 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnd-to-end learned Lossy Dynamic Point Cloud Attribute Compression
Aug 20, 2024



Recent advancements in point cloud compression have primarily emphasized geometry compression while comparatively fewer efforts have been dedicated to attribute compression. This study introduces an end-to-end learned dynamic lossy attribute coding approach, utilizing an efficient high-dimensional convolution to capture extensive inter-point dependencies. This enables the efficient projection of attribute features into latent variables. Subsequently, we employ a context model that leverage previous latent space in conjunction with an auto-regressive context model for encoding the latent tensor into a bitstream. Evaluation of our method on widely utilized point cloud datasets from the MPEG and Microsoft demonstrates its superior performance compared to the core attribute compression module Region-Adaptive Hierarchical Transform method from MPEG Geometry Point Cloud Compression with 38.1% Bjontegaard Delta-rate saving in average while ensuring a low-complexity encoding/decoding.
Dissecting vocabulary biases datasets through statistical testing and automated data augmentation for artifact mitigation in Natural Language Inference
Dec 14, 2023
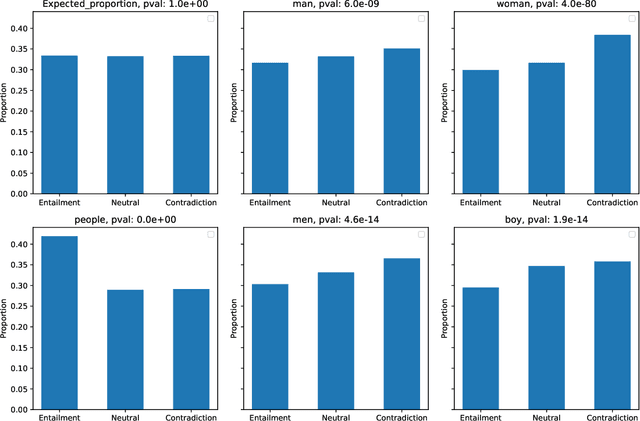

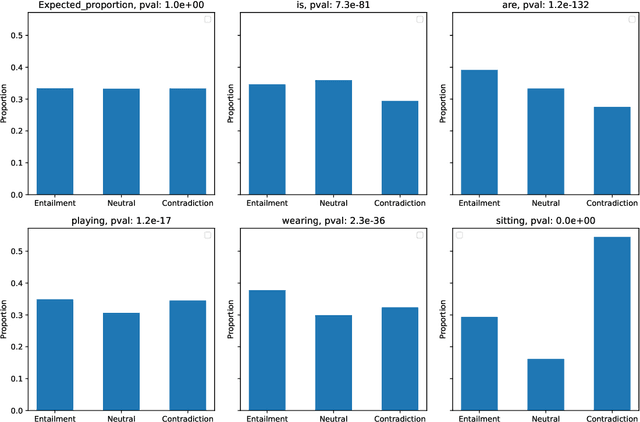
In recent years, the availability of large-scale annotated datasets, such as the Stanford Natural Language Inference and the Multi-Genre Natural Language Inference, coupled with the advent of pre-trained language models, has significantly contributed to the development of the natural language inference domain. However, these crowdsourced annotated datasets often contain biases or dataset artifacts, leading to overestimated model performance and poor generalization. In this work, we focus on investigating dataset artifacts and developing strategies to address these issues. Through the utilization of a novel statistical testing procedure, we discover a significant association between vocabulary distribution and text entailment classes, emphasizing vocabulary as a notable source of biases. To mitigate these issues, we propose several automatic data augmentation strategies spanning character to word levels. By fine-tuning the ELECTRA pre-trained language model, we compare the performance of boosted models with augmented data against their baseline counterparts. The experiments demonstrate that the proposed approaches effectively enhance model accuracy and reduce biases by up to 0.66% and 1.14%, respectively.
The Bjøntegaard Bible -- Why your Way of Comparing Video Codecs May Be Wrong
Apr 25, 2023



In this paper, we provide an in-depth assessment on the Bj{\o}ntegaard Delta. We construct a large data set of video compression performance comparisons using a diverse set of metrics including PSNR, VMAF, bitrate, and processing energies. These metrics are evaluated for visual data types such as classic perspective video, 360{\deg} video, point clouds, and screen content. As compression technology, we consider multiple hybrid video codecs as well as state-of-the-art neural network based compression methods. Using additional performance points inbetween standard points defined by parameters such as the quantization parameter, we assess the interpolation error of the Bj{\o}ntegaard-Delta (BD) calculus and its impact on the final BD value. Performing an in-depth analysis, we find that the BD calculus is most accurate in the standard application of rate-distortion comparisons with mean errors below 0.5 percentage points. For other applications, the errors are higher (up to 10 percentage points), but can be reduced by a higher number of performance points. We finally come up with recommendations on how to use the BD calculus such that the validity of the resulting BD-values is maximized. Main recommendations include the use of Akima interpolation, the interpretation of relative difference curves, and the use of the logarithmic domain for saturating metrics such as SSIM and VMAF.
Deep probabilistic model for lossless scalable point cloud attribute compression
Mar 11, 2023In recent years, several point cloud geometry compression methods that utilize advanced deep learning techniques have been proposed, but there are limited works on attribute compression, especially lossless compression. In this work, we build an end-to-end multiscale point cloud attribute coding method (MNeT) that progressively projects the attributes onto multiscale latent spaces. The multiscale architecture provides an accurate context for the attribute probability modeling and thus minimizes the coding bitrate with a single network prediction. Besides, our method allows scalable coding that lower quality versions can be easily extracted from the losslessly compressed bitstream. We validate our method on a set of point clouds from MVUB and MPEG and show that our method outperforms recently proposed methods and on par with the latest G-PCC version 14. Besides, our coding time is substantially faster than G-PCC.
Learning-based Lossless Point Cloud Geometry Coding using Sparse Representations
Apr 11, 2022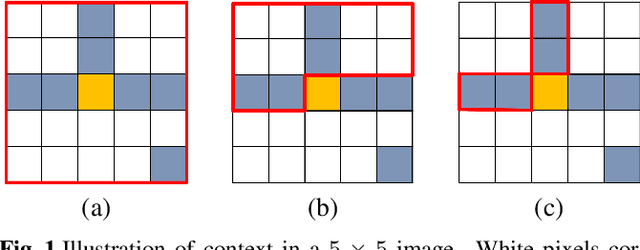
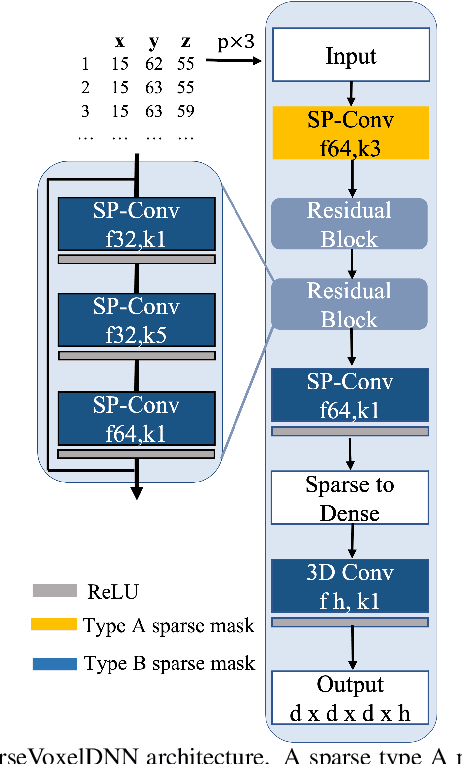

Most point cloud compression methods operate in the voxel or octree domain which is not the original representation of point clouds. Those representations either remove the geometric information or require high computational power for processing. In this paper, we propose a context-based lossless point cloud geometry compression that directly processes the point representation. Operating on a point representation allows us to preserve geometry correlation between points and thus to obtain an accurate context model while significantly reduce the computational cost. Specifically, our method uses a sparse convolution neural network to estimate the voxel occupancy sequentially from the x,y,z input data. Experimental results show that our method outperforms the state-of-the-art geometry compression standard from MPEG with average rate savings of 52% on a diverse set of point clouds from four different datasets.
Lossless Coding of Point Cloud Geometry using a Deep Generative Model
Jul 01, 2021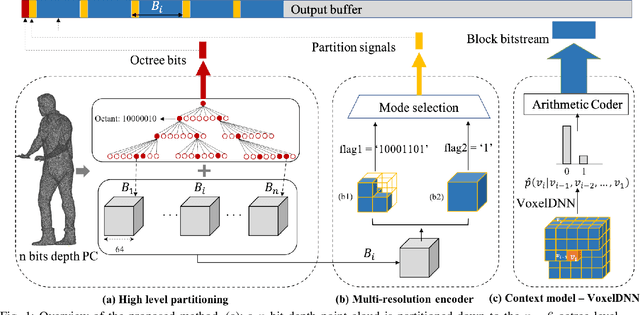
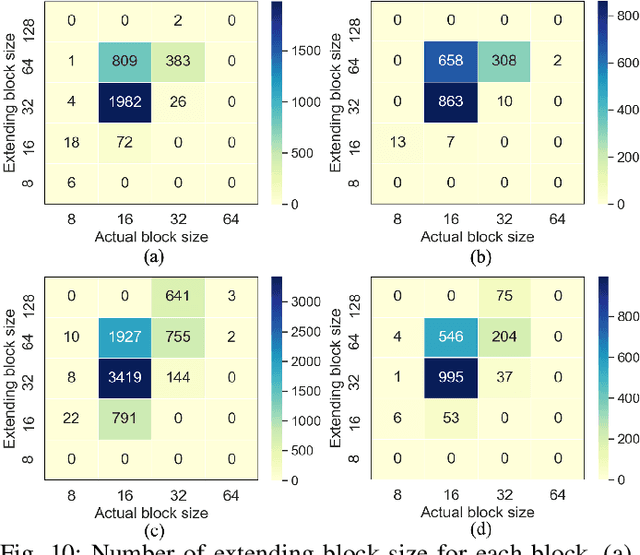

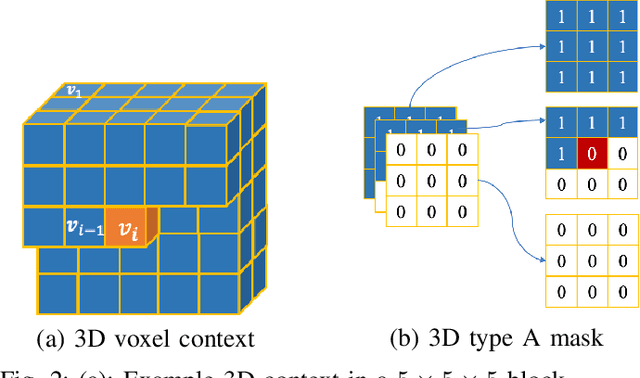
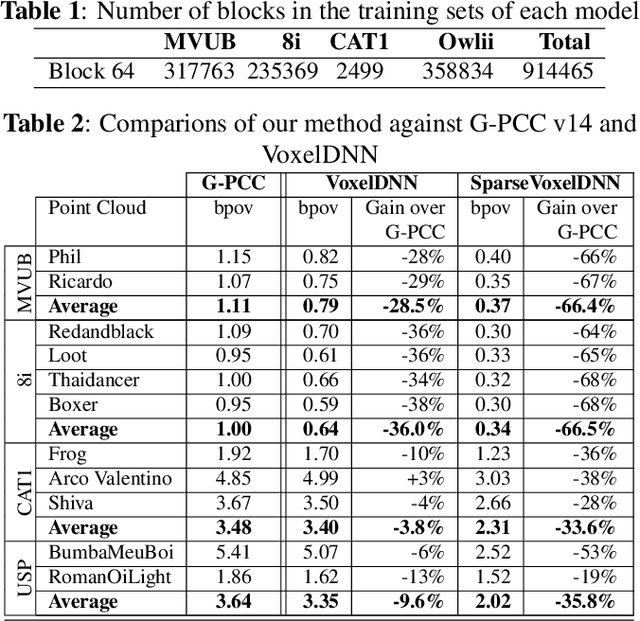
This paper proposes a lossless point cloud (PC) geometry compression method that uses neural networks to estimate the probability distribution of voxel occupancy. First, to take into account the PC sparsity, our method adaptively partitions a point cloud into multiple voxel block sizes. This partitioning is signalled via an octree. Second, we employ a deep auto-regressive generative model to estimate the occupancy probability of each voxel given the previously encoded ones. We then employ the estimated probabilities to code efficiently a block using a context-based arithmetic coder. Our context has variable size and can expand beyond the current block to learn more accurate probabilities. We also consider using data augmentation techniques to increase the generalization capability of the learned probability models, in particular in the presence of noise and lower-density point clouds. Experimental evaluation, performed on a variety of point clouds from four different datasets and with diverse characteristics, demonstrates that our method reduces significantly (by up to 30%) the rate for lossless coding compared to the state-of-the-art MPEG codec.
Multiscale deep context modeling for lossless point cloud geometry compression
Apr 20, 2021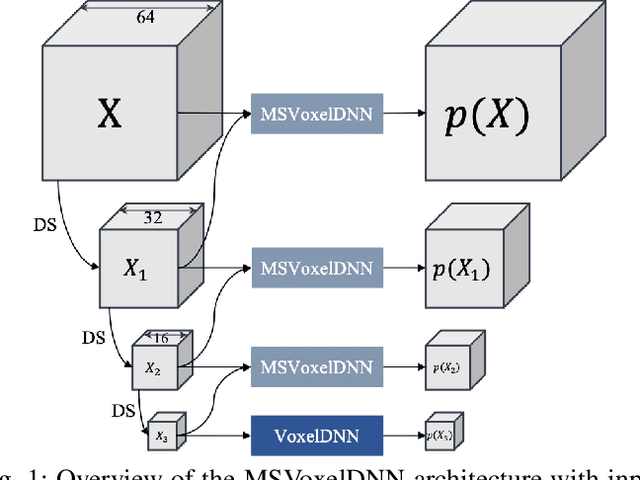
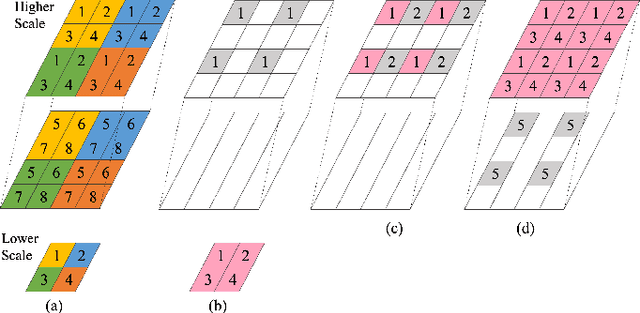
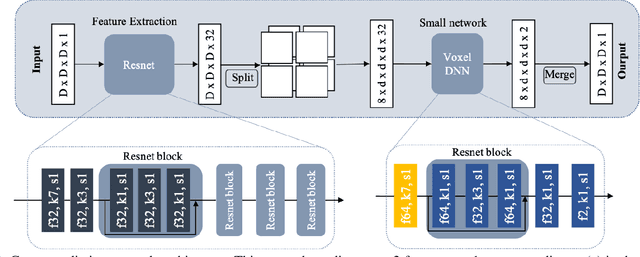
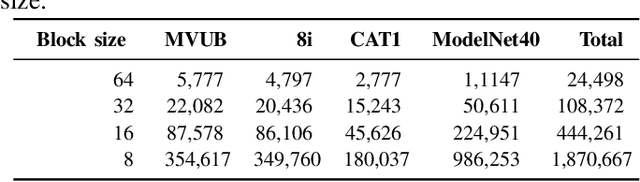
We propose a practical deep generative approach for lossless point cloud geometry compression, called MSVoxelDNN, and show that it significantly reduces the rate compared to the MPEG G-PCC codec. Our previous work based on autoregressive models (VoxelDNN) has a fast training phase, however, inference is slow as the occupancy probabilities are predicted sequentially, voxel by voxel. In this work, we employ a multiscale architecture which models voxel occupancy in coarse-to-fine order. At each scale, MSVoxelDNN divides voxels into eight conditionally independent groups, thus requiring a single network evaluation per group instead of one per voxel. We evaluate the performance of MSVoxelDNN on a set of point clouds from Microsoft Voxelized Upper Bodies (MVUB) and MPEG, showing that the current method speeds up encoding/decoding times significantly compared to the previous VoxelDNN, while having average rate saving over G-PCC of 17.5%. The implementation is available at https://github.com/Weafre/MSVoxelDNN.
Learning-based lossless compression of 3D point cloud geometry
Nov 30, 2020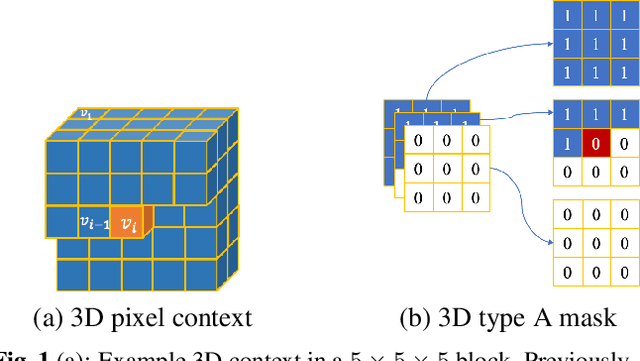
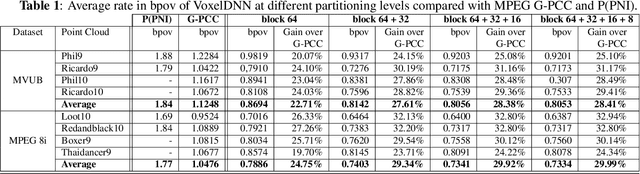
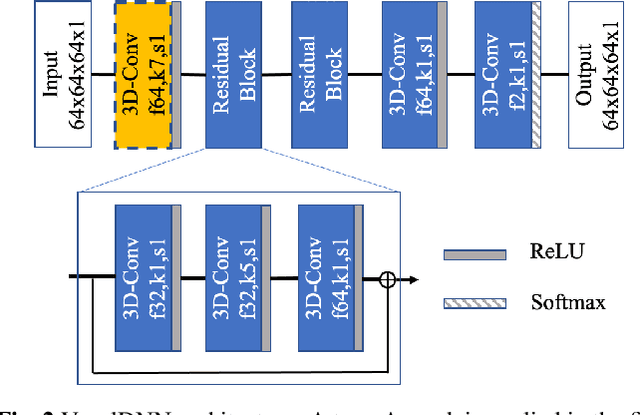
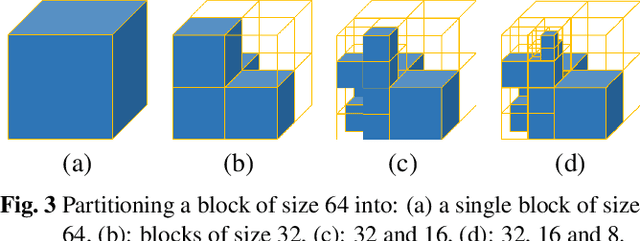
This paper presents a learning-based, lossless compression method for static point cloud geometry, based on context-adaptive arithmetic coding. Unlike most existing methods working in the octree domain, our encoder operates in a hybrid mode, mixing octree and voxel-based coding. We adaptively partition the point cloud into multi-resolution voxel blocks according to the point cloud structure and use octree to signal the partitioning. On the one hand, octree representation can eliminate the sparsity in the point cloud. On the other hand, in the voxel domain, convolutions can be naturally expressed, and geometric information (i.e., planes, surfaces, etc.) is explicitly processed by a neural network. Our context model benefits from these properties and learns a probability distribution of the voxels using a deep convolutional neural network with masked filters, called VoxelDNN. Experiments show that our method outperforms the state-of-the-art MPEG G-PCC standard with average rate savings of 28% on a diverse set of point clouds from the Microsoft Voxelized Upper Bodies (MVUB) and MPEG.