 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Listener: Dyadic Facial Motion Synthesis via Action Diffusion
Apr 29, 2025



Generating realistic listener facial motions in dyadic conversations remains challenging due to the high-dimensional action space and temporal dependency requirements. Existing approaches usually consider extracting 3D Morphable Model (3DMM) coefficients and modeling in the 3DMM space. However, this makes the computational speed of the 3DMM a bottleneck, making it difficult to achieve real-time interactive responses. To tackle this problem, we propose Facial Action Diffusion (FAD), which introduces the diffusion methods from the field of image generation to achieve efficient facial action generation. We further build the Efficient Listener Network (ELNet) specially designed to accommodate both the visual and audio information of the speaker as input. Considering of FAD and ELNet, the proposed method learns effective listener facial motion representations and leads to improvements of performance over the state-of-the-art methods while reducing 99% computational time.
Omni$^2$: Unifying Omnidirectional Image Generation and Editing in an Omni Model
Apr 15, 2025$360^{\circ}$ omnidirectional images (ODIs) have gained considerable attention recently, and are widely used in various virtual reality (VR) and augmented reality (AR) applications. However, capturing such images is expensive and requires specialized equipment, making ODI synthesis increasingly important. While common 2D image generation and editing methods are rapidly advancing, these models struggle to deliver satisfactory results when generating or editing ODIs due to the unique format and broad 360$^{\circ}$ Field-of-View (FoV) of ODIs. To bridge this gap, we construct \textbf{\textit{Any2Omni}}, the first comprehensive ODI generation-editing dataset comprises 60,000+ training data covering diverse input conditions and up to 9 ODI generation and editing tasks. Built upon Any2Omni, we propose an \textbf{\underline{Omni}} model for \textbf{\underline{Omni}}-directional image generation and editing (\textbf{\textit{Omni$^2$}}), with the capability of handling various ODI generation and editing tasks under diverse input conditions using one model. Extensive experiments demonstrate the superiority and effectiveness of the proposed Omni$^2$ model for both the ODI generation and editing tasks.
HarmonyIQA: Pioneering Benchmark and Model for Image Harmonization Quality Assessment
Jan 02, 2025



Image composition involves extracting a foreground object from one image and pasting it into another image through Image harmonization algorithms (IHAs), which aim to adjust the appearance of the foreground object to better match the background. Existing image quality assessment (IQA) methods may fail to align with human visual preference on image harmonization due to the insensitivity to minor color or light inconsistency. To address the issue and facilitate the advancement of IHAs, we introduce the first Image Quality Assessment Database for image Harmony evaluation (HarmonyIQAD), which consists of 1,350 harmonized images generated by 9 different IHAs, and the corresponding human visual preference scores. Based on this database, we propose a Harmony Image Quality Assessment (HarmonyIQA), to predict human visual preference for harmonized images. Extensive experiments show that HarmonyIQA achieves state-of-the-art performance on human visual preference evaluation for harmonized images, and also achieves competing results on traditional IQA tasks. Furthermore, cross-dataset evaluation also shows that HarmonyIQA exhibits better generalization ability than self-supervised learning-based IQA methods. Both HarmonyIQAD and HarmonyIQA will be made publicly available upon paper publication.
ESVQA: Perceptual Quality Assessment of Egocentric Spatial Videos
Dec 29, 2024



With the rapid development of eXtended Reality (XR), egocentric spatial shooting and display technologies have further enhanced immersion and engagement for users. Assessing the quality of experience (QoE) of egocentric spatial videos is crucial to ensure a high-quality viewing experience. However, the corresponding research is still lacking. In this paper, we use the embodied experience to highlight this more immersive experience and study the new problem, i.e., embodied perceptual quality assessment for egocentric spatial videos. Specifically, we introduce the first Egocentric Spatial Video Quality Assessment Database (ESVQAD), which comprises 600 egocentric spatial videos and their mean opinion scores (MOSs). Furthermore, we propose a novel multi-dimensional binocular feature fusion model, termed ESVQAnet, which integrates binocular spatial, motion, and semantic features to predict the perceptual quality. Experimental results demonstrate the ESVQAnet outperforms 16 state-of-the-art VQA models on the embodied perceptual quality assessment task, and exhibits strong generalization capability on traditional VQA tasks. The database and codes will be released upon the publication.
ESIQA: Perceptual Quality Assessment of Vision-Pro-based Egocentric Spatial Images
Jul 31, 2024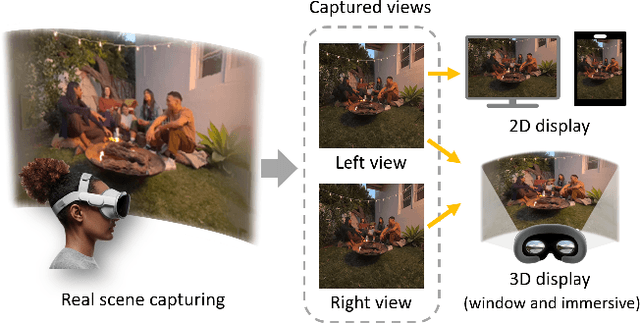



With the development of eXtended Reality (XR), head-mounted shooting and display technology have experienced significant advancement and gained considerable attention. Egocentric spatial images and videos are emerging as a compelling form of stereoscopic XR content. Different from traditional 2D images, egocentric spatial images present challenges for perceptual quality assessment due to their special shooting, processing methods, and stereoscopic characteristics. However, the corresponding image quality assessment (IQA) research for egocentric spatial images is still lacking. In this paper, we establish the Egocentric Spatial Images Quality Assessment Database (ESIQAD), the first IQA database dedicated for egocentric spatial images as far as we know. Our ESIQAD includes 500 egocentric spatial images, containing 400 images captured with the Apple Vision Pro and 100 images generated via an iPhone's "Spatial Camera" app. The corresponding mean opinion scores (MOSs) are collected under three viewing modes, including 2D display, 3D-window display, and 3D-immersive display. Furthermore, based on our database, we conduct a benchmark experiment and evaluate the performance of 22 state-of-the-art IQA models under three different viewing modes. We hope this research can facilitate future IQA research on egocentric spatial images. The database is available at https://github.com/IntMeGroup/ESIQA.
AIGCOIQA2024: Perceptual Quality Assessment of AI Generated Omnidirectional Images
Apr 01, 2024
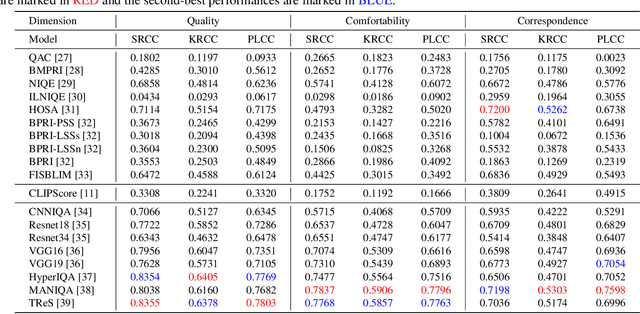


In recent years, the rapid advancement of Artificial Intelligence Generated Content (AIGC) has attracted widespread attention. Among the AIGC, AI generated omnidirectional images hold significant potential for Virtual Reality (VR) and Augmented Reality (AR) applications, hence omnidirectional AIGC techniques have also been widely studied. AI-generated omnidirectional images exhibit unique distortions compared to natural omnidirectional images, however, there is no dedicated Image Quality Assessment (IQA) criteria for assessing them. This study addresses this gap by establishing a large-scale AI generated omnidirectional image IQA database named AIGCOIQA2024 and constructing a comprehensive benchmark. We first generate 300 omnidirectional images based on 5 AIGC models utilizing 25 text prompts. A subjective IQA experiment is conducted subsequently to assess human visual preferences from three perspectives including quality, comfortability, and correspondence. Finally, we conduct a benchmark experiment to evaluate the performance of state-of-the-art IQA models on our database. The database will be released to facilitate future research.
LLM-based Interaction for Content Generation: A Case Study on the Perception of Employees in an IT department
Apr 18, 2023



In the past years, AI has seen many advances in the field of NLP. This has led to the emergence of LLMs, such as the now famous GPT-3.5, which revolutionise the way humans can access or generate content. Current studies on LLM-based generative tools are mainly interested in the performance of such tools in generating relevant content (code, text or image). However, ethical concerns related to the design and use of generative tools seem to be growing, impacting the public acceptability for specific tasks. This paper presents a questionnaire survey to identify the intention to use generative tools by employees of an IT company in the context of their work. This survey is based on empirical models measuring intention to use (TAM by Davis, 1989, and UTAUT2 by Venkatesh and al., 2008). Our results indicate a rather average acceptability of generative tools, although the more useful the tool is perceived to be, the higher the intention to use seems to be. Furthermore, our analyses suggest that the frequency of use of generative tools is likely to be a key factor in understanding how employees perceive these tools in the context of their work. Following on from this work, we plan to investigate the nature of the requests that may be made to these tools by specific audiences.
BASICS: Broad quality Assessment of Static point clouds In Compression Scenarios
Feb 09, 2023



Point clouds are now commonly used to represent 3D scenes in virtual world, in addition to 3D meshes. Their ease of capture enable various applications on mobile devices, such as smartphones or other microcontrollers. Point cloud compression is now at an advanced level and being standardized. Nevertheless, quality assessment databases, which is needed to develop better objective quality metrics, are still limited. In this work, we create a broad quality assessment database for static point clouds, mainly for telepresence scenario. For the sake of completeness, the created database is analyzed using the mean opinion scores, and it is used to benchmark several state-of-the-art quality estimators. The generated database is named Broad quality Assessment of Static point clouds In Compression Scenario (BASICS). Currently, the BASICS database is used as part of the ICIP 2023 Grand Challenge on Point Cloud Quality Assessment, and therefore only a part of the database has been made publicly available at the challenge website. The rest of the database will be made available once the challenge is over.
On the benefit of parameter-driven approaches for the modeling and the prediction of Satisfied User Ratio for compressed video
Jun 20, 2022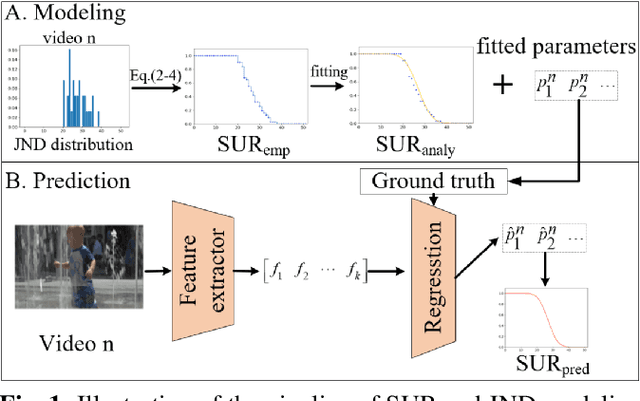

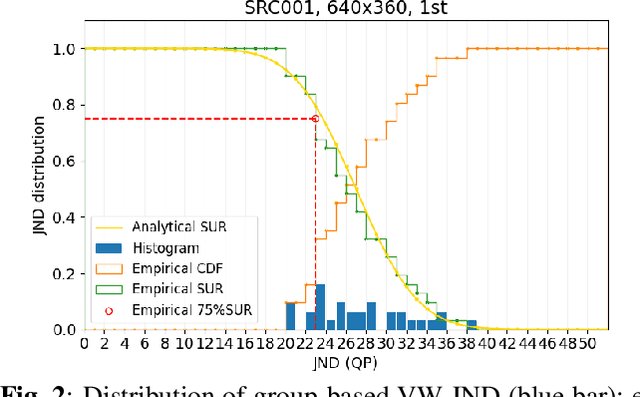
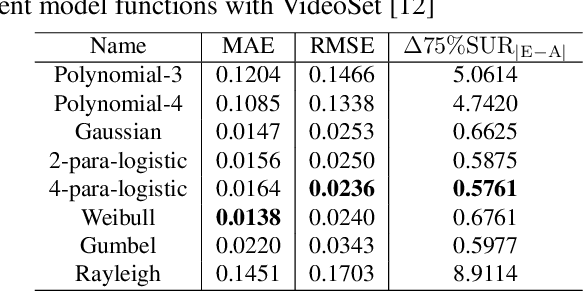
The human eye cannot perceive small pixel changes in images or videos until a certain threshold of distortion. In the context of video compression, Just Noticeable Difference (JND) is the smallest distortion level from which the human eye can perceive the difference between reference video and the distorted/compressed one. Satisfied-User-Ratio (SUR) curve is the complementary cumulative distribution function of the individual JNDs of a viewer group. However, most of the previous works predict each point in SUR curve by using features both from source video and from compressed videos with assumption that the group-based JND annotations follow Gaussian distribution, which is neither practical nor accurate. In this work, we firstly compared various common functions for SUR curve modeling. Afterwards, we proposed a novel parameter-driven method to predict the video-wise SUR from video features. Besides, we compared the prediction results of source-only features based (SRC-based) models and source plus compressed videos features (SRC+PVS-based) models.
A Framework to Map VMAF with the Probability of Just Noticeable Difference between Video Encoding Recipes
May 20, 2022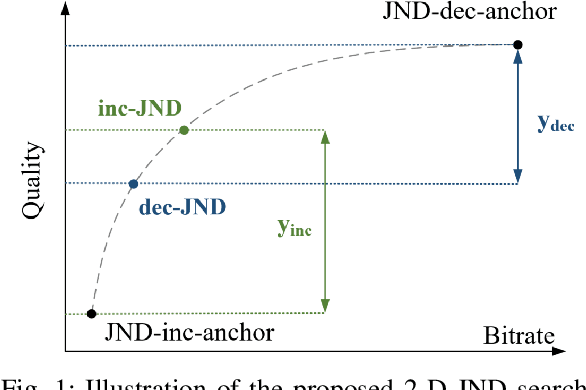
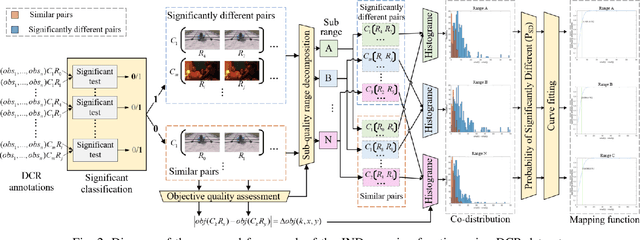
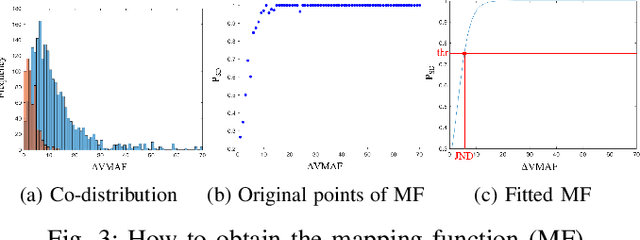
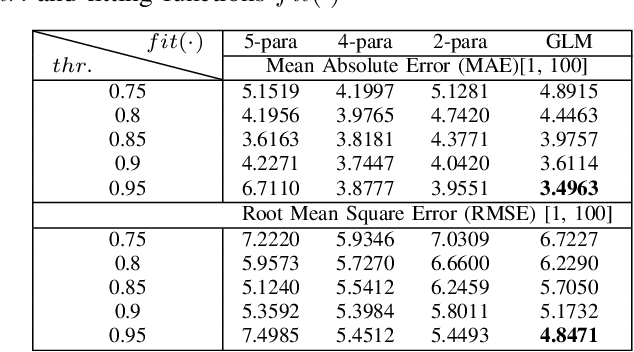
Just Noticeable Difference (JND) model developed based on Human Vision System (HVS) through subjective studies is valuable for many multimedia use cases. In the streaming industries, it is commonly applied to reach a good balance between compression efficiency and perceptual quality when selecting video encoding recipes. Nevertheless, recent state-of-the-art deep learning based JND prediction model relies on large-scale JND ground truth that is expensive and time consuming to collect. Most of the existing JND datasets contain limited number of contents and are limited to a certain codec (e.g., H264). As a result, JND prediction models that were trained on such datasets are normally not agnostic to the codecs. To this end, in order to decouple encoding recipes and JND estimation, we propose a novel framework to map the difference of objective Video Quality Assessment (VQA) scores, i.e., VMAF, between two given videos encoded with different encoding recipes from the same content to the probability of having just noticeable difference between them. The proposed probability mapping model learns from DCR test data, which is significantly cheaper compared to standard JND subjective test. As we utilize objective VQA metric (e.g., VMAF that trained with contents encoded with different codecs) as proxy to estimate JND, our model is agnostic to codecs and computationally efficient. Throughout extensive experiments, it is demonstrated that the proposed model is able to estimate JND values efficiently.