 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerating Relevant Counter-Examples from a Positive Unlabeled Dataset for Image Classification
Paper and Code
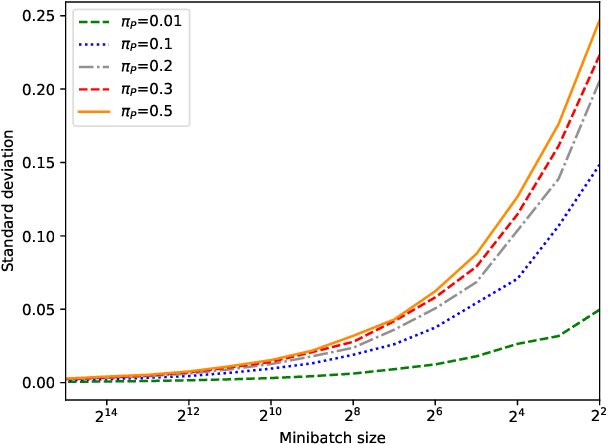

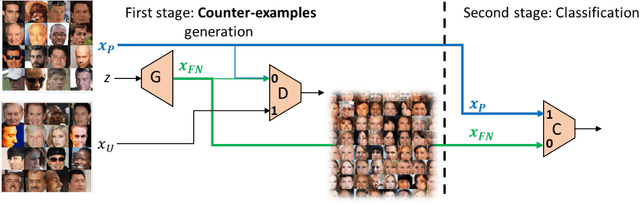

With surge of available but unlabeled data, Positive Unlabeled (PU) learning is becoming a thriving challenge. This work deals with this demanding task for which recent GAN-based PU approaches have demonstrated promising results. Generative adversarial Networks (GANs) are not hampered by deterministic bias or need for specific dimensionality. However, existing GAN-based PU approaches also present some drawbacks such as sensitive dependence to prior knowledge, a cumbersome architecture or first-stage overfitting. To settle these issues, we propose to incorporate a biased PU risk within the standard GAN discriminator loss function. In this manner, the discriminator is constrained to request the generator to converge towards the unlabeled samples distribution while diverging from the positive samples distribution. This enables the proposed model, referred to as D-GAN, to exclusively learn the counter-examples distribution without prior knowledge. Experiments demonstrate that our approach outperforms state-of-the-art PU methods without prior by overcoming their issues.