 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGATA2Floor: Graph attention for floor counting in street-view facades
May 12, 2026Automated analysis of building facades from street-level imagery has great potential for urban analytics, energy assessment, and emergency planning. However, it requires reasoning over spatially arranged elements rather than solely isolated detections. In this work, we model each facade as a graph over window/door detections with a vertical prior on edges. Additionally, we introduce GATA2Floor, a multi-head Graph Attention v2 (GATv2) based model that predicts the global floor count of a building and, via learnable cross-attention queries, softly assigns elements to latent floor slots, yielding interpretable outputs and robustness to irregular designs. To mitigate the lack of labeled datasets, we demonstrate that the proposed graph-based reasoning can be applied without annotations by leveraging a lightweight label-free proposal mechanism based on self-supervised features and vision-language scoring. Our approach demonstrates the value of graph-attention-based relational reasoning for facade understanding.
When Negation Is a Geometry Problem in Vision-Language Models
Mar 20, 2026Joint Vision-Language Embedding models such as CLIP typically fail at understanding negation in text queries - for example, failing to distinguish "no" in the query: "a plain blue shirt with no logos". Prior work has largely addressed this limitation through data-centric approaches, fine-tuning CLIP on large-scale synthetic negation datasets. However, these efforts are commonly evaluated using retrieval-based metrics that cannot reliably reflect whether negation is actually understood. In this paper, we identify two key limitations of such evaluation metrics and investigate an alternative evaluation framework based on Multimodal LLMs-as-a-judge, which typically excel at understanding simple yes/no questions about image content, providing a fair evaluation of negation understanding in CLIP models. We then ask whether there already exists a direction in the CLIP embedding space associated with negation. We find evidence that such a direction exists, and show that it can be manipulated through test-time intervention via representation engineering to steer CLIP toward negation-aware behavior without any fine-tuning. Finally, we test negation understanding on non-common image-text samples to evaluate generalization under distribution shifts.
FUTON: Fourier Tensor Network for Implicit Neural Representations
Feb 13, 2026Implicit neural representations (INRs) have emerged as powerful tools for encoding signals, yet dominant MLP-based designs often suffer from slow convergence, overfitting to noise, and poor extrapolation. We introduce FUTON (Fourier Tensor Network), which models signals as generalized Fourier series whose coefficients are parameterized by a low-rank tensor decomposition. FUTON implicitly expresses signals as weighted combinations of orthonormal, separable basis functions, combining complementary inductive biases: Fourier bases capture smoothness and periodicity, while the low-rank parameterization enforces low-dimensional spectral structure. We provide theoretical guarantees through a universal approximation theorem and derive an inference algorithm with complexity linear in the spectral resolution and the input dimension. On image and volume representation, FUTON consistently outperforms state-of-the-art MLP-based INRs while training 2--5$\times$ faster. On inverse problems such as image denoising and super-resolution, FUTON generalizes better and converges faster.
Temporal Concept Dynamics in Diffusion Models via Prompt-Conditioned Interventions
Dec 09, 2025Diffusion models are usually evaluated by their final outputs, gradually denoising random noise into meaningful images. Yet, generation unfolds along a trajectory, and analyzing this dynamic process is crucial for understanding how controllable, reliable, and predictable these models are in terms of their success/failure modes. In this work, we ask the question: when does noise turn into a specific concept (e.g., age) and lock in the denoising trajectory? We propose PCI (Prompt-Conditioned Intervention) to study this question. PCI is a training-free and model-agnostic framework for analyzing concept dynamics through diffusion time. The central idea is the analysis of Concept Insertion Success (CIS), defined as the probability that a concept inserted at a given timestep is preserved and reflected in the final image, offering a way to characterize the temporal dynamics of concept formation. Applied to several state-of-the-art text-to-image diffusion models and a broad taxonomy of concepts, PCI reveals diverse temporal behaviors across diffusion models, in which certain phases of the trajectory are more favorable to specific concepts even within the same concept type. These findings also provide actionable insights for text-driven image editing, highlighting when interventions are most effective without requiring access to model internals or training, and yielding quantitatively stronger edits that achieve a balance of semantic accuracy and content preservation than strong baselines. Code is available at: https://github.com/adagorgun/PCI-Prompt-Controlled-Interventions
Scalable Context-Preserving Model-Aware Deep Clustering for Hyperspectral Images
Jun 12, 2025Subspace clustering has become widely adopted for the unsupervised analysis of hyperspectral images (HSIs). Recent model-aware deep subspace clustering methods often use a two-stage framework, involving the calculation of a self-representation matrix with complexity of O(n^2), followed by spectral clustering. However, these methods are computationally intensive, generally incorporating solely either local or non-local spatial structure constraints, and their structural constraints fall short of effectively supervising the entire clustering process. We propose a scalable, context-preserving deep clustering method based on basis representation, which jointly captures local and non-local structures for efficient HSI clustering. To preserve local structure (i.e., spatial continuity within subspaces), we introduce a spatial smoothness constraint that aligns clustering predictions with their spatially filtered versions. For non-local structure (i.e., spectral continuity), we employ a mini-cluster-based scheme that refines predictions at the group level, encouraging spectrally similar pixels to belong to the same subspace. Notably, these two constraints are jointly optimized to reinforce each other. Specifically, our model is designed as an one-stage approach in which the structural constraints are applied to the entire clustering process. The time and space complexity of our method is O(n), making it applicable to large-scale HSI data. Experiments on real-world datasets show that our method outperforms state-of-the-art techniques. Our code is available at: https://github.com/lxlscut/SCDSC
ReferGPT: Towards Zero-Shot Referring Multi-Object Tracking
Apr 12, 2025Tracking multiple objects based on textual queries is a challenging task that requires linking language understanding with object association across frames. Previous works typically train the whole process end-to-end or integrate an additional referring text module into a multi-object tracker, but they both require supervised training and potentially struggle with generalization to open-set queries. In this work, we introduce ReferGPT, a novel zero-shot referring multi-object tracking framework. We provide a multi-modal large language model (MLLM) with spatial knowledge enabling it to generate 3D-aware captions. This enhances its descriptive capabilities and supports a more flexible referring vocabulary without training. We also propose a robust query-matching strategy, leveraging CLIP-based semantic encoding and fuzzy matching to associate MLLM generated captions with user queries. Extensive experiments on Refer-KITTI, Refer-KITTIv2 and Refer-KITTI+ demonstrate that ReferGPT achieves competitive performance against trained methods, showcasing its robustness and zero-shot capabilities in autonomous driving. The codes are available on https://github.com/Tzoulio/ReferGPT
Unlocking Open-Set Language Accessibility in Vision Models
Mar 14, 2025



Visual classifiers offer high-dimensional feature representations that are challenging to interpret and analyze. Text, in contrast, provides a more expressive and human-friendly interpretable medium for understanding and analyzing model behavior. We propose a simple, yet powerful method for reformulating any visual classifier so that it can be accessed with open-set text queries without compromising its original performance. Our approach is label-free, efficient, and preserves the underlying classifier's distribution and reasoning processes. We thus unlock several text-based interpretability applications for any classifier. We apply our method on 40 visual classifiers and demonstrate two primary applications: 1) building both label-free and zero-shot concept bottleneck models and therefore converting any classifier to be inherently-interpretable and 2) zero-shot decoding of visual features into natural language. In both applications, we achieve state-of-the-art results, greatly outperforming existing works. Our method enables text approaches for interpreting visual classifiers.
Interpreting and Analyzing CLIP's Zero-Shot Image Classification via Mutual Knowledge
Oct 16, 2024Contrastive Language-Image Pretraining (CLIP) performs zero-shot image classification by mapping images and textual class representation into a shared embedding space, then retrieving the class closest to the image. This work provides a new approach for interpreting CLIP models for image classification from the lens of mutual knowledge between the two modalities. Specifically, we ask: what concepts do both vision and language CLIP encoders learn in common that influence the joint embedding space, causing points to be closer or further apart? We answer this question via an approach of textual concept-based explanations, showing their effectiveness, and perform an analysis encompassing a pool of 13 CLIP models varying in architecture, size and pretraining datasets. We explore those different aspects in relation to mutual knowledge, and analyze zero-shot predictions. Our approach demonstrates an effective and human-friendly way of understanding zero-shot classification decisions with CLIP.
Learned layered coding for Successive Refinement in the Wyner-Ziv Problem
Nov 06, 2023We propose a data-driven approach to explicitly learn the progressive encoding of a continuous source, which is successively decoded with increasing levels of quality and with the aid of correlated side information. This setup refers to the successive refinement of the Wyner-Ziv coding problem. Assuming ideal Slepian-Wolf coding, our approach employs recurrent neural networks (RNNs) to learn layered encoders and decoders for the quadratic Gaussian case. The models are trained by minimizing a variational bound on the rate-distortion function of the successively refined Wyner-Ziv coding problem. We demonstrate that RNNs can explicitly retrieve layered binning solutions akin to scalable nested quantization. Moreover, the rate-distortion performance of the scheme is on par with the corresponding monolithic Wyner-Ziv coding approach and is close to the rate-distortion bound.
Holistic Representation Learning for Multitask Trajectory Anomaly Detection
Nov 03, 2023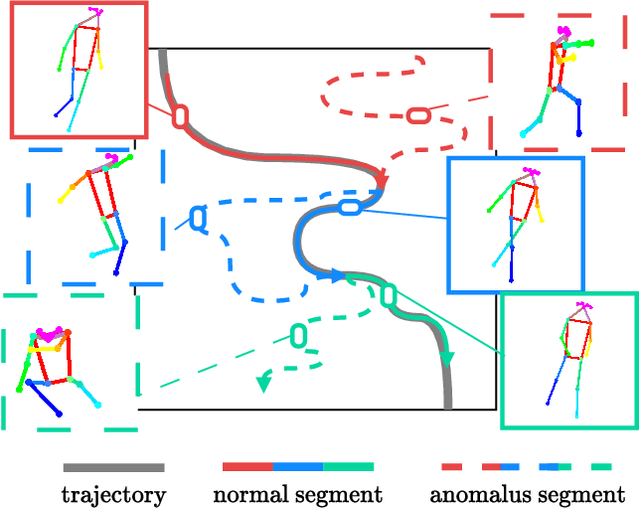

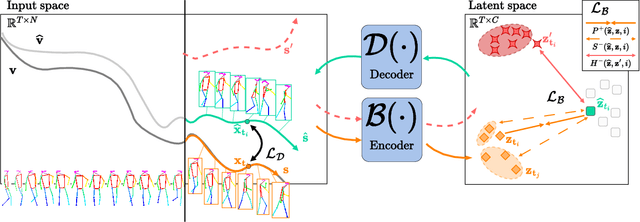
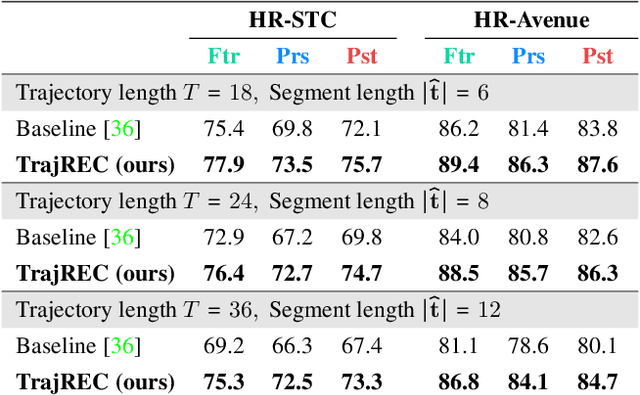
Video anomaly detection deals with the recognition of abnormal events in videos. Apart from the visual signal, video anomaly detection has also been addressed with the use of skeleton sequences. We propose a holistic representation of skeleton trajectories to learn expected motions across segments at different times. Our approach uses multitask learning to reconstruct any continuous unobserved temporal segment of the trajectory allowing the extrapolation of past or future segments and the interpolation of in-between segments. We use an end-to-end attention-based encoder-decoder. We encode temporally occluded trajectories, jointly learn latent representations of the occluded segments, and reconstruct trajectories based on expected motions across different temporal segments. Extensive experiments on three trajectory-based video anomaly detection datasets show the advantages and effectiveness of our approach with state-of-the-art results on anomaly detection in skeleton trajectories.