 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploiting Sparsity in Automotive Radar Object Detection Networks
Aug 15, 2023Having precise perception of the environment is crucial for ensuring the secure and reliable functioning of autonomous driving systems. Radar object detection networks are one fundamental part of such systems. CNN-based object detectors showed good performance in this context, but they require large compute resources. This paper investigates sparse convolutional object detection networks, which combine powerful grid-based detection with low compute resources. We investigate radar specific challenges and propose sparse kernel point pillars (SKPP) and dual voxel point convolutions (DVPC) as remedies for the grid rendering and sparse backbone architectures. We evaluate our SKPP-DPVCN architecture on nuScenes, which outperforms the baseline by 5.89% and the previous state of the art by 4.19% in Car AP4.0. Moreover, SKPP-DPVCN reduces the average scale error (ASE) by 21.41% over the baseline.
Improved Multi-Scale Grid Rendering of Point Clouds for Radar Object Detection Networks
May 25, 2023



Architectures that first convert point clouds to a grid representation and then apply convolutional neural networks achieve good performance for radar-based object detection. However, the transfer from irregular point cloud data to a dense grid structure is often associated with a loss of information, due to the discretization and aggregation of points. In this paper, we propose a novel architecture, multi-scale KPPillarsBEV, that aims to mitigate the negative effects of grid rendering. Specifically, we propose a novel grid rendering method, KPBEV, which leverages the descriptive power of kernel point convolutions to improve the encoding of local point cloud contexts during grid rendering. In addition, we propose a general multi-scale grid rendering formulation to incorporate multi-scale feature maps into convolutional backbones of detection networks with arbitrary grid rendering methods. We perform extensive experiments on the nuScenes dataset and evaluate the methods in terms of detection performance and computational complexity. The proposed multi-scale KPPillarsBEV architecture outperforms the baseline by 5.37% and the previous state of the art by 2.88% in Car AP4.0 (average precision for a matching threshold of 4 meters) on the nuScenes validation set. Moreover, the proposed single-scale KPBEV grid rendering improves the Car AP4.0 by 2.90% over the baseline while maintaining the same inference speed.
BASICS: Broad quality Assessment of Static point clouds In Compression Scenarios
Feb 09, 2023



Point clouds are now commonly used to represent 3D scenes in virtual world, in addition to 3D meshes. Their ease of capture enable various applications on mobile devices, such as smartphones or other microcontrollers. Point cloud compression is now at an advanced level and being standardized. Nevertheless, quality assessment databases, which is needed to develop better objective quality metrics, are still limited. In this work, we create a broad quality assessment database for static point clouds, mainly for telepresence scenario. For the sake of completeness, the created database is analyzed using the mean opinion scores, and it is used to benchmark several state-of-the-art quality estimators. The generated database is named Broad quality Assessment of Static point clouds In Compression Scenario (BASICS). Currently, the BASICS database is used as part of the ICIP 2023 Grand Challenge on Point Cloud Quality Assessment, and therefore only a part of the database has been made publicly available at the challenge website. The rest of the database will be made available once the challenge is over.
Lossless Coding of Point Cloud Geometry using a Deep Generative Model
Jul 01, 2021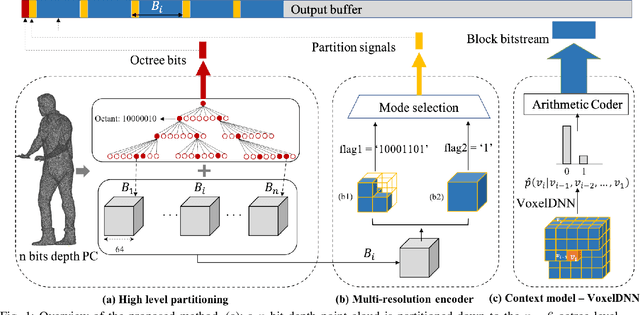

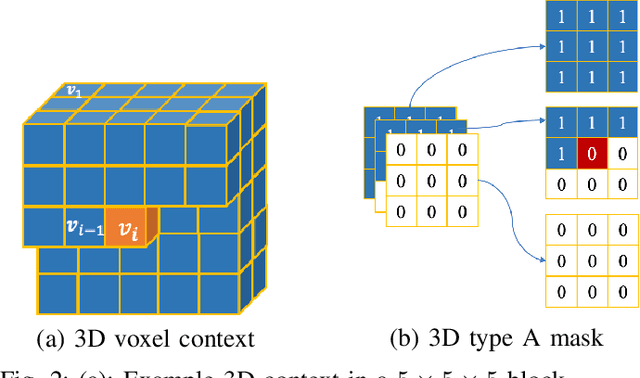
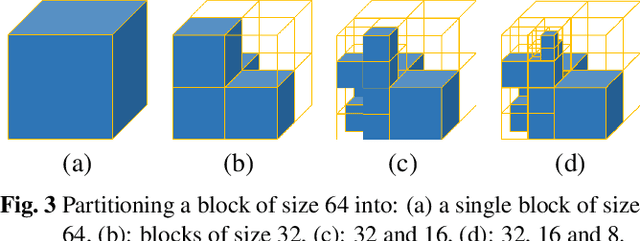
This paper proposes a lossless point cloud (PC) geometry compression method that uses neural networks to estimate the probability distribution of voxel occupancy. First, to take into account the PC sparsity, our method adaptively partitions a point cloud into multiple voxel block sizes. This partitioning is signalled via an octree. Second, we employ a deep auto-regressive generative model to estimate the occupancy probability of each voxel given the previously encoded ones. We then employ the estimated probabilities to code efficiently a block using a context-based arithmetic coder. Our context has variable size and can expand beyond the current block to learn more accurate probabilities. We also consider using data augmentation techniques to increase the generalization capability of the learned probability models, in particular in the presence of noise and lower-density point clouds. Experimental evaluation, performed on a variety of point clouds from four different datasets and with diverse characteristics, demonstrates that our method reduces significantly (by up to 30%) the rate for lossless coding compared to the state-of-the-art MPEG codec.
Multiscale deep context modeling for lossless point cloud geometry compression
Apr 20, 2021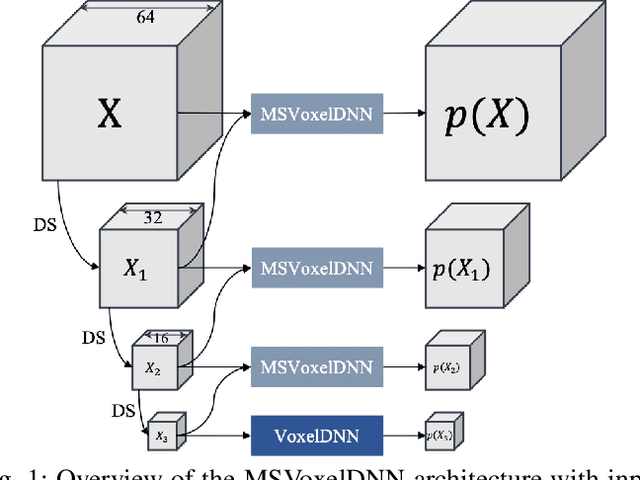
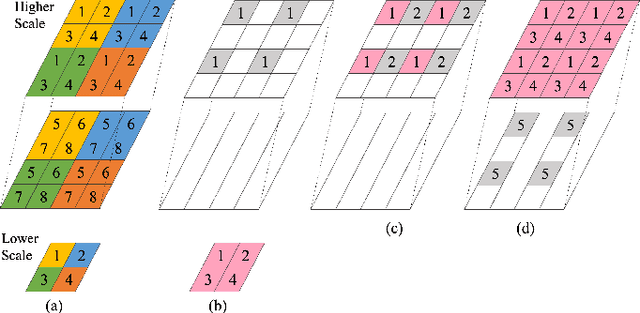
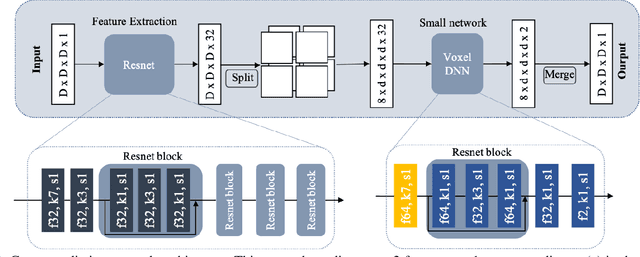
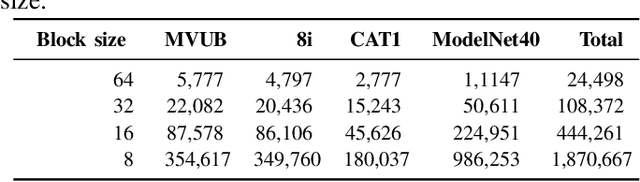
We propose a practical deep generative approach for lossless point cloud geometry compression, called MSVoxelDNN, and show that it significantly reduces the rate compared to the MPEG G-PCC codec. Our previous work based on autoregressive models (VoxelDNN) has a fast training phase, however, inference is slow as the occupancy probabilities are predicted sequentially, voxel by voxel. In this work, we employ a multiscale architecture which models voxel occupancy in coarse-to-fine order. At each scale, MSVoxelDNN divides voxels into eight conditionally independent groups, thus requiring a single network evaluation per group instead of one per voxel. We evaluate the performance of MSVoxelDNN on a set of point clouds from Microsoft Voxelized Upper Bodies (MVUB) and MPEG, showing that the current method speeds up encoding/decoding times significantly compared to the previous VoxelDNN, while having average rate saving over G-PCC of 17.5%. The implementation is available at https://github.com/Weafre/MSVoxelDNN.
A deep perceptual metric for 3D point clouds
Feb 25, 2021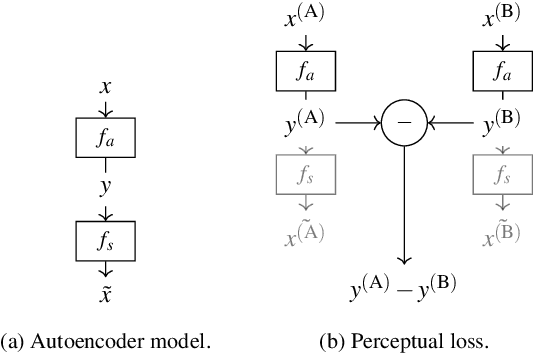

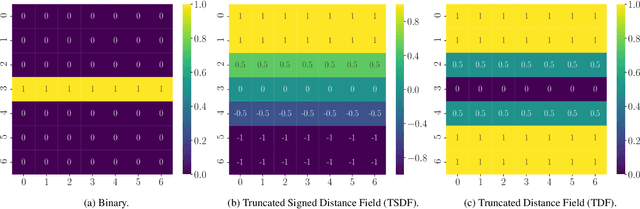
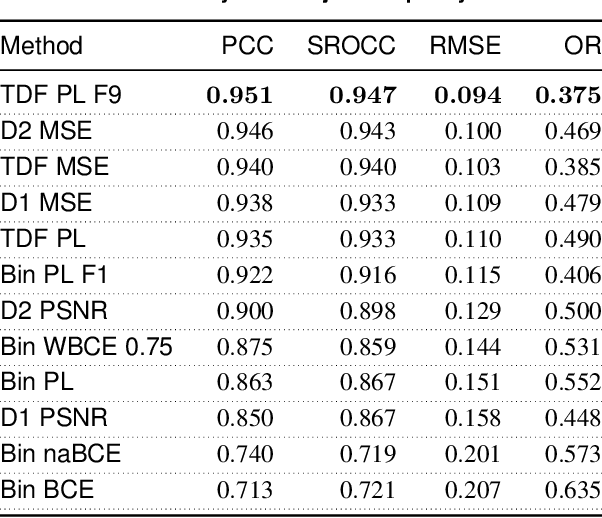
Point clouds are essential for storage and transmission of 3D content. As they can entail significant volumes of data, point cloud compression is crucial for practical usage. Recently, point cloud geometry compression approaches based on deep neural networks have been explored. In this paper, we evaluate the ability to predict perceptual quality of typical voxel-based loss functions employed to train these networks. We find that the commonly used focal loss and weighted binary cross entropy are poorly correlated with human perception. We thus propose a perceptual loss function for 3D point clouds which outperforms existing loss functions on the ICIP2020 subjective dataset. In addition, we propose a novel truncated distance field voxel grid representation and find that it leads to sparser latent spaces and loss functions that are more correlated with perceived visual quality compared to a binary representation. The source code is available at https://github.com/mauriceqch/2021_pc_perceptual_loss.
Learning-based lossless compression of 3D point cloud geometry
Nov 30, 2020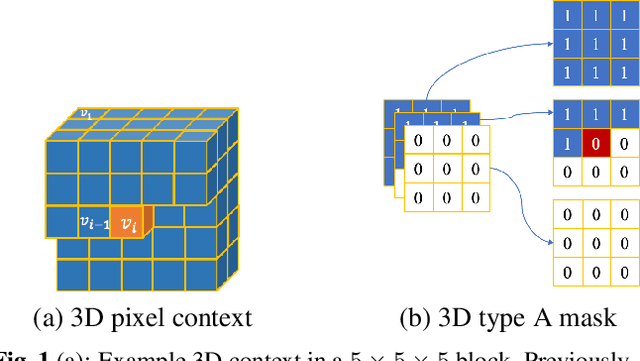
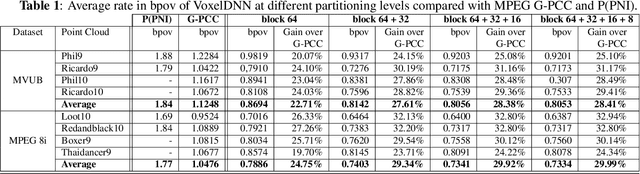
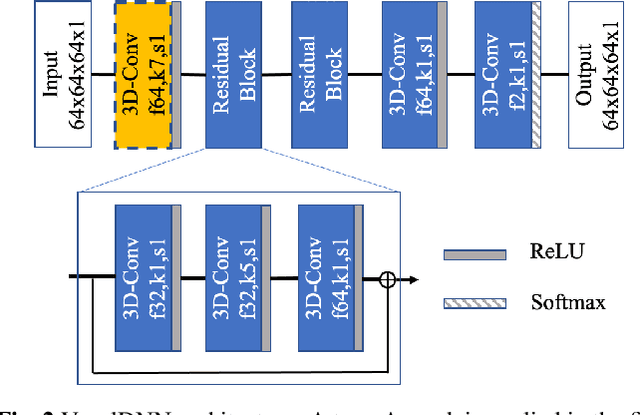
This paper presents a learning-based, lossless compression method for static point cloud geometry, based on context-adaptive arithmetic coding. Unlike most existing methods working in the octree domain, our encoder operates in a hybrid mode, mixing octree and voxel-based coding. We adaptively partition the point cloud into multi-resolution voxel blocks according to the point cloud structure and use octree to signal the partitioning. On the one hand, octree representation can eliminate the sparsity in the point cloud. On the other hand, in the voxel domain, convolutions can be naturally expressed, and geometric information (i.e., planes, surfaces, etc.) is explicitly processed by a neural network. Our context model benefits from these properties and learns a probability distribution of the voxels using a deep convolutional neural network with masked filters, called VoxelDNN. Experiments show that our method outperforms the state-of-the-art MPEG G-PCC standard with average rate savings of 28% on a diverse set of point clouds from the Microsoft Voxelized Upper Bodies (MVUB) and MPEG.
Improved Deep Point Cloud Geometry Compression
Jun 24, 2020

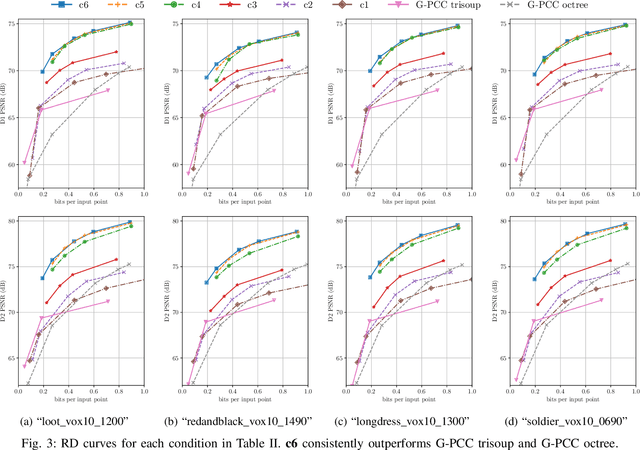

Point clouds have been recognized as a crucial data structure for 3D content and are essential in a number of applications such as virtual and mixed reality, autonomous driving, cultural heritage, etc. In this paper, we propose a set of contributions to improve deep point cloud compression, i.e.: using a scale hyperprior model for entropy coding; employing deeper transforms; a different balancing weight in the focal loss; optimal thresholding for decoding; and sequential model training. In addition, we present an extensive ablation study on the impact of each of these factors, in order to provide a better understanding about why they improve RD performance. An optimal combination of the proposed improvements achieves BD-PSNR gains over G-PCC trisoup and octree of 5.50 (6.48) dB and 6.84 (5.95) dB, respectively, when using the point-to-point (point-to-plane) metric. Code is available at https://github.com/mauriceqch/pcc_geo_cnn_v2 .
Folding-based compression of point cloud attributes
Feb 11, 2020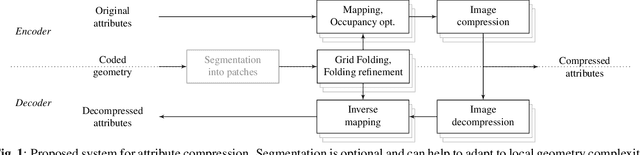

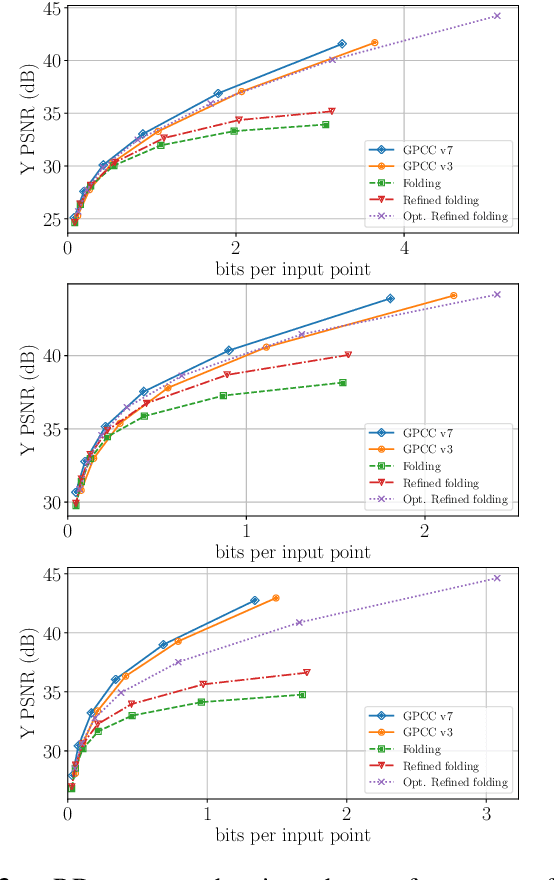
Existing techniques to compress point cloud attributes leverage either geometric or video-based compression tools. In this work, we explore a radically different approach inspired by recent advances in point cloud representation learning. A point cloud can be interpreted as a 2D manifold in a 3D space. As that, its attributes could be mapped onto a folded 2D grid; compressed through a conventional 2D image codec; and mapped back at the decoder side to recover attributes on 3D points. The folding operation is optimized by employing a deep neural network as a parametric folding function. As mapping is lossy in nature, we propose several strategies to refine it in such a way that attributes in 3D can be mapped to the 2D grid with minimal distortion. This approach can be flexibly applied to portions of point clouds in order to better adapt to local geometric complexity, and thus has a potential for being used as a tool in existing or future coding pipelines. Our preliminary results show that the proposed folding-based coding scheme can already reach performance similar to the latest MPEG GPCC codec.
Learning Convolutional Transforms for Lossy Point Cloud Geometry Compression
Mar 20, 2019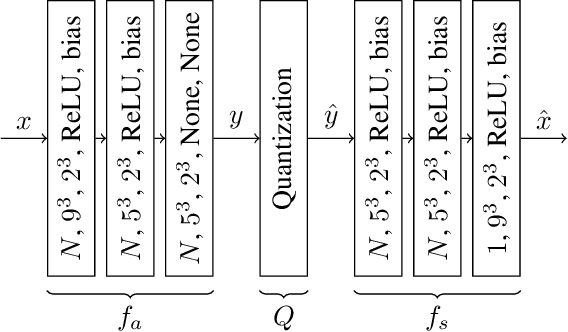



Efficient point cloud compression is fundamental to enable the deployment of virtual and mixed reality applications, since the number of points to code can range in the order of millions. In this paper, we present a novel data-driven geometry compression method for static point clouds based on learned convolutional transforms and uniform quantization. We perform joint optimization of both rate and distortion using a trade-off parameter. In addition, we cast the decoding process as a binary classification of the point cloud occupancy map. Our method outperforms the MPEG reference solution in terms of rate-distortion on the Microsoft Voxelized Upper Bodies dataset with 51.5% BDBR savings on average. Moreover, while octree-based methods face exponential diminution of the number of points at low bitrates, our method still produces high resolution outputs even at low bitrates.