 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFus3D: Decoding Consolidated 3D Geometry from Feed-forward Geometry Transformer Latents
Mar 26, 2026We propose a feed-forward method for dense Signed Distance Field (SDF) regression from unstructured image collections in less than three seconds, without camera calibration or post-hoc fusion. Our key insight is that the intermediate feature space of pretrained multi-view feed-forward geometry transformers already encodes a powerful joint world representation; yet, existing pipelines discard it, routing features through per-view prediction heads before assembling 3D geometry post-hoc, which discards valuable completeness information and accumulates inaccuracies. We instead perform 3D extraction directly from geometry transformer features via learned volumetric extraction: voxelized canonical embeddings that progressively absorb multi-view geometry information through interleaved cross- and self-attention into a structured volumetric latent grid. A simple convolutional decoder then maps this grid to a dense SDF. We additionally propose a scalable, validity-aware supervision scheme directly using SDFs derived from depth maps or 3D assets, tackling practical issues like non-watertight meshes. Our approach yields complete and well-defined distance values across sparse- and dense-view settings and demonstrates geometrically plausible completions. Code and further material can be found at https://lorafib.github.io/fus3d.
FruitNeRF++: A Generalized Multi-Fruit Counting Method Utilizing Contrastive Learning and Neural Radiance Fields
May 26, 2025
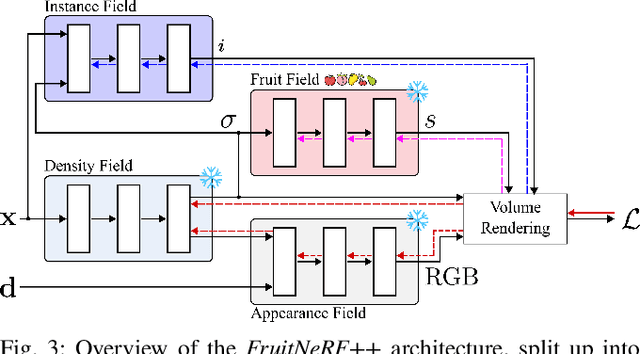


We introduce FruitNeRF++, a novel fruit-counting approach that combines contrastive learning with neural radiance fields to count fruits from unstructured input photographs of orchards. Our work is based on FruitNeRF, which employs a neural semantic field combined with a fruit-specific clustering approach. The requirement for adaptation for each fruit type limits the applicability of the method, and makes it difficult to use in practice. To lift this limitation, we design a shape-agnostic multi-fruit counting framework, that complements the RGB and semantic data with instance masks predicted by a vision foundation model. The masks are used to encode the identity of each fruit as instance embeddings into a neural instance field. By volumetrically sampling the neural fields, we extract a point cloud embedded with the instance features, which can be clustered in a fruit-agnostic manner to obtain the fruit count. We evaluate our approach using a synthetic dataset containing apples, plums, lemons, pears, peaches, and mangoes, as well as a real-world benchmark apple dataset. Our results demonstrate that FruitNeRF++ is easier to control and compares favorably to other state-of-the-art methods.
Synth It Like KITTI: Synthetic Data Generation for Object Detection in Driving Scenarios
Feb 20, 2025



An important factor in advancing autonomous driving systems is simulation. Yet, there is rather small progress for transferability between the virtual and real world. We revisit this problem for 3D object detection on LiDAR point clouds and propose a dataset generation pipeline based on the CARLA simulator. Utilizing domain randomization strategies and careful modeling, we are able to train an object detector on the synthetic data and demonstrate strong generalization capabilities to the KITTI dataset. Furthermore, we compare different virtual sensor variants to gather insights, which sensor attributes can be responsible for the prevalent domain gap. Finally, fine-tuning with a small portion of real data almost matches the baseline and with the full training set slightly surpasses it.
MAROON: A Framework for the Joint Characterization of Near-Field High-Resolution Radar and Optical Depth Imaging Techniques
Nov 01, 2024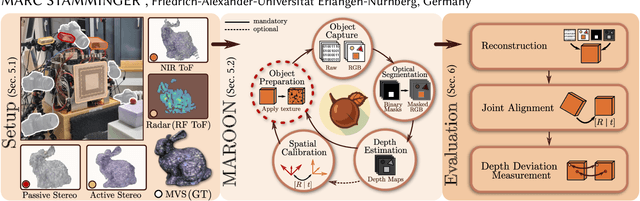
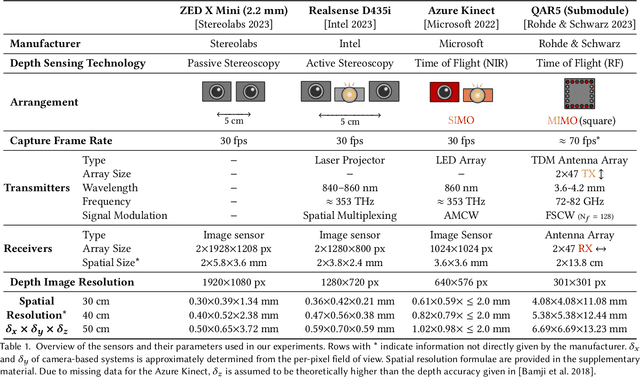
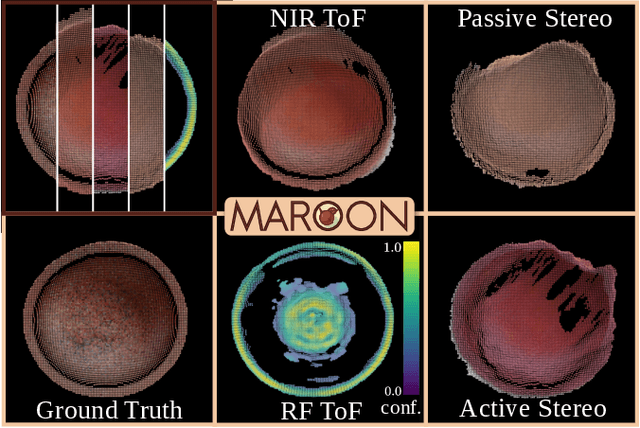

Utilizing the complementary strengths of wavelength-specific range or depth sensors is crucial for robust computer-assisted tasks such as autonomous driving. Despite this, there is still little research done at the intersection of optical depth sensors and radars operating close range, where the target is decimeters away from the sensors. Together with a growing interest in high-resolution imaging radars operating in the near field, the question arises how these sensors behave in comparison to their traditional optical counterparts. In this work, we take on the unique challenge of jointly characterizing depth imagers from both, the optical and radio-frequency domain using a multimodal spatial calibration. We collect data from four depth imagers, with three optical sensors of varying operation principle and an imaging radar. We provide a comprehensive evaluation of their depth measurements with respect to distinct object materials, geometries, and object-to-sensor distances. Specifically, we reveal scattering effects of partially transmissive materials and investigate the response of radio-frequency signals. All object measurements will be made public in form of a multimodal dataset, called MAROON.
VR-Splatting: Foveated Radiance Field Rendering via 3D Gaussian Splatting and Neural Points
Oct 23, 2024



Recent advances in novel view synthesis (NVS), particularly neural radiance fields (NeRF) and Gaussian splatting (3DGS), have demonstrated impressive results in photorealistic scene rendering. These techniques hold great potential for applications in virtual tourism and teleportation, where immersive realism is crucial. However, the high-performance demands of virtual reality (VR) systems present challenges in directly utilizing even such fast-to-render scene representations like 3DGS due to latency and computational constraints. In this paper, we propose foveated rendering as a promising solution to these obstacles. We analyze state-of-the-art NVS methods with respect to their rendering performance and compatibility with the human visual system. Our approach introduces a novel foveated rendering approach for Virtual Reality, that leverages the sharp, detailed output of neural point rendering for the foveal region, fused with a smooth rendering of 3DGS for the peripheral vision. Our evaluation confirms that perceived sharpness and detail-richness are increased by our approach compared to a standard VR-ready 3DGS configuration. Our system meets the necessary performance requirements for real-time VR interactions, ultimately enhancing the user's immersive experience. Project page: https://lfranke.github.io/vr_splatting
Efficient Perspective-Correct 3D Gaussian Splatting Using Hybrid Transparency
Oct 10, 2024



3D Gaussian Splats (3DGS) have proven a versatile rendering primitive, both for inverse rendering as well as real-time exploration of scenes. In these applications, coherence across camera frames and multiple views is crucial, be it for robust convergence of a scene reconstruction or for artifact-free fly-throughs. Recent work started mitigating artifacts that break multi-view coherence, including popping artifacts due to inconsistent transparency sorting and perspective-correct outlines of (2D) splats. At the same time, real-time requirements forced such implementations to accept compromises in how transparency of large assemblies of 3D Gaussians is resolved, in turn breaking coherence in other ways. In our work, we aim at achieving maximum coherence, by rendering fully perspective-correct 3D Gaussians while using a high-quality approximation of accurate blending, hybrid transparency, on a per-pixel level, in order to retain real-time frame rates. Our fast and perspectively accurate approach for evaluation of 3D Gaussians does not require matrix inversions, thereby ensuring numerical stability and eliminating the need for special handling of degenerate splats, and the hybrid transparency formulation for blending maintains similar quality as fully resolved per-pixel transparencies at a fraction of the rendering costs. We further show that each of these two components can be independently integrated into Gaussian splatting systems. In combination, they achieve up to 2$\times$ higher frame rates, 2$\times$ faster optimization, and equal or better image quality with fewer rendering artifacts compared to traditional 3DGS on common benchmarks.
Refinement of Monocular Depth Maps via Multi-View Differentiable Rendering
Oct 04, 2024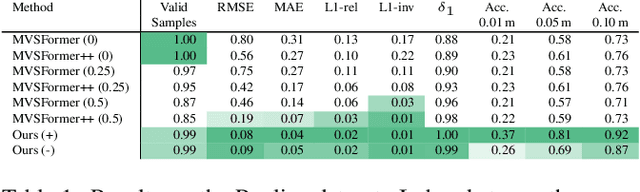
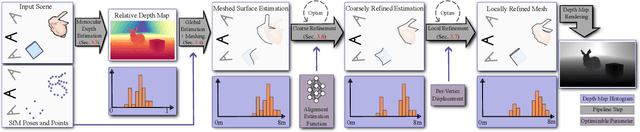
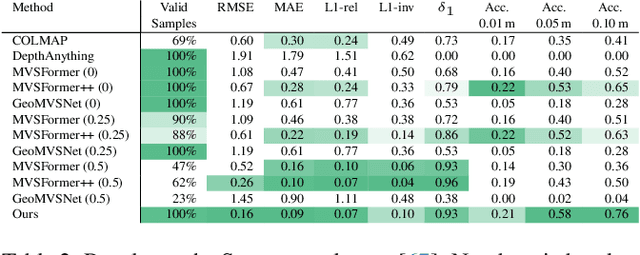

The accurate reconstruction of per-pixel depth for an image is vital for many tasks in computer graphics, computer vision, and robotics. In this paper, we present a novel approach to generate view consistent and detailed depth maps from a number of posed images. We leverage advances in monocular depth estimation, which generate topologically complete, but metrically inaccurate depth maps and refine them in a two-stage optimization process based on a differentiable renderer. Taking the monocular depth map as input, we first scale this map to absolute distances based on structure-from-motion and transform the depths to a triangle surface mesh. We then refine this depth mesh in a local optimization, enforcing photometric and geometric consistency. Our evaluation shows that our method is able to generate dense, detailed, high-quality depth maps, also in challenging indoor scenarios, and outperforms state-of-the-art depth reconstruction approaches. Overview and supplemental material of this project can be found at https://lorafib.github.io/ref_depth/.
End-to-end learned Lossy Dynamic Point Cloud Attribute Compression
Aug 20, 2024



Recent advancements in point cloud compression have primarily emphasized geometry compression while comparatively fewer efforts have been dedicated to attribute compression. This study introduces an end-to-end learned dynamic lossy attribute coding approach, utilizing an efficient high-dimensional convolution to capture extensive inter-point dependencies. This enables the efficient projection of attribute features into latent variables. Subsequently, we employ a context model that leverage previous latent space in conjunction with an auto-regressive context model for encoding the latent tensor into a bitstream. Evaluation of our method on widely utilized point cloud datasets from the MPEG and Microsoft demonstrates its superior performance compared to the core attribute compression module Region-Adaptive Hierarchical Transform method from MPEG Geometry Point Cloud Compression with 38.1% Bjontegaard Delta-rate saving in average while ensuring a low-complexity encoding/decoding.
FruitNeRF: A Unified Neural Radiance Field based Fruit Counting Framework
Aug 12, 2024
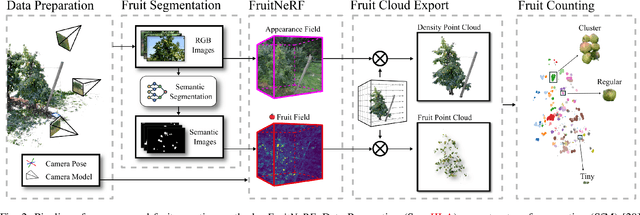

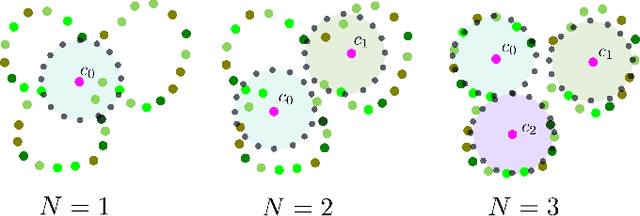
We introduce FruitNeRF, a unified novel fruit counting framework that leverages state-of-the-art view synthesis methods to count any fruit type directly in 3D. Our framework takes an unordered set of posed images captured by a monocular camera and segments fruit in each image. To make our system independent of the fruit type, we employ a foundation model that generates binary segmentation masks for any fruit. Utilizing both modalities, RGB and semantic, we train a semantic neural radiance field. Through uniform volume sampling of the implicit Fruit Field, we obtain fruit-only point clouds. By applying cascaded clustering on the extracted point cloud, our approach achieves precise fruit count.The use of neural radiance fields provides significant advantages over conventional methods such as object tracking or optical flow, as the counting itself is lifted into 3D. Our method prevents double counting fruit and avoids counting irrelevant fruit.We evaluate our methodology using both real-world and synthetic datasets. The real-world dataset consists of three apple trees with manually counted ground truths, a benchmark apple dataset with one row and ground truth fruit location, while the synthetic dataset comprises various fruit types including apple, plum, lemon, pear, peach, and mango.Additionally, we assess the performance of fruit counting using the foundation model compared to a U-Net.
An Efficient yet High-Performance Method for Precise Radar-Based Imaging of Human Hand Poses
Jun 19, 2024Contactless hand pose estimation requires sensors that provide precise spatial information and low computational complexity for real-time processing. Unlike vision-based systems, radar offers lighting independence and direct motion assessments. Yet, there is limited research balancing real-time constraints, suitable frame rates for motion evaluations, and the need for precise 3D data. To address this, we extend the ultra-efficient two-tone hand imaging method from our prior work to a three-tone approach. Maintaining high frame rates and real-time constraints, this approach significantly enhances reconstruction accuracy and precision. We assess these measures by evaluating reconstruction results for different hand poses obtained by an imaging radar. Accuracy is assessed against ground truth from a spatially calibrated photogrammetry setup, while precision is measured using 3D-printed hand poses. The results emphasize the method's great potential for future radar-based hand sensing.