 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFDS: Frequency-Aware Denoising Score for Text-Guided Latent Diffusion Image Editing
Mar 24, 2025



Text-guided image editing using Text-to-Image (T2I) models often fails to yield satisfactory results, frequently introducing unintended modifications, such as the loss of local detail and color changes. In this paper, we analyze these failure cases and attribute them to the indiscriminate optimization across all frequency bands, even though only specific frequencies may require adjustment. To address this, we introduce a simple yet effective approach that enables the selective optimization of specific frequency bands within localized spatial regions for precise edits. Our method leverages wavelets to decompose images into different spatial resolutions across multiple frequency bands, enabling precise modifications at various levels of detail. To extend the applicability of our approach, we provide a comparative analysis of different frequency-domain techniques. Additionally, we extend our method to 3D texture editing by performing frequency decomposition on the triplane representation, enabling frequency-aware adjustments for 3D textures. Quantitative evaluations and user studies demonstrate the effectiveness of our method in producing high-quality and precise edits.
Perceptual Evaluation on Audio-visual Dataset of 360 Content
May 16, 2022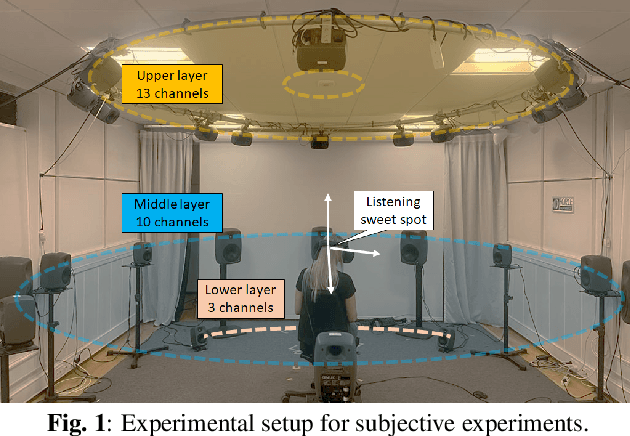
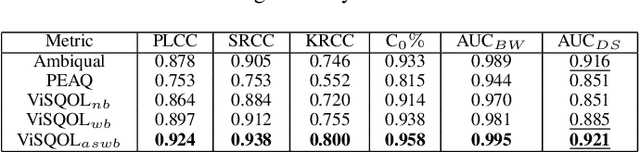

To open up new possibilities to assess the multimodal perceptual quality of omnidirectional media formats, we proposed a novel open source 360 audiovisual (AV) quality dataset. The dataset consists of high-quality 360 video clips in equirectangular (ERP) format and higher-order ambisonic (4th order) along with the subjective scores. Three subjective quality experiments were conducted for audio, video, and AV with the procedures detailed in this paper. Using the data from subjective tests, we demonstrated that this dataset can be used to quantify perceived audio, video, and audiovisual quality. The diversity and discriminability of subjective scores were also analyzed. Finally, we investigated how our dataset correlates with various objective quality metrics of audio and video. Evidence from the results of this study implies that the proposed dataset can benefit future studies on multimodal quality evaluation of 360 content.
Capacity and Achievable Rates of Fading Few-mode MIMO IM/DD Optical Fiber Channels
Jan 27, 2022
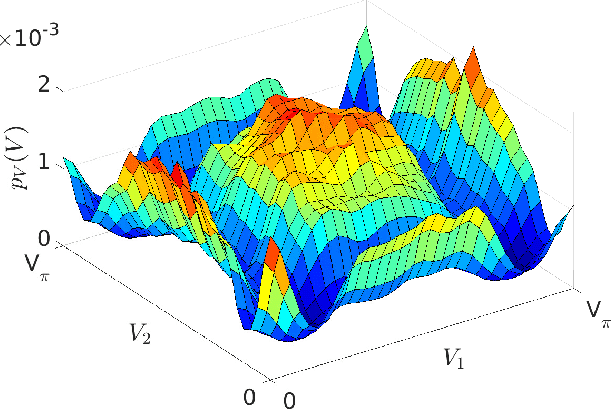

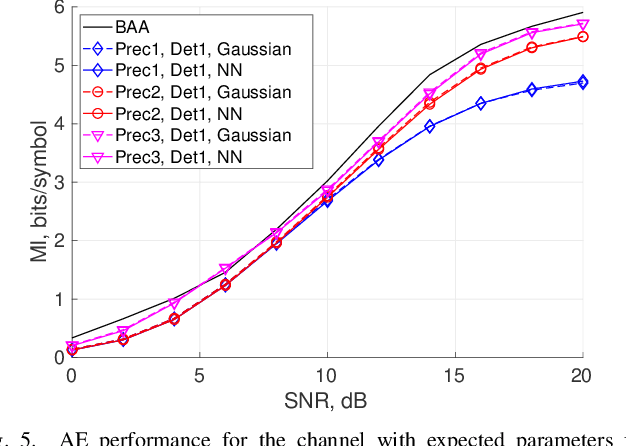
The optical fiber multiple-input multiple-output (MIMO) channel with intensity modulation and direct detection (IM/DD) per spatial path is treated. The spatial dimensions represent the multiple modes employed for transmission and the cross-talk between them originates in the multiplexers and demultiplexers, which are polarization dependent and thus timevarying. The upper bounds from free-space IM/DD MIMO channels are adapted to the fiber case, and the constellation constrained capacity is constructively estimated using the Blahut-Arimoto algorithm. An autoencoder is then proposed to optimize a practical MIMO transmission in terms of pre-coder and detector assuming channel distribution knowledge at the transmitter. The pre-coders are shown to be robust to changes in the channel.
Deep Decoding of $\ell_\infty$-coded Light Field Images
Jan 24, 2022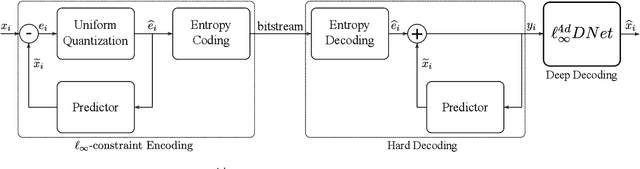
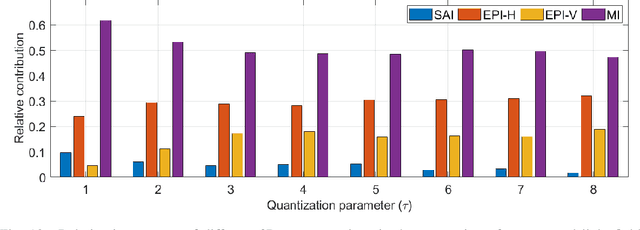
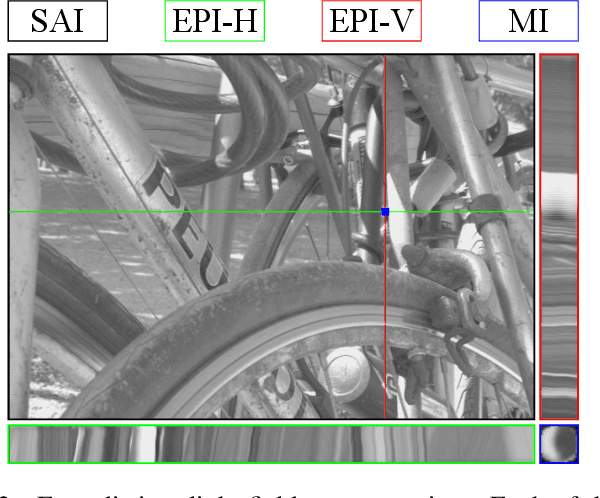
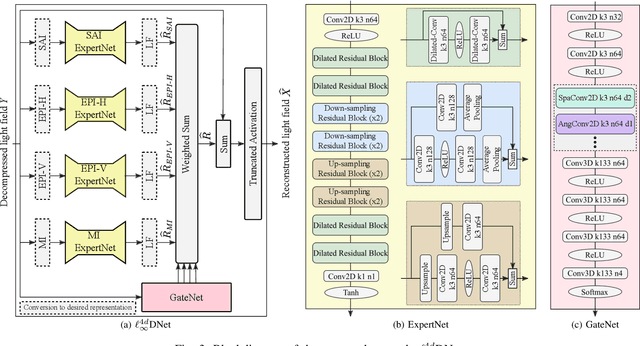
To enrich the functionalities of traditional cameras, light field cameras record both the intensity and direction of light rays, so that images can be rendered with user-defined camera parameters via computations. The added capability and flexibility are gained at the cost of gathering typically more than $100\times$ greater amount of information than conventional images. To cope with this issue, several light field compression schemes have been introduced. However, their ways of exploiting correlations of multidimensional light field data are complex and are hence not suited for inexpensive light field cameras. In this work, we propose a novel $\ell_\infty$-constrained light-field image compression system that has a very low-complexity DPCM encoder and a CNN-based deep decoder. Targeting high-fidelity reconstruction, the CNN decoder capitalizes on the $\ell_\infty$-constraint and light field properties to remove the compression artifacts and achieves significantly better performance than existing state-of-the-art $\ell_2$-based light field compression methods.
Perceptual Evaluation of 360 Audiovisual Quality and Machine Learning Predictions
Dec 22, 2021

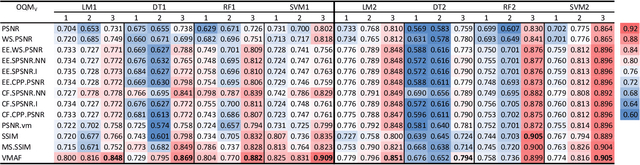
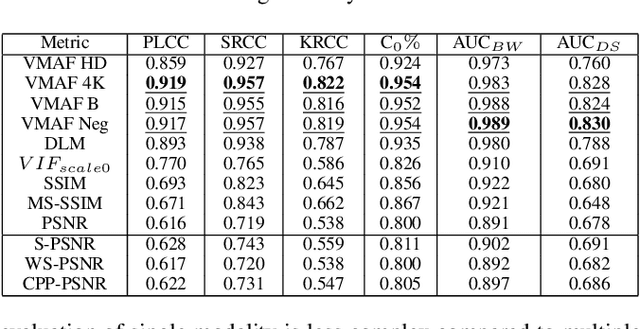
In an earlier study, we gathered perceptual evaluations of the audio, video, and audiovisual quality for 360 audiovisual content. This paper investigates perceived audiovisual quality prediction based on objective quality metrics and subjective scores of 360 video and spatial audio content. Thirteen objective video quality metrics and three objective audio quality metrics were evaluated for five stimuli for each coding parameter. Four regression-based machine learning models were trained and tested here, i.e., multiple linear regression, decision tree, random forest, and support vector machine. Each model was constructed using a combination of audio and video quality metrics and two cross-validation methods (k-Fold and Leave-One-Out) were investigated and produced 312 predictive models. The results indicate that the model based on the evaluation of VMAF and AMBIQUAL is better than other combinations of audio-video quality metric. In this study, support vector machine provides higher performance using k-Fold (PCC = 0.909, SROCC = 0.914, and RMSE = 0.416). These results can provide insights for the design of multimedia quality metrics and the development of predictive models for audiovisual omnidirectional media.
All-Optical Nonlinear Pre-Compensation of Long-Reach Unrepeatered Systems
Jan 06, 2021
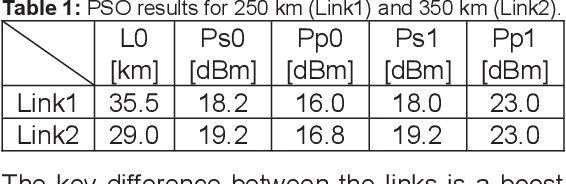
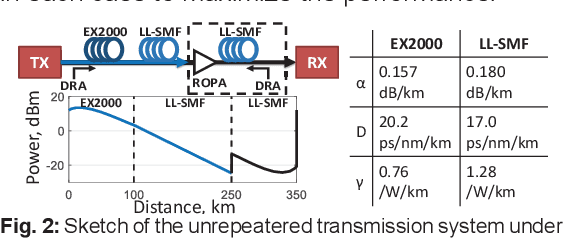

We numerically demonstrate an all-optical nonlinearity pre-compensation module for state-of-the-art long-reach Raman-amplified unrepeatered links. The compensator design is optimized in terms of propagation symmetry to maximize the performance gains under WDM transmission, achieving 4.0dB and 2.6dB of SNR improvement for 250-km and 350-km links.
Online Decomposition of Compressive Streaming Data Using $n$-$\ell_1$ Cluster-Weighted Minimization
Feb 08, 2018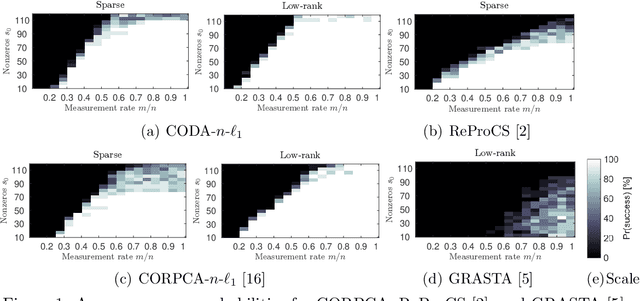

We consider a decomposition method for compressive streaming data in the context of online compressive Robust Principle Component Analysis (RPCA). The proposed decomposition solves an $n$-$\ell_1$ cluster-weighted minimization to decompose a sequence of frames (or vectors), into sparse and low-rank components, from compressive measurements. Our method processes a data vector of the stream per time instance from a small number of measurements in contrast to conventional batch RPCA, which needs to access full data. The $n$-$\ell_1$ cluster-weighted minimization leverages the sparse components along with their correlations with multiple previously-recovered sparse vectors. Moreover, the proposed minimization can exploit the structures of sparse components via clustering and re-weighting iteratively. The method outperforms the existing methods for both numerical data and actual video data.
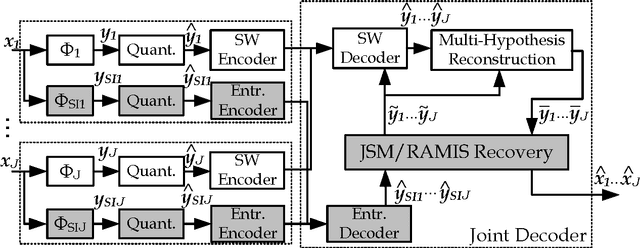
Distributed Coding of Multiview Sparse Sources with Joint Recovery
Jul 18, 2016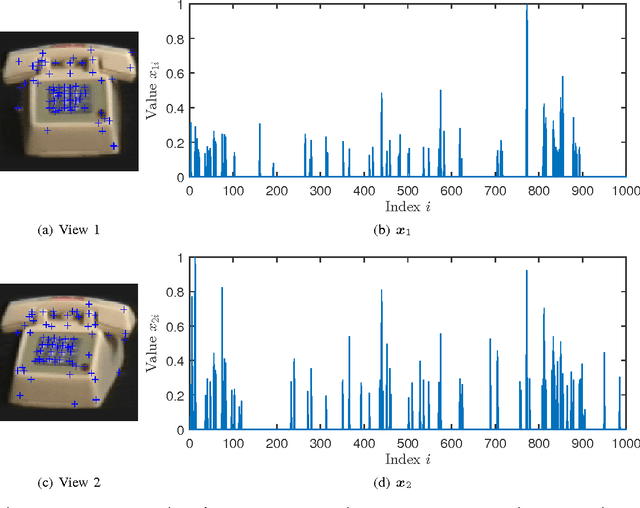
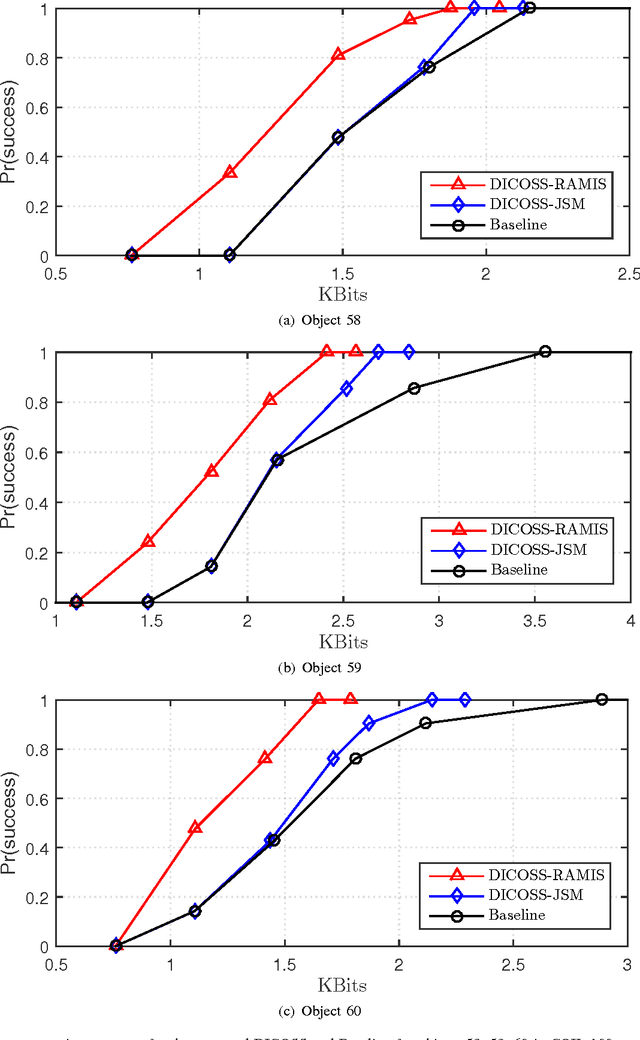
In support of applications involving multiview sources in distributed object recognition using lightweight cameras, we propose a new method for the distributed coding of sparse sources as visual descriptor histograms extracted from multiview images. The problem is challenging due to the computational and energy constraints at each camera as well as the limitations regarding inter-camera communication. Our approach addresses these challenges by exploiting the sparsity of the visual descriptor histograms as well as their intra- and inter-camera correlations. Our method couples distributed source coding of the sparse sources with a new joint recovery algorithm that incorporates multiple side information signals, where prior knowledge (low quality) of all the sparse sources is initially sent to exploit their correlations. Experimental evaluation using the histograms of shift-invariant feature transform (SIFT) descriptors extracted from multiview images shows that our method leads to bit-rate saving of up to 43% compared to the state-of-the-art distributed compressed sensing method with independent encoding of the sources.
Sparse Signal Reconstruction with Multiple Side Information using Adaptive Weights for Multiview Sources
May 22, 2016
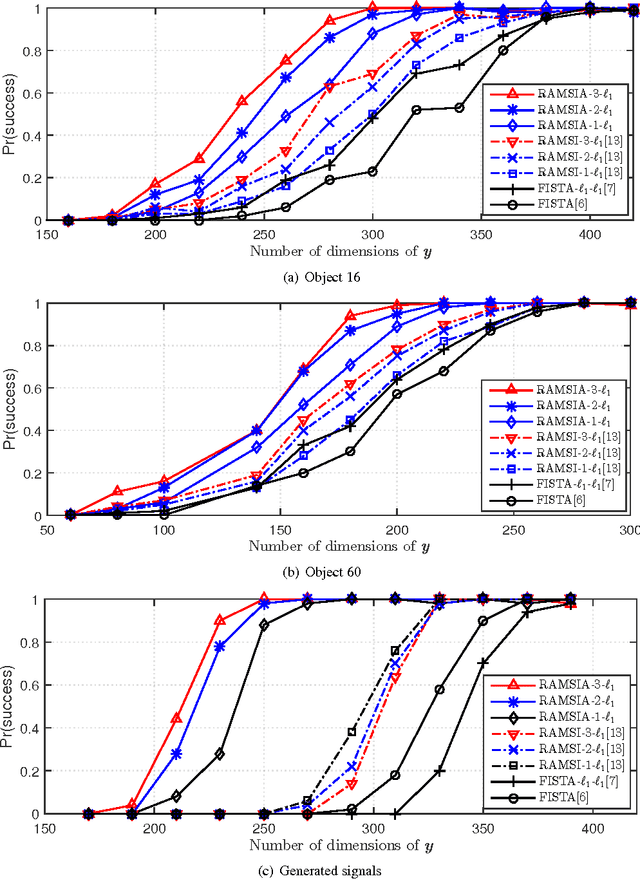
This work considers reconstructing a target signal in a context of distributed sparse sources. We propose an efficient reconstruction algorithm with the aid of other given sources as multiple side information (SI). The proposed algorithm takes advantage of compressive sensing (CS) with SI and adaptive weights by solving a proposed weighted $n$-$\ell_{1}$ minimization. The proposed algorithm computes the adaptive weights in two levels, first each individual intra-SI and then inter-SI weights are iteratively updated at every reconstructed iteration. This two-level optimization leads the proposed reconstruction algorithm with multiple SI using adaptive weights (RAMSIA) to robustly exploit the multiple SIs with different qualities. We experimentally perform our algorithm on generated sparse signals and also correlated feature histograms as multiview sparse sources from a multiview image database. The results show that RAMSIA significantly outperforms both classical CS and CS with single SI, and RAMSIA with higher number of SIs gained more than the one with smaller number of SIs.