point Cloud (INPC) is a recent hybrid representation that combines the expressiveness of neural fields with the efficiency of point-based rendering, achieving state-of-the-art image quality in novel view synthesis. However, as with other high-quality approaches that query neural networks during rendering, the practical usability of INPC is limited by comparatively slow rendering. In this work, we present a collection of optimizations that significantly improve both the training and inference performance of INPC without sacrificing visual fidelity. The most significant modifications are an improved rasterizer implementation, more effective sampling techniques, and the incorporation of pre-training for the convolutional neural network used for hole-filling. Furthermore, we demonstrate that points can be modeled as small Gaussians during inference to further improve quality in extrapolated, e.g., close-up views of the scene. We design our implementations to be broadly applicable beyond INPC and systematically evaluate each modification in a series of experiments. Our optimized INPC pipeline achieves up to 25% faster training, 2x faster rendering, and 20% reduced VRAM usage paired with slight image quality improvements.
Efficient Perspective-Correct 3D Gaussian Splatting Using Hybrid Transparency
Oct 10, 2024



3D Gaussian Splats (3DGS) have proven a versatile rendering primitive, both for inverse rendering as well as real-time exploration of scenes. In these applications, coherence across camera frames and multiple views is crucial, be it for robust convergence of a scene reconstruction or for artifact-free fly-throughs. Recent work started mitigating artifacts that break multi-view coherence, including popping artifacts due to inconsistent transparency sorting and perspective-correct outlines of (2D) splats. At the same time, real-time requirements forced such implementations to accept compromises in how transparency of large assemblies of 3D Gaussians is resolved, in turn breaking coherence in other ways. In our work, we aim at achieving maximum coherence, by rendering fully perspective-correct 3D Gaussians while using a high-quality approximation of accurate blending, hybrid transparency, on a per-pixel level, in order to retain real-time frame rates. Our fast and perspectively accurate approach for evaluation of 3D Gaussians does not require matrix inversions, thereby ensuring numerical stability and eliminating the need for special handling of degenerate splats, and the hybrid transparency formulation for blending maintains similar quality as fully resolved per-pixel transparencies at a fraction of the rendering costs. We further show that each of these two components can be independently integrated into Gaussian splatting systems. In combination, they achieve up to 2$\times$ higher frame rates, 2$\times$ faster optimization, and equal or better image quality with fewer rendering artifacts compared to traditional 3DGS on common benchmarks.
D-NPC: Dynamic Neural Point Clouds for Non-Rigid View Synthesis from Monocular Video
Jun 14, 2024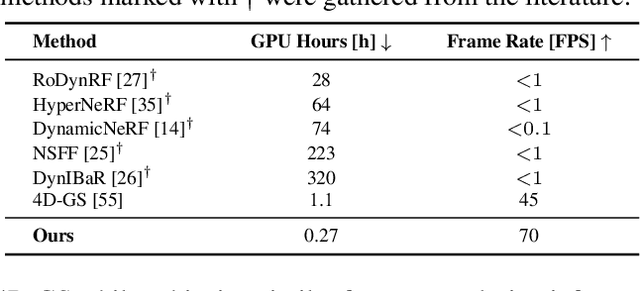



Dynamic reconstruction and spatiotemporal novel-view synthesis of non-rigidly deforming scenes recently gained increased attention. While existing work achieves impressive quality and performance on multi-view or teleporting camera setups, most methods fail to efficiently and faithfully recover motion and appearance from casual monocular captures. This paper contributes to the field by introducing a new method for dynamic novel view synthesis from monocular video, such as casual smartphone captures. Our approach represents the scene as a $\textit{dynamic neural point cloud}$, an implicit time-conditioned point distribution that encodes local geometry and appearance in separate hash-encoded neural feature grids for static and dynamic regions. By sampling a discrete point cloud from our model, we can efficiently render high-quality novel views using a fast differentiable rasterizer and neural rendering network. Similar to recent work, we leverage advances in neural scene analysis by incorporating data-driven priors like monocular depth estimation and object segmentation to resolve motion and depth ambiguities originating from the monocular captures. In addition to guiding the optimization process, we show that these priors can be exploited to explicitly initialize our scene representation to drastically improve optimization speed and final image quality. As evidenced by our experimental evaluation, our dynamic point cloud model not only enables fast optimization and real-time frame rates for interactive applications, but also achieves competitive image quality on monocular benchmark sequences. Our project page is available at https://moritzkappel.github.io/projects/dnpc.
INPC: Implicit Neural Point Clouds for Radiance Field Rendering
Mar 25, 2024
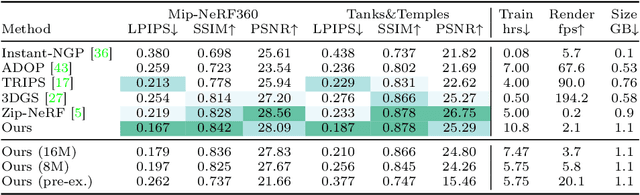
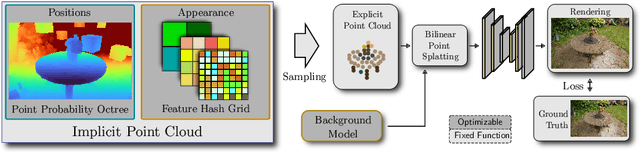
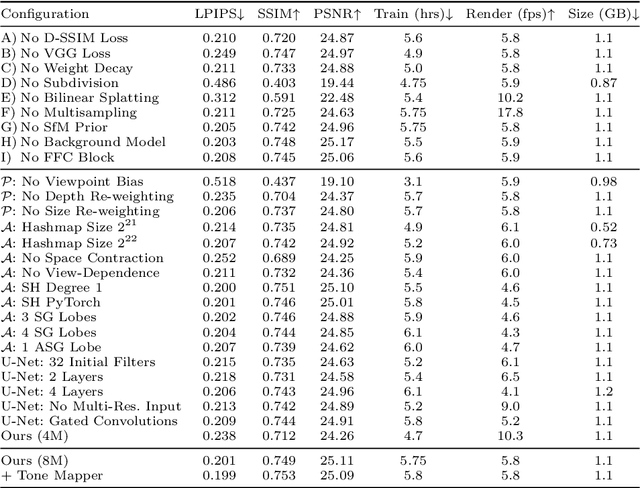
We introduce a new approach for reconstruction and novel-view synthesis of unbounded real-world scenes. In contrast to previous methods using either volumetric fields, grid-based models, or discrete point cloud proxies, we propose a hybrid scene representation, which implicitly encodes a point cloud in a continuous octree-based probability field and a multi-resolution hash grid. In doing so, we combine the benefits of both worlds by retaining favorable behavior during optimization: Our novel implicit point cloud representation and differentiable bilinear rasterizer enable fast rendering while preserving fine geometric detail without depending on initial priors like structure-from-motion point clouds. Our method achieves state-of-the-art image quality on several common benchmark datasets. Furthermore, we achieve fast inference at interactive frame rates, and can extract explicit point clouds to further enhance performance.