 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerative Models at the Frontier of Compression: A Survey on Generative Face Video Coding
Jun 09, 2025The rise of deep generative models has greatly advanced video compression, reshaping the paradigm of face video coding through their powerful capability for semantic-aware representation and lifelike synthesis. Generative Face Video Coding (GFVC) stands at the forefront of this revolution, which could characterize complex facial dynamics into compact latent codes for bitstream compactness at the encoder side and leverages powerful deep generative models to reconstruct high-fidelity face signal from the compressed latent codes at the decoder side. As such, this well-designed GFVC paradigm could enable high-fidelity face video communication at ultra-low bitrate ranges, far surpassing the capabilities of the latest Versatile Video Coding (VVC) standard. To pioneer foundational research and accelerate the evolution of GFVC, this paper presents the first comprehensive survey of GFVC technologies, systematically bridging critical gaps between theoretical innovation and industrial standardization. In particular, we first review a broad range of existing GFVC methods with different feature representations and optimization strategies, and conduct a thorough benchmarking analysis. In addition, we construct a large-scale GFVC-compressed face video database with subjective Mean Opinion Scores (MOSs) based on human perception, aiming to identify the most appropriate quality metrics tailored to GFVC. Moreover, we summarize the GFVC standardization potentials with a unified high-level syntax and develop a low-complexity GFVC system which are both expected to push forward future practical deployments and applications. Finally, we envision the potential of GFVC in industrial applications and deliberate on the current challenges and future opportunities.
Language-Guided Visual Perception Disentanglement for Image Quality Assessment and Conditional Image Generation
Mar 04, 2025Contrastive vision-language models, such as CLIP, have demonstrated excellent zero-shot capability across semantic recognition tasks, mainly attributed to the training on a large-scale I&1T (one Image with one Text) dataset. This kind of multimodal representations often blend semantic and perceptual elements, placing a particular emphasis on semantics. However, this could be problematic for popular tasks like image quality assessment (IQA) and conditional image generation (CIG), which typically need to have fine control on perceptual and semantic features. Motivated by the above facts, this paper presents a new multimodal disentangled representation learning framework, which leverages disentangled text to guide image disentanglement. To this end, we first build an I&2T (one Image with a perceptual Text and a semantic Text) dataset, which consists of disentangled perceptual and semantic text descriptions for an image. Then, the disentangled text descriptions are utilized as supervisory signals to disentangle pure perceptual representations from CLIP's original `coarse' feature space, dubbed DeCLIP. Finally, the decoupled feature representations are used for both image quality assessment (technical quality and aesthetic quality) and conditional image generation. Extensive experiments and comparisons have demonstrated the advantages of the proposed method on the two popular tasks. The dataset, code, and model will be available.
Generative AI for RF Sensing in IoT systems
Jul 10, 2024



The development of wireless sensing technologies, using signals such as Wi-Fi, infrared, and RF to gather environmental data, has significantly advanced within Internet of Things (IoT) systems. Among these, Radio Frequency (RF) sensing stands out for its cost-effective and non-intrusive monitoring of human activities and environmental changes. However, traditional RF sensing methods face significant challenges, including noise, interference, incomplete data, and high deployment costs, which limit their effectiveness and scalability. This paper investigates the potential of Generative AI (GenAI) to overcome these limitations within the IoT ecosystem. We provide a comprehensive review of state-of-the-art GenAI techniques, focusing on their application to RF sensing problems. By generating high-quality synthetic data, enhancing signal quality, and integrating multi-modal data, GenAI offers robust solutions for RF environment reconstruction, localization, and imaging. Additionally, GenAI's ability to generalize enables IoT devices to adapt to new environments and unseen tasks, improving their efficiency and performance. The main contributions of this article include a detailed analysis of the challenges in RF sensing, the presentation of innovative GenAI-based solutions, and the proposal of a unified framework for diverse RF sensing tasks. Through case studies, we demonstrate the effectiveness of integrating GenAI models, leading to advanced, scalable, and intelligent IoT systems.
Predictive Coding For Animation-Based Video Compression
Jul 09, 2023



We address the problem of efficiently compressing video for conferencing-type applications. We build on recent approaches based on image animation, which can achieve good reconstruction quality at very low bitrate by representing face motions with a compact set of sparse keypoints. However, these methods encode video in a frame-by-frame fashion, i.e. each frame is reconstructed from a reference frame, which limits the reconstruction quality when the bandwidth is larger. Instead, we propose a predictive coding scheme which uses image animation as a predictor, and codes the residual with respect to the actual target frame. The residuals can be in turn coded in a predictive manner, thus removing efficiently temporal dependencies. Our experiments indicate a significant bitrate gain, in excess of 70% compared to the HEVC video standard and over 30% compared to VVC, on a datasetof talking-head videos
Quality evaluation of point clouds: a novel no-reference approach using transformer-based architecture
Mar 15, 2023


With the increased interest in immersive experiences, point cloud came to birth and was widely adopted as the first choice to represent 3D media. Besides several distortions that could affect the 3D content spanning from acquisition to rendering, efficient transmission of such volumetric content over traditional communication systems stands at the expense of the delivered perceptual quality. To estimate the magnitude of such degradation, employing quality metrics became an inevitable solution. In this work, we propose a novel deep-based no-reference quality metric that operates directly on the whole point cloud without requiring extensive pre-processing, enabling real-time evaluation over both transmission and rendering levels. To do so, we use a novel model design consisting primarily of cross and self-attention layers, in order to learn the best set of local semantic affinities while keeping the best combination of geometry and color information in multiple levels from basic features extraction to deep representation modeling.
BASICS: Broad quality Assessment of Static point clouds In Compression Scenarios
Feb 09, 2023



Point clouds are now commonly used to represent 3D scenes in virtual world, in addition to 3D meshes. Their ease of capture enable various applications on mobile devices, such as smartphones or other microcontrollers. Point cloud compression is now at an advanced level and being standardized. Nevertheless, quality assessment databases, which is needed to develop better objective quality metrics, are still limited. In this work, we create a broad quality assessment database for static point clouds, mainly for telepresence scenario. For the sake of completeness, the created database is analyzed using the mean opinion scores, and it is used to benchmark several state-of-the-art quality estimators. The generated database is named Broad quality Assessment of Static point clouds In Compression Scenario (BASICS). Currently, the BASICS database is used as part of the ICIP 2023 Grand Challenge on Point Cloud Quality Assessment, and therefore only a part of the database has been made publicly available at the challenge website. The rest of the database will be made available once the challenge is over.
PCQA-GRAPHPOINT: Efficients Deep-Based Graph Metric For Point Cloud Quality Assessment
Nov 04, 2022Following the advent of immersive technologies and the increasing interest in representing interactive geometrical format, 3D Point Clouds (PC) have emerged as a promising solution and effective means to display 3D visual information. In addition to other challenges in immersive applications, objective and subjective quality assessments of compressed 3D content remain open problems and an area of research interest. Yet most of the efforts in the research area ignore the local geometrical structures between points representation. In this paper, we overcome this limitation by introducing a novel and efficient objective metric for Point Clouds Quality Assessment, by learning local intrinsic dependencies using Graph Neural Network (GNN). To evaluate the performance of our method, two well-known datasets have been used. The results demonstrate the effectiveness and reliability of our solution compared to state-of-the-art metrics.
A Hybrid Deep Animation Codec for Low-bitrate Video Conferencing
Jul 27, 2022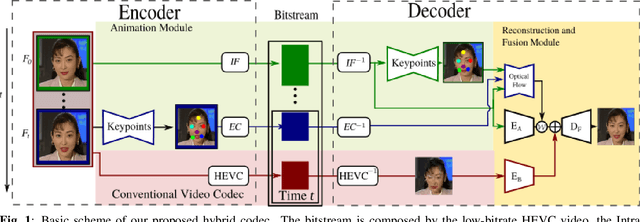
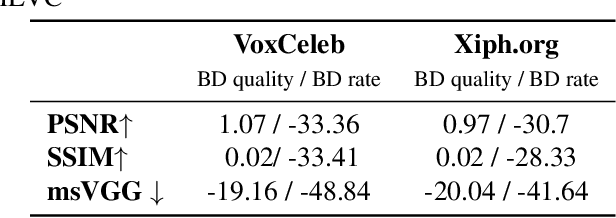

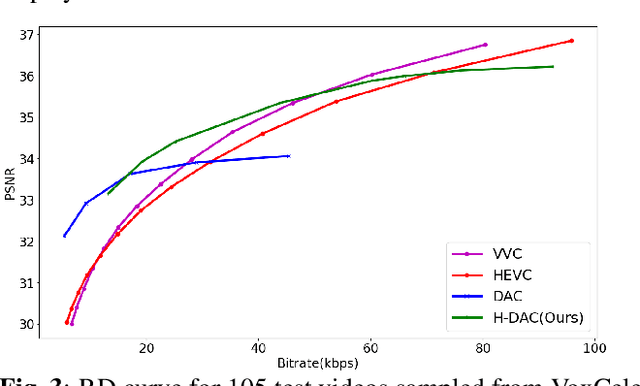
Deep generative models, and particularly facial animation schemes, can be used in video conferencing applications to efficiently compress a video through a sparse set of keypoints, without the need to transmit dense motion vectors. While these schemes bring significant coding gains over conventional video codecs at low bitrates, their performance saturates quickly when the available bandwidth increases. In this paper, we propose a layered, hybrid coding scheme to overcome this limitation. Specifically, we extend a codec based on facial animation by adding an auxiliary stream consisting of a very low bitrate version of the video, obtained through a conventional video codec (e.g., HEVC). The animated and auxiliary videos are combined through a novel fusion module. Our results show consistent average BD-Rate gains in excess of -30% on a large dataset of video conferencing sequences, extending the operational range of bitrates of a facial animation codec alone
Lossless Coding of Point Cloud Geometry using a Deep Generative Model
Jul 01, 2021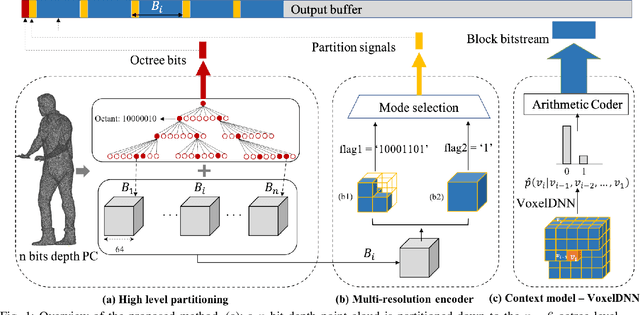
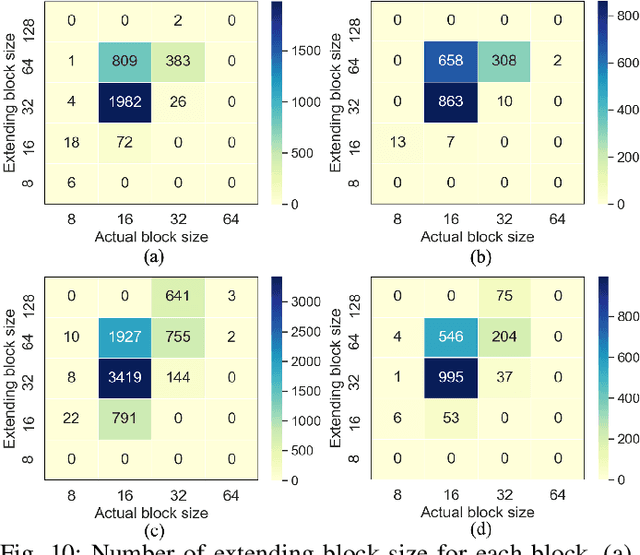

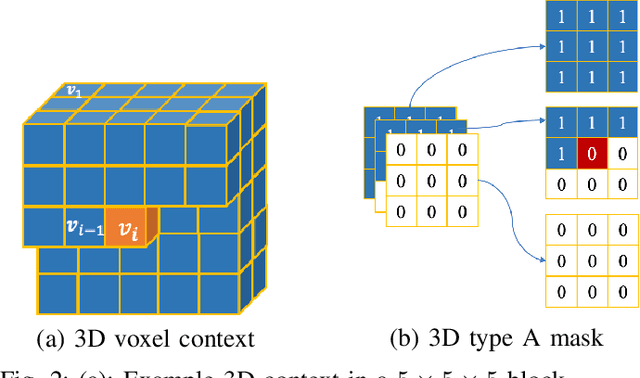
This paper proposes a lossless point cloud (PC) geometry compression method that uses neural networks to estimate the probability distribution of voxel occupancy. First, to take into account the PC sparsity, our method adaptively partitions a point cloud into multiple voxel block sizes. This partitioning is signalled via an octree. Second, we employ a deep auto-regressive generative model to estimate the occupancy probability of each voxel given the previously encoded ones. We then employ the estimated probabilities to code efficiently a block using a context-based arithmetic coder. Our context has variable size and can expand beyond the current block to learn more accurate probabilities. We also consider using data augmentation techniques to increase the generalization capability of the learned probability models, in particular in the presence of noise and lower-density point clouds. Experimental evaluation, performed on a variety of point clouds from four different datasets and with diverse characteristics, demonstrates that our method reduces significantly (by up to 30%) the rate for lossless coding compared to the state-of-the-art MPEG codec.
Multiscale deep context modeling for lossless point cloud geometry compression
Apr 20, 2021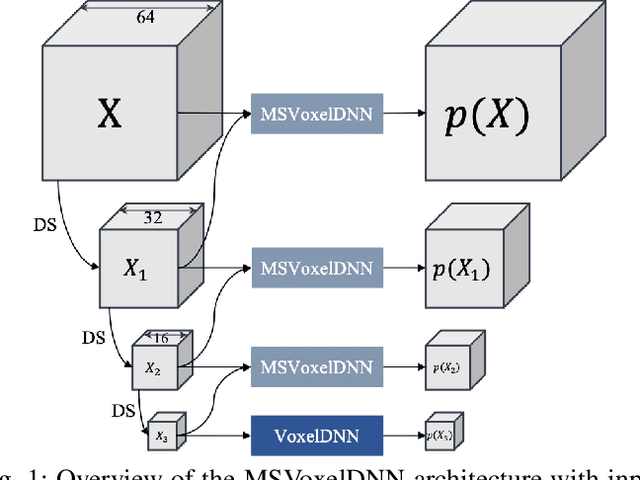
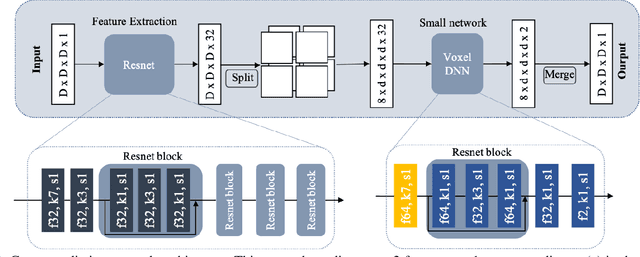
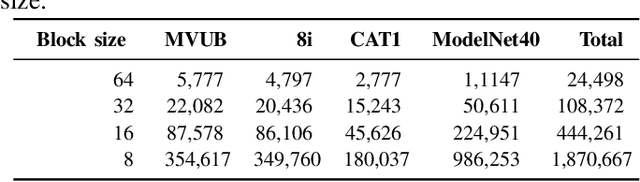
We propose a practical deep generative approach for lossless point cloud geometry compression, called MSVoxelDNN, and show that it significantly reduces the rate compared to the MPEG G-PCC codec. Our previous work based on autoregressive models (VoxelDNN) has a fast training phase, however, inference is slow as the occupancy probabilities are predicted sequentially, voxel by voxel. In this work, we employ a multiscale architecture which models voxel occupancy in coarse-to-fine order. At each scale, MSVoxelDNN divides voxels into eight conditionally independent groups, thus requiring a single network evaluation per group instead of one per voxel. We evaluate the performance of MSVoxelDNN on a set of point clouds from Microsoft Voxelized Upper Bodies (MVUB) and MPEG, showing that the current method speeds up encoding/decoding times significantly compared to the previous VoxelDNN, while having average rate saving over G-PCC of 17.5%. The implementation is available at https://github.com/Weafre/MSVoxelDNN.