 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuality Assessment of Super-Resolved Omnidirectional Image Quality Using Tangential Views
Jan 25, 2021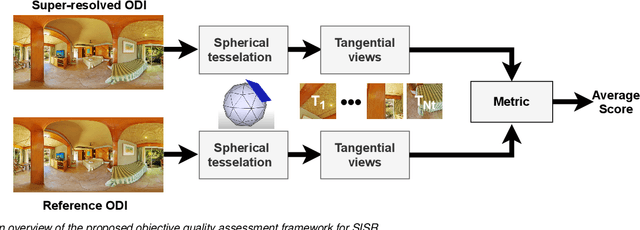


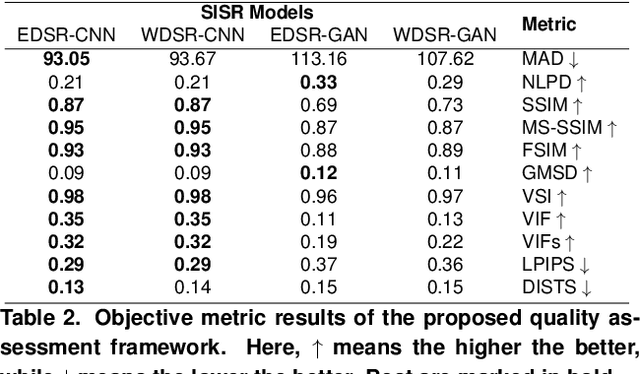
Omnidirectional images (ODIs), also known as 360-degree images, enable viewers to explore all directions of a given 360-degree scene from a fixed point. Designing an immersive imaging system with ODI is challenging as such systems require very large resolution coverage of the entire 360 viewing space to provide an enhanced quality of experience (QoE). Despite remarkable progress on single image super-resolution (SISR) methods with deep-learning techniques, no study for quality assessments of super-resolved ODIs exists to analyze the quality of such SISR techniques. This paper proposes an objective, full-reference quality assessment framework which studies quality measurement for ODIs generated by GAN-based and CNN-based SISR methods. The quality assessment framework offers to utilize tangential views to cope with the spherical nature of a given ODIs. The generated tangential views are distortion-free and can be efficiently scaled to high-resolution spherical data for SISR quality measurement. We extensively evaluate two state-of-the-art SISR methods using widely used full-reference SISR quality metrics adapted to our designed framework. In addition, our study reveals that most objective metric show high performance over CNN based SISR, while subjective tests favors GAN-based architectures.
Sub-Pixel Back-Projection Network For Lightweight Single Image Super-Resolution
Aug 03, 2020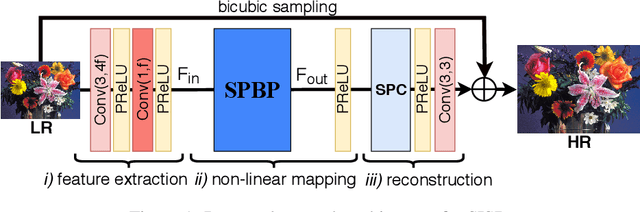
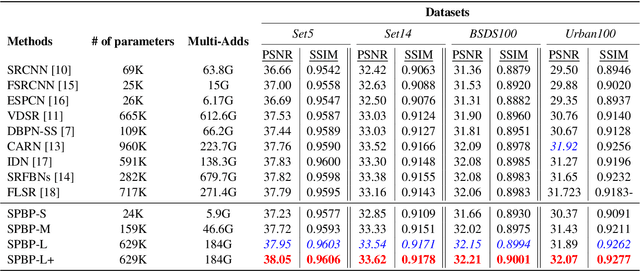
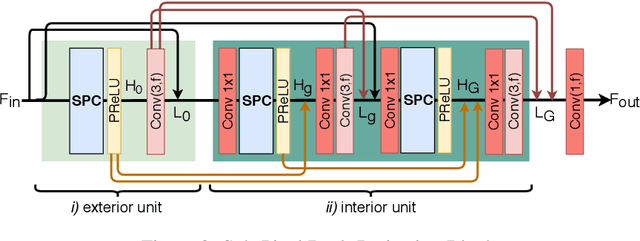
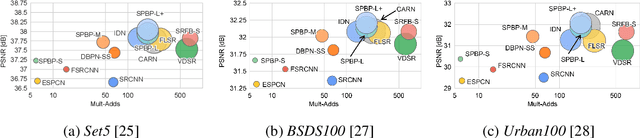
Convolutional neural network (CNN)-based methods have achieved great success for single-image superresolution (SISR). However, most models attempt to improve reconstruction accuracy while increasing the requirement of number of model parameters. To tackle this problem, in this paper, we study reducing the number of parameters and computational cost of CNN-based SISR methods while maintaining the accuracy of super-resolution reconstruction performance. To this end, we introduce a novel network architecture for SISR, which strikes a good trade-off between reconstruction quality and low computational complexity. Specifically, we propose an iterative back-projection architecture using sub-pixel convolution instead of deconvolution layers. We evaluate the performance of computational and reconstruction accuracy for our proposed model with extensive quantitative and qualitative evaluations. Experimental results reveal that our proposed method uses fewer parameters and reduces the computational cost while maintaining reconstruction accuracy against state-of-the-art SISR methods over well-known four SR benchmark datasets. Code is available at "https://github.com/supratikbanerjee/SubPixel-BackProjection_SuperResolution".
DublinCity: Annotated LiDAR Point Cloud and its Applications
Sep 06, 2019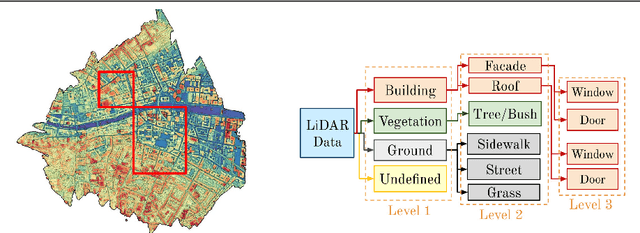
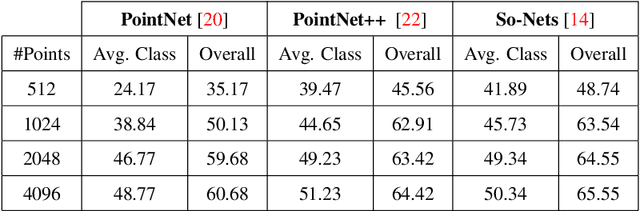
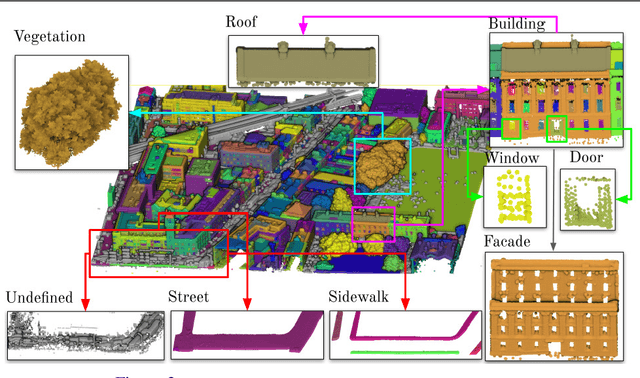
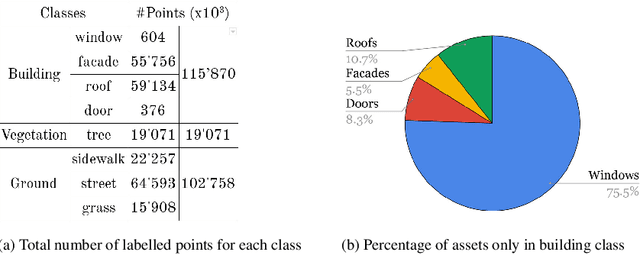
Scene understanding of full-scale 3D models of an urban area remains a challenging task. While advanced computer vision techniques offer cost-effective approaches to analyse 3D urban elements, a precise and densely labelled dataset is quintessential. The paper presents the first-ever labelled dataset for a highly dense Aerial Laser Scanning (ALS) point cloud at city-scale. This work introduces a novel benchmark dataset that includes a manually annotated point cloud for over 260 million laser scanning points into 100'000 (approx.) assets from Dublin LiDAR point cloud [12] in 2015. Objects are labelled into 13 classes using hierarchical levels of detail from large (i.e., building, vegetation and ground) to refined (i.e., window, door and tree) elements. To validate the performance of our dataset, two different applications are showcased. Firstly, the labelled point cloud is employed for training Convolutional Neural Networks (CNNs) to classify urban elements. The dataset is tested on the well-known state-of-the-art CNNs (i.e., PointNet, PointNet++ and So-Net). Secondly, the complete ALS dataset is applied as detailed ground truth for city-scale image-based 3D reconstruction.
Aesthetic Image Captioning From Weakly-Labelled Photographs
Aug 29, 2019


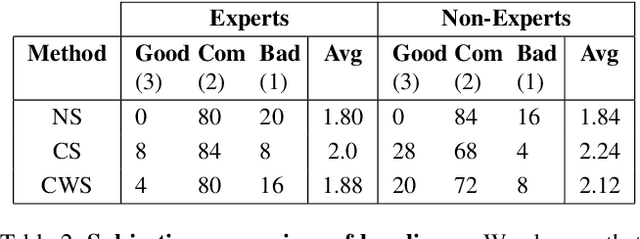
Aesthetic image captioning (AIC) refers to the multi-modal task of generating critical textual feedbacks for photographs. While in natural image captioning (NIC), deep models are trained in an end-to-end manner using large curated datasets such as MS-COCO, no such large-scale, clean dataset exists for AIC. Towards this goal, we propose an automatic cleaning strategy to create a benchmarking AIC dataset, by exploiting the images and noisy comments easily available from photography websites. We propose a probabilistic caption-filtering method for cleaning the noisy web-data, and compile a large-scale, clean dataset "AVA-Captions", (230, 000 images with 5 captions per image). Additionally, by exploiting the latent associations between aesthetic attributes, we propose a strategy for training the convolutional neural network (CNN) based visual feature extractor, the first component of the AIC framework. The strategy is weakly supervised and can be effectively used to learn rich aesthetic representations, without requiring expensive ground-truth annotations. We finally show-case a thorough analysis of the proposed contributions using automatic metrics and subjective evaluations.
ColorNet -- Estimating Colorfulness in Natural Images
Aug 22, 2019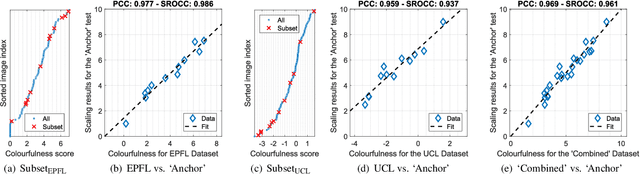
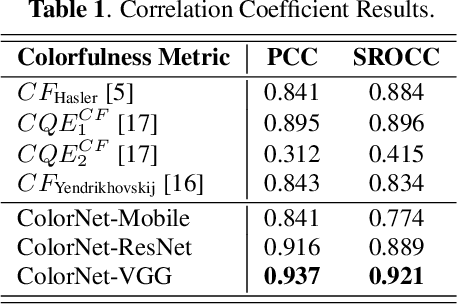
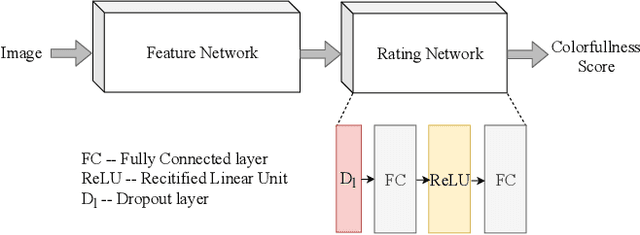

Measuring the colorfulness of a natural or virtual scene is critical for many applications in image processing field ranging from capturing to display. In this paper, we propose the first deep learning-based colorfulness estimation metric. For this purpose, we develop a color rating model which simultaneously learns to extracts the pertinent characteristic color features and the mapping from feature space to the ideal colorfulness scores for a variety of natural colored images. Additionally, we propose to overcome the lack of adequate annotated dataset problem by combining/aligning two publicly available colorfulness databases using the results of a new subjective test which employs a common subset of both databases. Using the obtained subjectively annotated dataset with 180 colored images, we finally demonstrate the efficacy of our proposed model over the traditional methods, both quantitatively and qualitatively.
Towards Generating Ambisonics Using Audio-Visual Cue for Virtual Reality
Aug 16, 2019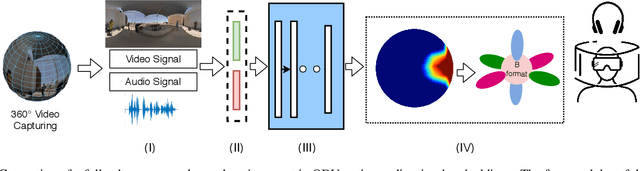



Ambisonics i.e., a full-sphere surround sound, is quintessential with 360-degree visual content to provide a realistic virtual reality (VR) experience. While 360-degree visual content capture gained a tremendous boost recently, the estimation of corresponding spatial sound is still challenging due to the required sound-field microphones or information about the sound-source locations. In this paper, we introduce a novel problem of generating Ambisonics in 360-degree videos using the audio-visual cue. With this aim, firstly, a novel 360-degree audio-visual video dataset of 265 videos is introduced with annotated sound-source locations. Secondly, a pipeline is designed for an automatic Ambisonic estimation problem. Benefiting from the deep learning-based audio-visual feature-embedding and prediction modules, our pipeline estimates the 3D sound-source locations and further use such locations to encode to the B-format. To benchmark our dataset and pipeline, we additionally propose evaluation criteria to investigate the performance using different 360-degree input representations. Our results demonstrate the efficacy of the proposed pipeline and open up a new area of research in 360-degree audio-visual analysis for future investigations.
Super-resolution of Omnidirectional Images Using Adversarial Learning
Aug 12, 2019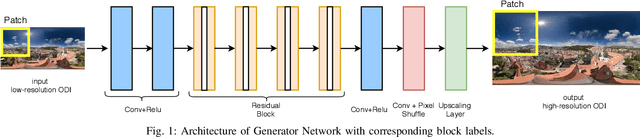

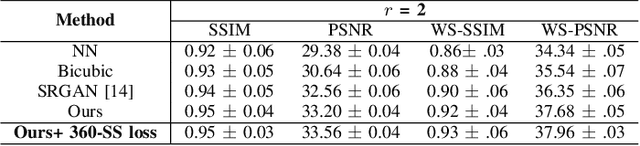
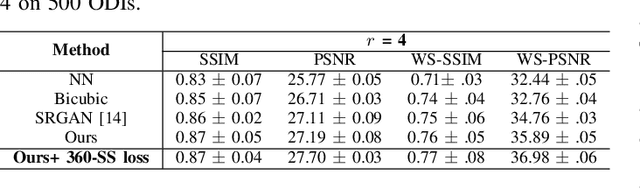
An omnidirectional image (ODI) enables viewers to look in every direction from a fixed point through a head-mounted display providing an immersive experience compared to that of a standard image. Designing immersive virtual reality systems with ODIs is challenging as they require high resolution content. In this paper, we study super-resolution for ODIs and propose an improved generative adversarial network based model which is optimized to handle the artifacts obtained in the spherical observational space. Specifically, we propose to use a fast PatchGAN discriminator, as it needs fewer parameters and improves the super-resolution at a fine scale. We also explore the generative models with adversarial learning by introducing a spherical-content specific loss function, called 360-SS. To train and test the performance of our proposed model we prepare a dataset of 4500 ODIs. Our results demonstrate the efficacy of the proposed method and identify new challenges in ODI super-resolution for future investigations.
Deep Tone Mapping Operator for High Dynamic Range Images
Aug 12, 2019

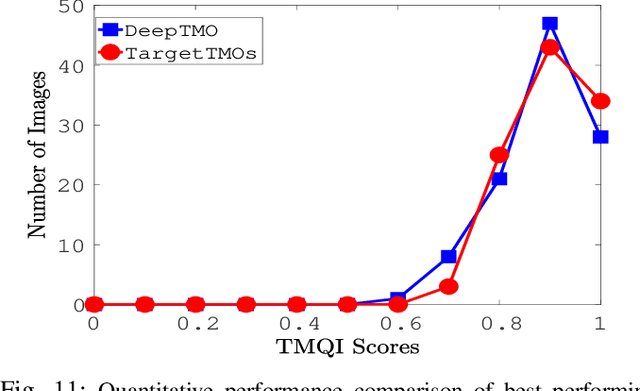
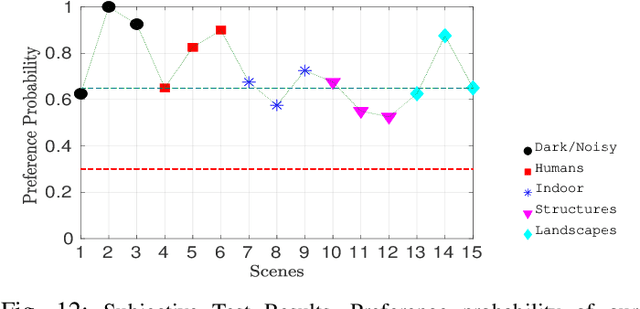
A computationally fast tone mapping operator (TMO) that can quickly adapt to a wide spectrum of high dynamic range (HDR) content is quintessential for visualization on varied low dynamic range (LDR) output devices such as movie screens or standard displays. Existing TMOs can successfully tone-map only a limited number of HDR content and require an extensive parameter tuning to yield the best subjective-quality tone-mapped output. In this paper, we address this problem by proposing a fast, parameter-free and scene-adaptable deep tone mapping operator (DeepTMO) that yields a high-resolution and high-subjective quality tone mapped output. Based on conditional generative adversarial network (cGAN), DeepTMO not only learns to adapt to vast scenic-content (e.g., outdoor, indoor, human, structures, etc.) but also tackles the HDR related scene-specific challenges such as contrast and brightness, while preserving the fine-grained details. We explore 4 possible combinations of Generator-Discriminator architectural designs to specifically address some prominent issues in HDR related deep-learning frameworks like blurring, tiling patterns and saturation artifacts. By exploring different influences of scales, loss-functions and normalization layers under a cGAN setting, we conclude with adopting a multi-scale model for our task. To further leverage on the large-scale availability of unlabeled HDR data, we train our network by generating targets using an objective HDR quality metric, namely Tone Mapping Image Quality Index (TMQI). We demonstrate results both quantitatively and qualitatively, and showcase that our DeepTMO generates high-resolution, high-quality output images over a large spectrum of real-world scenes. Finally, we evaluate the perceived quality of our results by conducting a pair-wise subjective study which confirms the versatility of our method.