 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeD-NPC: Dynamic Neural Point Clouds for Non-Rigid View Synthesis from Monocular Video
Jun 14, 2024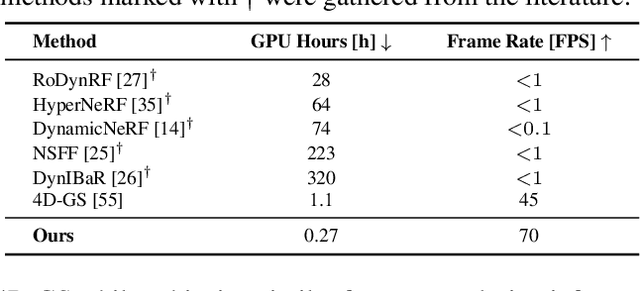



Dynamic reconstruction and spatiotemporal novel-view synthesis of non-rigidly deforming scenes recently gained increased attention. While existing work achieves impressive quality and performance on multi-view or teleporting camera setups, most methods fail to efficiently and faithfully recover motion and appearance from casual monocular captures. This paper contributes to the field by introducing a new method for dynamic novel view synthesis from monocular video, such as casual smartphone captures. Our approach represents the scene as a $\textit{dynamic neural point cloud}$, an implicit time-conditioned point distribution that encodes local geometry and appearance in separate hash-encoded neural feature grids for static and dynamic regions. By sampling a discrete point cloud from our model, we can efficiently render high-quality novel views using a fast differentiable rasterizer and neural rendering network. Similar to recent work, we leverage advances in neural scene analysis by incorporating data-driven priors like monocular depth estimation and object segmentation to resolve motion and depth ambiguities originating from the monocular captures. In addition to guiding the optimization process, we show that these priors can be exploited to explicitly initialize our scene representation to drastically improve optimization speed and final image quality. As evidenced by our experimental evaluation, our dynamic point cloud model not only enables fast optimization and real-time frame rates for interactive applications, but also achieves competitive image quality on monocular benchmark sequences. Our project page is available at https://moritzkappel.github.io/projects/dnpc.