 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReal-Time Position-Aware View Synthesis from Single-View Input
Dec 18, 2024



Recent advancements in view synthesis have significantly enhanced immersive experiences across various computer graphics and multimedia applications, including telepresence, and entertainment. By enabling the generation of new perspectives from a single input view, view synthesis allows users to better perceive and interact with their environment. However, many state-of-the-art methods, while achieving high visual quality, face limitations in real-time performance, which makes them less suitable for live applications where low latency is critical. In this paper, we present a lightweight, position-aware network designed for real-time view synthesis from a single input image and a target camera pose. The proposed framework consists of a Position Aware Embedding, modeled with a multi-layer perceptron, which efficiently maps positional information from the target pose to generate high dimensional feature maps. These feature maps, along with the input image, are fed into a Rendering Network that merges features from dual encoder branches to resolve both high level semantics and low level details, producing a realistic new view of the scene. Experimental results demonstrate that our method achieves superior efficiency and visual quality compared to existing approaches, particularly in handling complex translational movements without explicit geometric operations like warping. This work marks a step toward enabling real-time view synthesis from a single image for live and interactive applications.
BASICS: Broad quality Assessment of Static point clouds In Compression Scenarios
Feb 09, 2023



Point clouds are now commonly used to represent 3D scenes in virtual world, in addition to 3D meshes. Their ease of capture enable various applications on mobile devices, such as smartphones or other microcontrollers. Point cloud compression is now at an advanced level and being standardized. Nevertheless, quality assessment databases, which is needed to develop better objective quality metrics, are still limited. In this work, we create a broad quality assessment database for static point clouds, mainly for telepresence scenario. For the sake of completeness, the created database is analyzed using the mean opinion scores, and it is used to benchmark several state-of-the-art quality estimators. The generated database is named Broad quality Assessment of Static point clouds In Compression Scenario (BASICS). Currently, the BASICS database is used as part of the ICIP 2023 Grand Challenge on Point Cloud Quality Assessment, and therefore only a part of the database has been made publicly available at the challenge website. The rest of the database will be made available once the challenge is over.
A Study on Visual Perception of Light Field Content
Aug 07, 2020
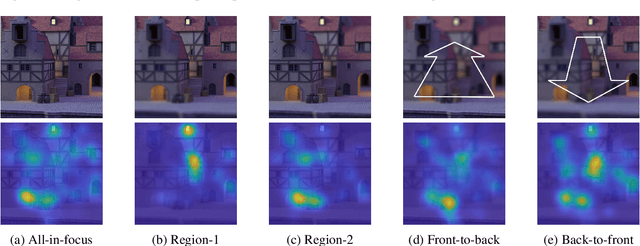

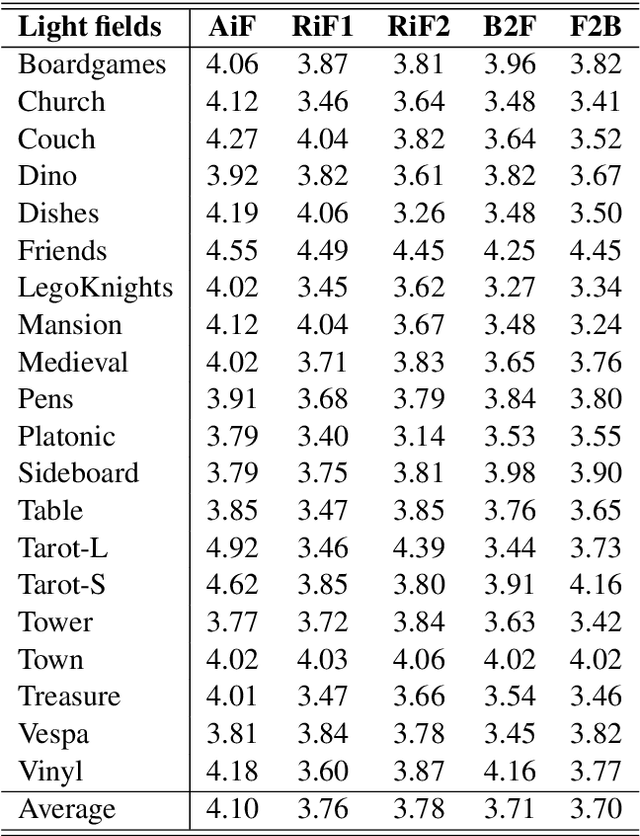
The effective design of visual computing systems depends heavily on the anticipation of visual attention, or saliency. While visual attention is well investigated for conventional 2D images and video, it is nevertheless a very active research area for emerging immersive media. In particular, visual attention of light fields (light rays of a scene captured by a grid of cameras or micro lenses) has only recently become a focus of research. As they may be rendered and consumed in various ways, a primary challenge that arises is the definition of what visual perception of light field content should be. In this work, we present a visual attention study on light field content. We conducted perception experiments displaying them to users in various ways and collected corresponding visual attention data. Our analysis highlights characteristics of user behaviour in light field imaging applications. The light field data set and attention data are provided with this paper.
ColorNet -- Estimating Colorfulness in Natural Images
Aug 22, 2019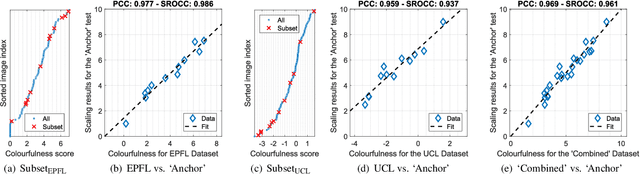
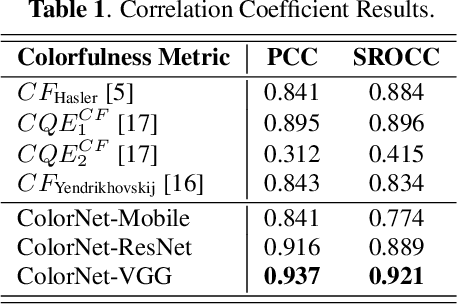
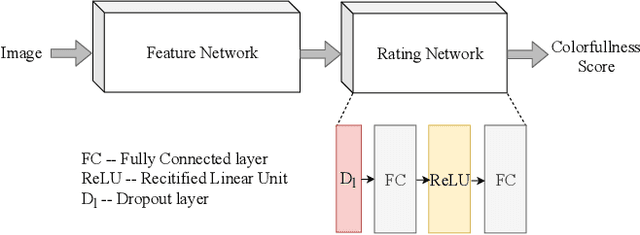

Measuring the colorfulness of a natural or virtual scene is critical for many applications in image processing field ranging from capturing to display. In this paper, we propose the first deep learning-based colorfulness estimation metric. For this purpose, we develop a color rating model which simultaneously learns to extracts the pertinent characteristic color features and the mapping from feature space to the ideal colorfulness scores for a variety of natural colored images. Additionally, we propose to overcome the lack of adequate annotated dataset problem by combining/aligning two publicly available colorfulness databases using the results of a new subjective test which employs a common subset of both databases. Using the obtained subjectively annotated dataset with 180 colored images, we finally demonstrate the efficacy of our proposed model over the traditional methods, both quantitatively and qualitatively.