 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuality evaluation of point clouds: a novel no-reference approach using transformer-based architecture
Mar 15, 2023


With the increased interest in immersive experiences, point cloud came to birth and was widely adopted as the first choice to represent 3D media. Besides several distortions that could affect the 3D content spanning from acquisition to rendering, efficient transmission of such volumetric content over traditional communication systems stands at the expense of the delivered perceptual quality. To estimate the magnitude of such degradation, employing quality metrics became an inevitable solution. In this work, we propose a novel deep-based no-reference quality metric that operates directly on the whole point cloud without requiring extensive pre-processing, enabling real-time evaluation over both transmission and rendering levels. To do so, we use a novel model design consisting primarily of cross and self-attention layers, in order to learn the best set of local semantic affinities while keeping the best combination of geometry and color information in multiple levels from basic features extraction to deep representation modeling.
PCQA-GRAPHPOINT: Efficients Deep-Based Graph Metric For Point Cloud Quality Assessment
Nov 04, 2022Following the advent of immersive technologies and the increasing interest in representing interactive geometrical format, 3D Point Clouds (PC) have emerged as a promising solution and effective means to display 3D visual information. In addition to other challenges in immersive applications, objective and subjective quality assessments of compressed 3D content remain open problems and an area of research interest. Yet most of the efforts in the research area ignore the local geometrical structures between points representation. In this paper, we overcome this limitation by introducing a novel and efficient objective metric for Point Clouds Quality Assessment, by learning local intrinsic dependencies using Graph Neural Network (GNN). To evaluate the performance of our method, two well-known datasets have been used. The results demonstrate the effectiveness and reliability of our solution compared to state-of-the-art metrics.
G-SemTMO: Tone Mapping with a Trainable Semantic Graph
Aug 30, 2022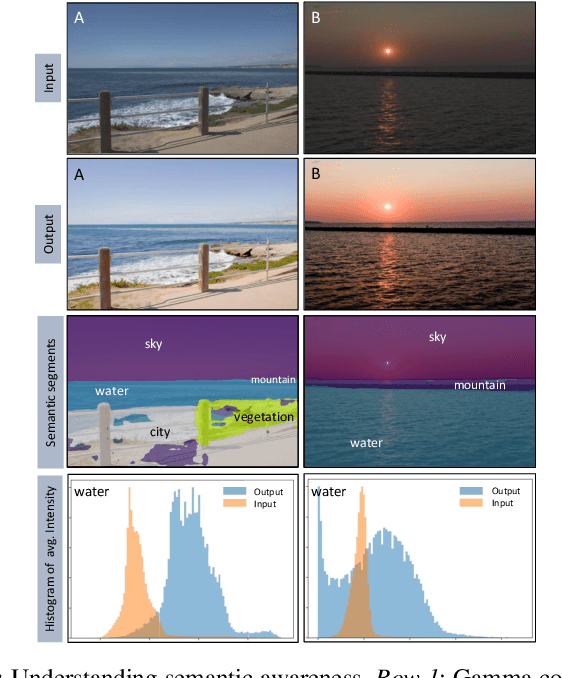
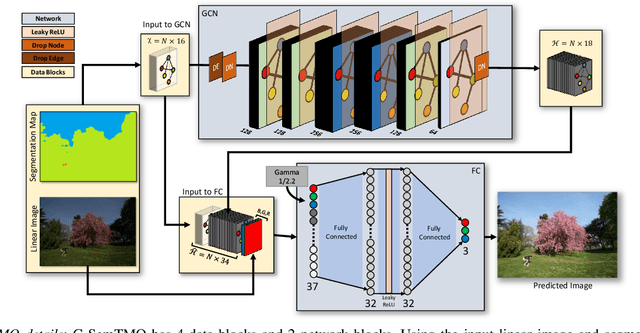
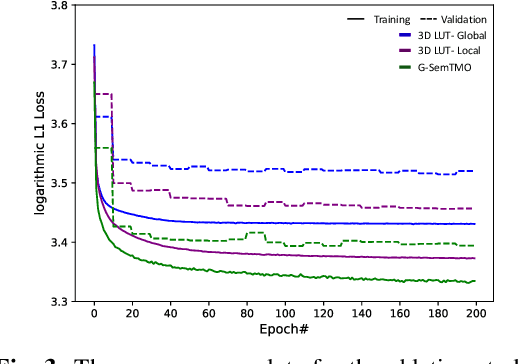

A Tone Mapping Operator (TMO) is required to render images with a High Dynamic Range (HDR) on media with limited dynamic capabilities. TMOs compress the dynamic range with the aim of preserving the visually perceptual cues of the scene. Previous literature has established the benefits of TMOs being semantic aware, understanding the content in the scene to preserve the cues better. Expert photographers analyze the semantic and the contextual information of a scene and decide tonal transformations or local luminance adjustments. This process can be considered a manual analogy to tone mapping. In this work, we draw inspiration from an expert photographer's approach and present a Graph-based Semantic-aware Tone Mapping Operator, G-SemTMO. We leverage semantic information as well as the contextual information of the scene in the form of a graph capturing the spatial arrangements of its semantic segments. Using Graph Convolutional Network (GCN), we predict intermediate parameters called Semantic Hints and use these parameters to apply tonal adjustments locally to different semantic segments in the image. In addition, we also introduce LocHDR, a dataset of 781 HDR images tone mapped manually by an expert photo-retoucher with local tonal enhancements. We conduct ablation studies to show that our approach, G-SemTMO\footnote{Code and dataset to be published with the final version of the manuscript}, can learn both global and local tonal transformations from a pair of input linear and manually retouched images by leveraging the semantic graphs and produce better results than both classical and learning based TMOs. We also conduct ablation experiments to validate the advantage of using GCN.
A deep perceptual metric for 3D point clouds
Feb 25, 2021

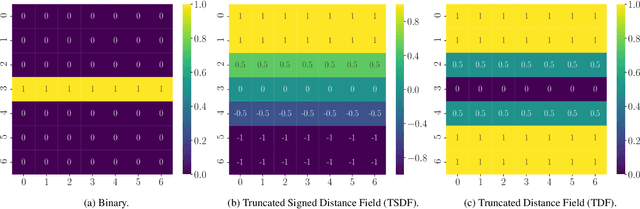
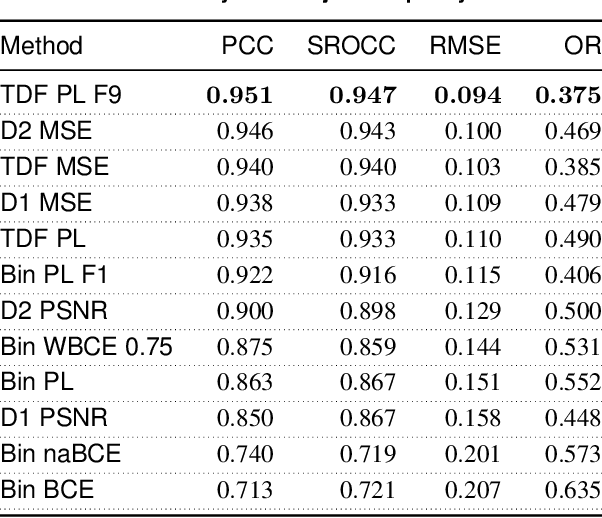
Point clouds are essential for storage and transmission of 3D content. As they can entail significant volumes of data, point cloud compression is crucial for practical usage. Recently, point cloud geometry compression approaches based on deep neural networks have been explored. In this paper, we evaluate the ability to predict perceptual quality of typical voxel-based loss functions employed to train these networks. We find that the commonly used focal loss and weighted binary cross entropy are poorly correlated with human perception. We thus propose a perceptual loss function for 3D point clouds which outperforms existing loss functions on the ICIP2020 subjective dataset. In addition, we propose a novel truncated distance field voxel grid representation and find that it leads to sparser latent spaces and loss functions that are more correlated with perceived visual quality compared to a binary representation. The source code is available at https://github.com/mauriceqch/2021_pc_perceptual_loss.
Improved Deep Point Cloud Geometry Compression
Jun 24, 2020

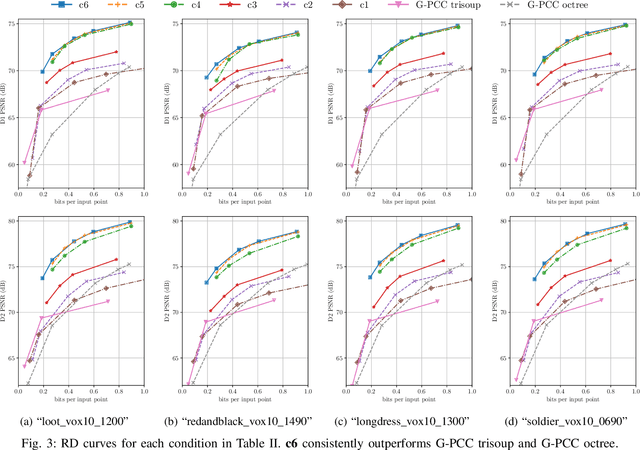

Point clouds have been recognized as a crucial data structure for 3D content and are essential in a number of applications such as virtual and mixed reality, autonomous driving, cultural heritage, etc. In this paper, we propose a set of contributions to improve deep point cloud compression, i.e.: using a scale hyperprior model for entropy coding; employing deeper transforms; a different balancing weight in the focal loss; optimal thresholding for decoding; and sequential model training. In addition, we present an extensive ablation study on the impact of each of these factors, in order to provide a better understanding about why they improve RD performance. An optimal combination of the proposed improvements achieves BD-PSNR gains over G-PCC trisoup and octree of 5.50 (6.48) dB and 6.84 (5.95) dB, respectively, when using the point-to-point (point-to-plane) metric. Code is available at https://github.com/mauriceqch/pcc_geo_cnn_v2 .
Folding-based compression of point cloud attributes
Feb 11, 2020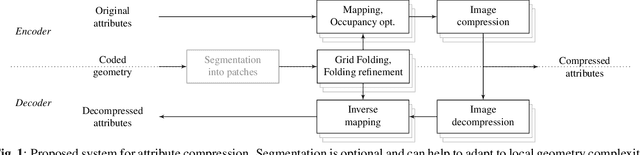

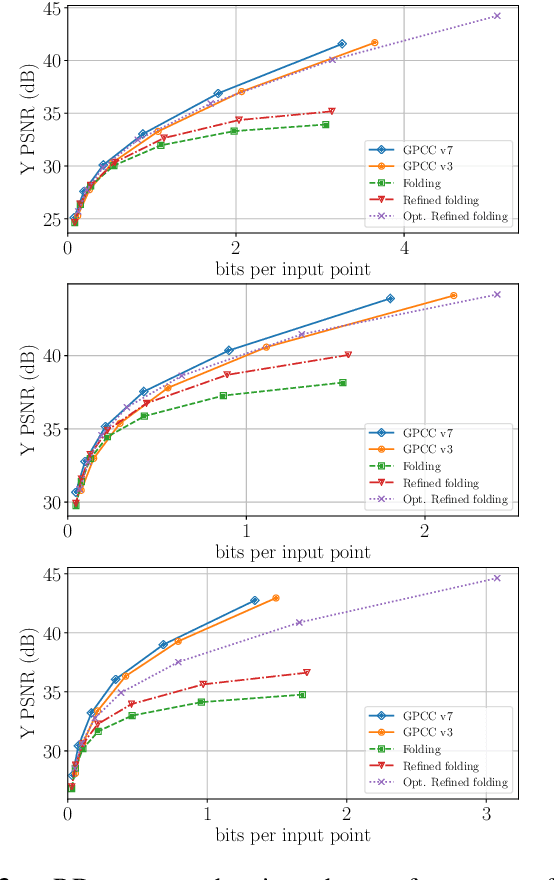
Existing techniques to compress point cloud attributes leverage either geometric or video-based compression tools. In this work, we explore a radically different approach inspired by recent advances in point cloud representation learning. A point cloud can be interpreted as a 2D manifold in a 3D space. As that, its attributes could be mapped onto a folded 2D grid; compressed through a conventional 2D image codec; and mapped back at the decoder side to recover attributes on 3D points. The folding operation is optimized by employing a deep neural network as a parametric folding function. As mapping is lossy in nature, we propose several strategies to refine it in such a way that attributes in 3D can be mapped to the 2D grid with minimal distortion. This approach can be flexibly applied to portions of point clouds in order to better adapt to local geometric complexity, and thus has a potential for being used as a tool in existing or future coding pipelines. Our preliminary results show that the proposed folding-based coding scheme can already reach performance similar to the latest MPEG GPCC codec.
Generating Relevant Counter-Examples from a Positive Unlabeled Dataset for Image Classification
Oct 04, 2019

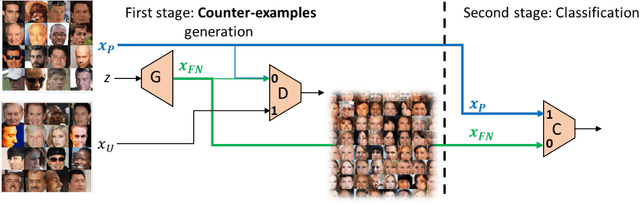

With surge of available but unlabeled data, Positive Unlabeled (PU) learning is becoming a thriving challenge. This work deals with this demanding task for which recent GAN-based PU approaches have demonstrated promising results. Generative adversarial Networks (GANs) are not hampered by deterministic bias or need for specific dimensionality. However, existing GAN-based PU approaches also present some drawbacks such as sensitive dependence to prior knowledge, a cumbersome architecture or first-stage overfitting. To settle these issues, we propose to incorporate a biased PU risk within the standard GAN discriminator loss function. In this manner, the discriminator is constrained to request the generator to converge towards the unlabeled samples distribution while diverging from the positive samples distribution. This enables the proposed model, referred to as D-GAN, to exclusively learn the counter-examples distribution without prior knowledge. Experiments demonstrate that our approach outperforms state-of-the-art PU methods without prior by overcoming their issues.
Self-supervised learning for autonomous vehicles perception: A conciliation between analytical and learning methods
Oct 03, 2019

This article mainly aims at motivating more investigations on self-supervised learning (SSL) perception techniques and their applications in autonomous driving. Such approaches are of broad interest as they can improve analytical methods performances, for example to perceive farther and more accurately spatially or temporally. In the meantime, they can also reduce the need of hand-labeled training data for learning methods, while offering the possibility to update the learning models into an online process. This can help an autonomous system to deal with unexpected changing conditions in the ego-vehicle environment. In all, this article firstly highlights the analytical and learning tools which may be interesting for improving or developping SSL techniques. Then, it presents the insights and correlations between existing autonomous driving perception SSL techniques, and some of their remaining limitations opening up some future research perspectives.
Deep Tone Mapping Operator for High Dynamic Range Images
Aug 12, 2019

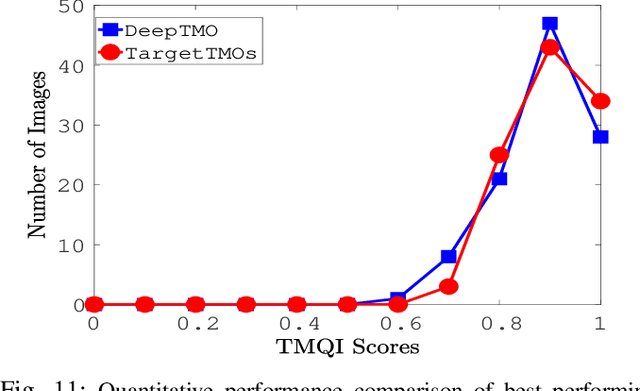
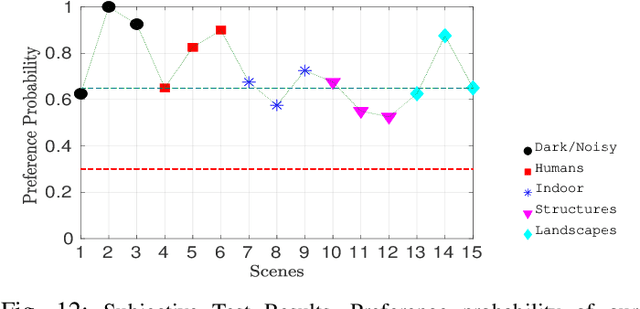
A computationally fast tone mapping operator (TMO) that can quickly adapt to a wide spectrum of high dynamic range (HDR) content is quintessential for visualization on varied low dynamic range (LDR) output devices such as movie screens or standard displays. Existing TMOs can successfully tone-map only a limited number of HDR content and require an extensive parameter tuning to yield the best subjective-quality tone-mapped output. In this paper, we address this problem by proposing a fast, parameter-free and scene-adaptable deep tone mapping operator (DeepTMO) that yields a high-resolution and high-subjective quality tone mapped output. Based on conditional generative adversarial network (cGAN), DeepTMO not only learns to adapt to vast scenic-content (e.g., outdoor, indoor, human, structures, etc.) but also tackles the HDR related scene-specific challenges such as contrast and brightness, while preserving the fine-grained details. We explore 4 possible combinations of Generator-Discriminator architectural designs to specifically address some prominent issues in HDR related deep-learning frameworks like blurring, tiling patterns and saturation artifacts. By exploring different influences of scales, loss-functions and normalization layers under a cGAN setting, we conclude with adopting a multi-scale model for our task. To further leverage on the large-scale availability of unlabeled HDR data, we train our network by generating targets using an objective HDR quality metric, namely Tone Mapping Image Quality Index (TMQI). We demonstrate results both quantitatively and qualitatively, and showcase that our DeepTMO generates high-resolution, high-quality output images over a large spectrum of real-world scenes. Finally, we evaluate the perceived quality of our results by conducting a pair-wise subjective study which confirms the versatility of our method.
Learning Convolutional Transforms for Lossy Point Cloud Geometry Compression
Mar 20, 2019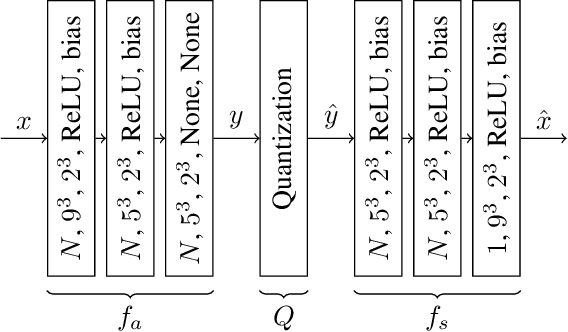



Efficient point cloud compression is fundamental to enable the deployment of virtual and mixed reality applications, since the number of points to code can range in the order of millions. In this paper, we present a novel data-driven geometry compression method for static point clouds based on learned convolutional transforms and uniform quantization. We perform joint optimization of both rate and distortion using a trade-off parameter. In addition, we cast the decoding process as a binary classification of the point cloud occupancy map. Our method outperforms the MPEG reference solution in terms of rate-distortion on the Microsoft Voxelized Upper Bodies dataset with 51.5% BDBR savings on average. Moreover, while octree-based methods face exponential diminution of the number of points at low bitrates, our method still produces high resolution outputs even at low bitrates.