 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-supervised classification of dynamic obstacles using the temporal information provided by videos
Oct 21, 2019



Nowadays, autonomous driving systems can detect, segment, and classify the surrounding obstacles using a monocular camera. However, state-of-the-art methods solving these tasks generally perform a fully supervised learning process and require a large amount of training labeled data. On another note, some self-supervised learning approaches can deal with detection and segmentation of dynamic obstacles using the temporal information available in video sequences. In this work, we propose in addition to classifiy the detected obstacles depending on their motion pattern. We present a novel self-supervised framework consisting of learning offline clusters from temporal patch sequences and using these clusters as pseudo labels to train a real-time image classifier. The presented model outperforms state-of-the-art unsupervised image classification methods on BDD100K dataset.
Generating Relevant Counter-Examples from a Positive Unlabeled Dataset for Image Classification
Oct 04, 2019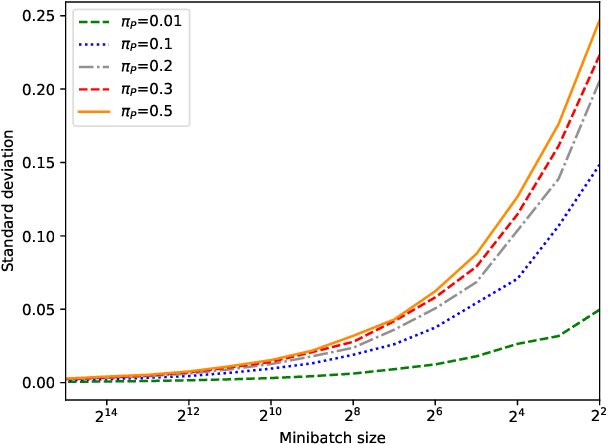

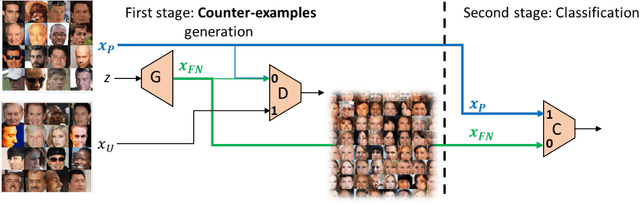

With surge of available but unlabeled data, Positive Unlabeled (PU) learning is becoming a thriving challenge. This work deals with this demanding task for which recent GAN-based PU approaches have demonstrated promising results. Generative adversarial Networks (GANs) are not hampered by deterministic bias or need for specific dimensionality. However, existing GAN-based PU approaches also present some drawbacks such as sensitive dependence to prior knowledge, a cumbersome architecture or first-stage overfitting. To settle these issues, we propose to incorporate a biased PU risk within the standard GAN discriminator loss function. In this manner, the discriminator is constrained to request the generator to converge towards the unlabeled samples distribution while diverging from the positive samples distribution. This enables the proposed model, referred to as D-GAN, to exclusively learn the counter-examples distribution without prior knowledge. Experiments demonstrate that our approach outperforms state-of-the-art PU methods without prior by overcoming their issues.
Self-supervised learning for autonomous vehicles perception: A conciliation between analytical and learning methods
Oct 03, 2019

This article mainly aims at motivating more investigations on self-supervised learning (SSL) perception techniques and their applications in autonomous driving. Such approaches are of broad interest as they can improve analytical methods performances, for example to perceive farther and more accurately spatially or temporally. In the meantime, they can also reduce the need of hand-labeled training data for learning methods, while offering the possibility to update the learning models into an online process. This can help an autonomous system to deal with unexpected changing conditions in the ego-vehicle environment. In all, this article firstly highlights the analytical and learning tools which may be interesting for improving or developping SSL techniques. Then, it presents the insights and correlations between existing autonomous driving perception SSL techniques, and some of their remaining limitations opening up some future research perspectives.
Real Time Lidar and Radar High-Level Fusion for Obstacle Detection and Tracking with evaluation on a ground truth
Jul 30, 2018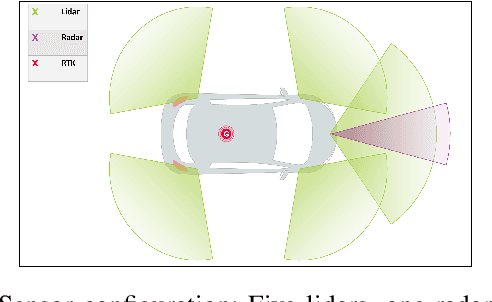
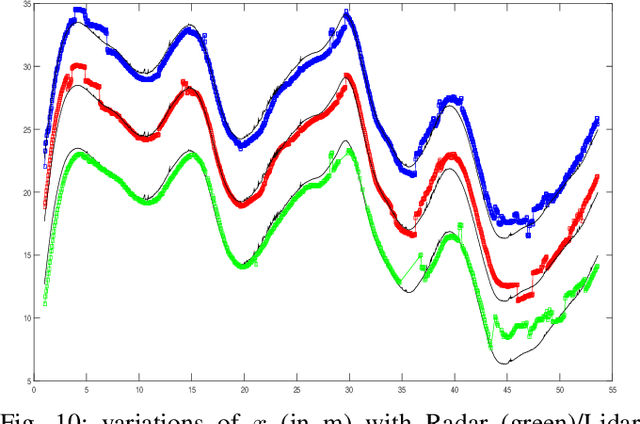

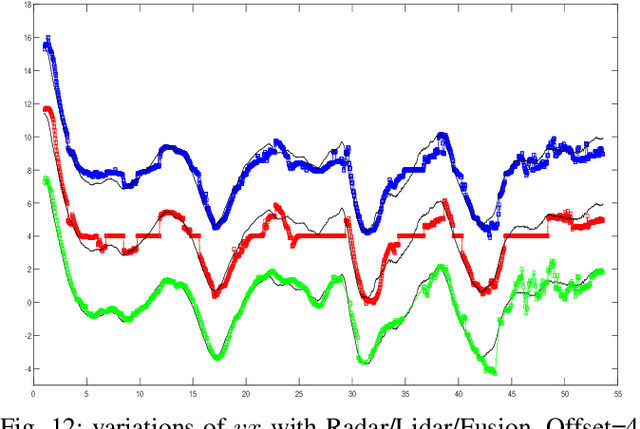
- Both Lidars and Radars are sensors for obstacle detection. While Lidars are very accurate on obstacles positions and less accurate on their velocities, Radars are more precise on obstacles velocities and less precise on their positions. Sensor fusion between Lidar and Radar aims at improving obstacle detection using advantages of the two sensors. The present paper proposes a real-time Lidar/Radar data fusion algorithm for obstacle detection and tracking based on the global nearest neighbour standard filter (GNN). This algorithm is implemented and embedded in an automative vehicle as a component generated by a real-time multisensor software. The benefits of data fusion comparing with the use of a single sensor are illustrated through several tracking scenarios (on a highway and on a bend) and using real-time kinematic sensors mounted on the ego and tracked vehicles as a ground truth.
Automatic generation of ground truth for the evaluation of obstacle detection and tracking techniques
Jul 16, 2018
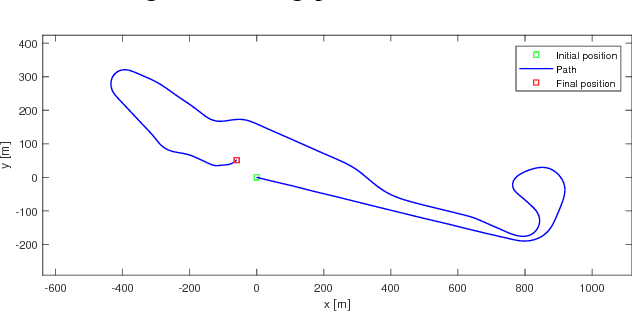
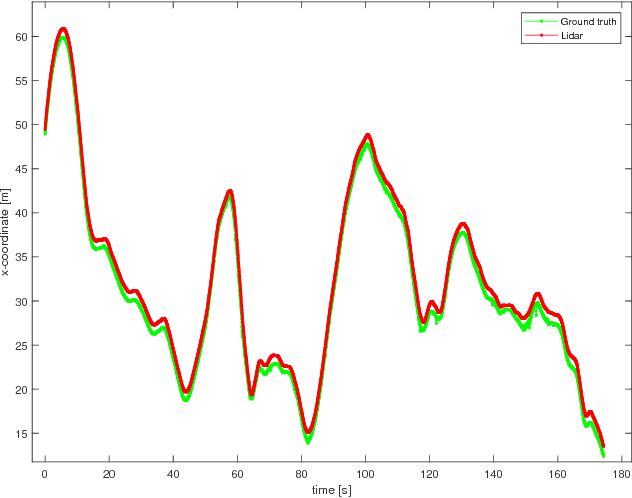
As automated vehicles are getting closer to becoming a reality, it will become mandatory to be able to characterise the performance of their obstacle detection systems. This validation process requires large amounts of ground-truth data, which is currently generated by manually annotation. In this paper, we propose a novel methodology to generate ground-truth kinematics datasets for specific objects in real-world scenes. Our procedure requires no annotation whatsoever, human intervention being limited to sensors calibration. We present the recording platform which was exploited to acquire the reference data and a detailed and thorough analytical study of the propagation of errors in our procedure. This allows us to provide detailed precision metrics for each and every data item in our datasets. Finally some visualisations of the acquired data are given.