 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEntropy-Based Feature Extraction For Real-Time Semantic Segmentation
Jul 07, 2022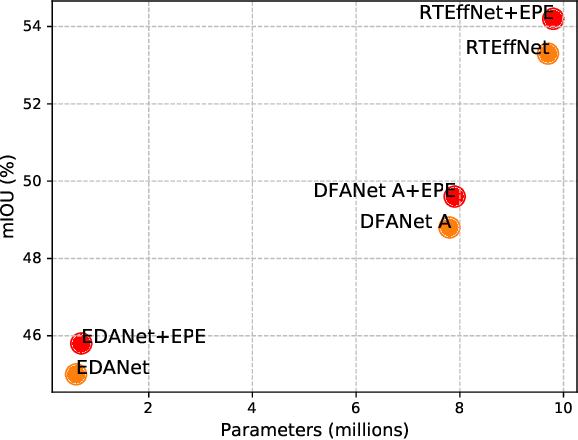
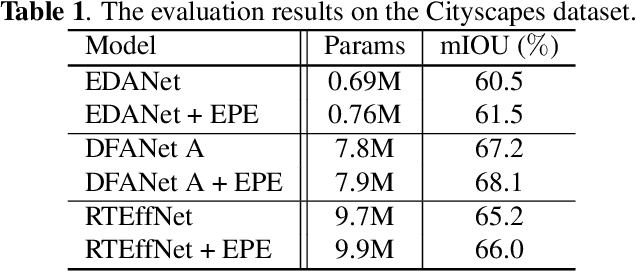
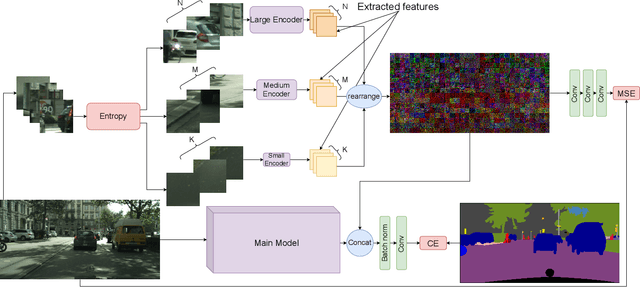

This paper introduces an efficient patch-based computational module, coined Entropy-based Patch Encoder (EPE) module, for resource-constrained semantic segmentation. The EPE module consists of three lightweight fully-convolutional encoders, each extracting features from image patches with a different amount of entropy. Patches with high entropy are being processed by the encoder with the largest number of parameters, patches with moderate entropy are processed by the encoder with a moderate number of parameters, and patches with low entropy are processed by the smallest encoder. The intuition behind the module is the following: as patches with high entropy contain more information, they need an encoder with more parameters, unlike low entropy patches, which can be processed using a small encoder. Consequently, processing part of the patches via the smaller encoder can significantly reduce the computational cost of the module. Experiments show that EPE can boost the performance of existing real-time semantic segmentation models with a slight increase in the computational cost. Specifically, EPE increases the mIOU performance of DFANet A by 0.9% with only 1.2% increase in the number of parameters and the mIOU performance of EDANet by 1% with 10% increase of the model parameters.
Gradient Variance Loss for Structure-Enhanced Image Super-Resolution
Feb 02, 2022
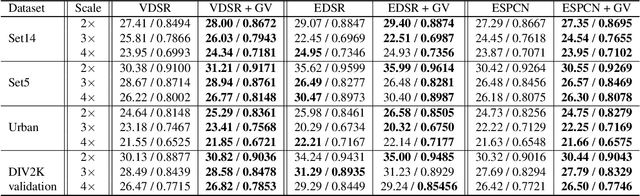
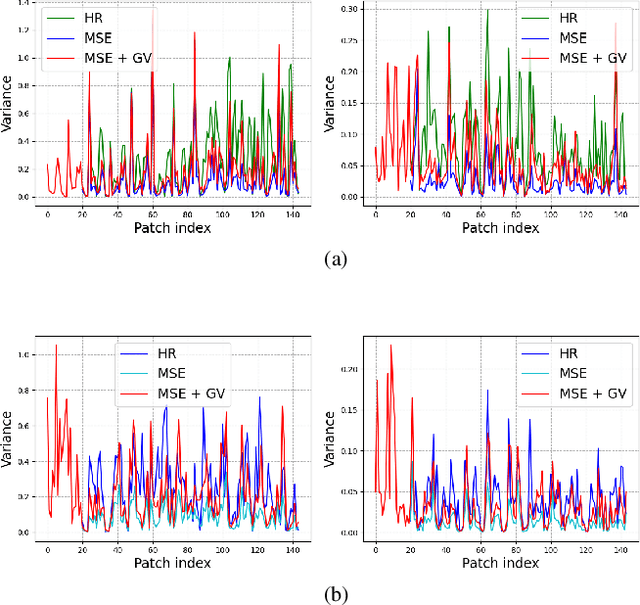
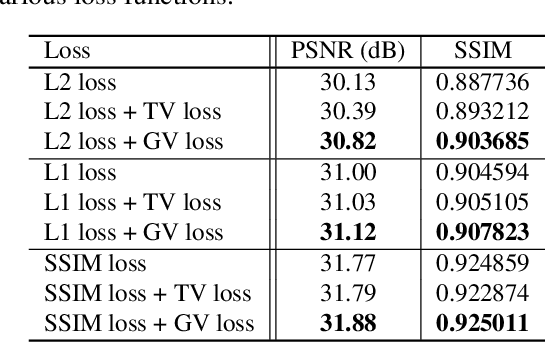
Recent success in the field of single image super-resolution (SISR) is achieved by optimizing deep convolutional neural networks (CNNs) in the image space with the L1 or L2 loss. However, when trained with these loss functions, models usually fail to recover sharp edges present in the high-resolution (HR) images for the reason that the model tends to give a statistical average of potential HR solutions. During our research, we observe that gradient maps of images generated by the models trained with the L1 or L2 loss have significantly lower variance than the gradient maps of the original high-resolution images. In this work, we propose to alleviate the above issue by introducing a structure-enhancing loss function, coined Gradient Variance (GV) loss, and generate textures with perceptual-pleasant details. Specifically, during the training of the model, we extract patches from the gradient maps of the target and generated output, calculate the variance of each patch and form variance maps for these two images. Further, we minimize the distance between the computed variance maps to enforce the model to produce high variance gradient maps that will lead to the generation of high-resolution images with sharper edges. Experimental results show that the GV loss can significantly improve both Structure Similarity (SSIM) and peak signal-to-noise ratio (PSNR) performance of existing image super-resolution (SR) deep learning models.
Bias Loss for Mobile Neural Networks
Aug 10, 2021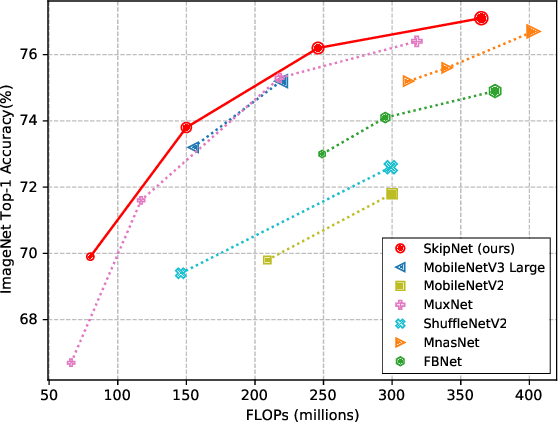
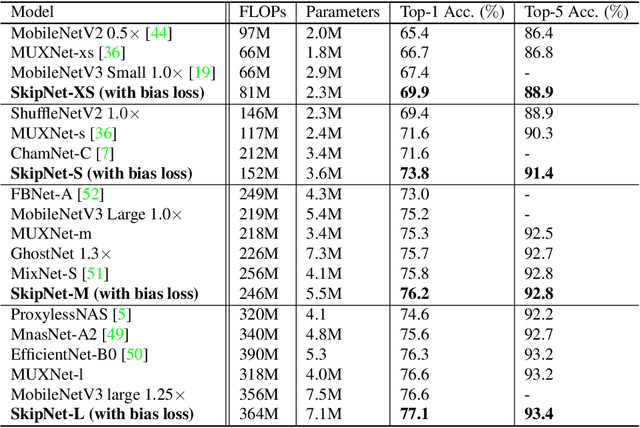
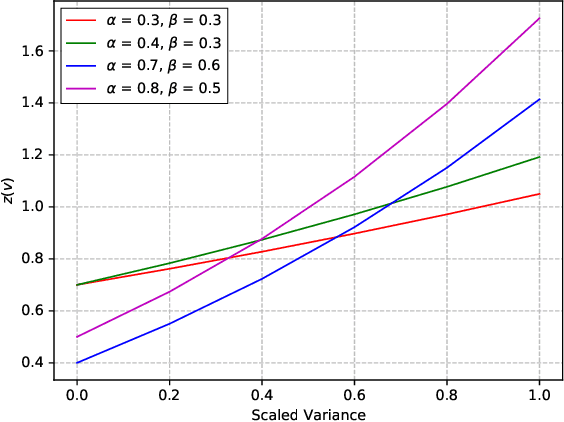
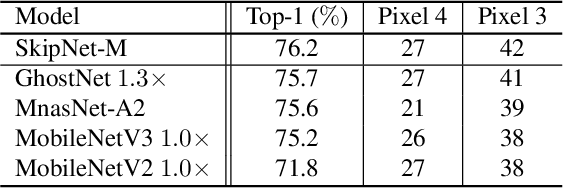
Compact convolutional neural networks (CNNs) have witnessed exceptional improvements in performance in recent years. However, they still fail to provide the same predictive power as CNNs with a large number of parameters. The diverse and even abundant features captured by the layers is an important characteristic of these successful CNNs. However, differences in this characteristic between large CNNs and their compact counterparts have rarely been investigated. In compact CNNs, due to the limited number of parameters, abundant features are unlikely to be obtained, and feature diversity becomes an essential characteristic. Diverse features present in the activation maps derived from a data point during model inference may indicate the presence of a set of unique descriptors necessary to distinguish between objects of different classes. In contrast, data points with low feature diversity may not provide a sufficient amount of unique descriptors to make a valid prediction; we refer to them as random predictions. Random predictions can negatively impact the optimization process and harm the final performance. This paper proposes addressing the problem raised by random predictions by reshaping the standard cross-entropy to make it biased toward data points with a limited number of unique descriptive features. Our novel Bias Loss focuses the training on a set of valuable data points and prevents the vast number of samples with poor learning features from misleading the optimization process. Furthermore, to show the importance of diversity, we present a family of SkipNet models whose architectures are brought to boost the number of unique descriptors in the last layers. Our Skipnet-M can achieve 1% higher classification accuracy than MobileNetV3 Large.
Learned Gradient Compression for Distributed Deep Learning
Mar 17, 2021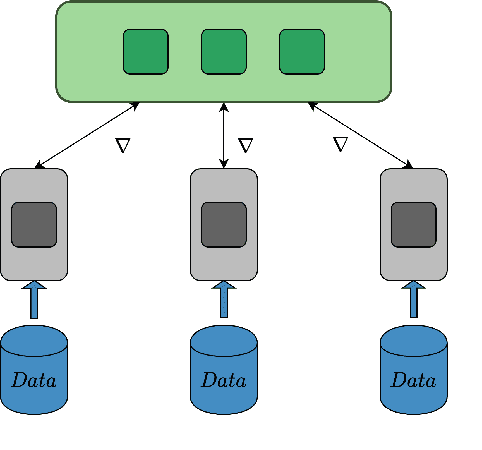
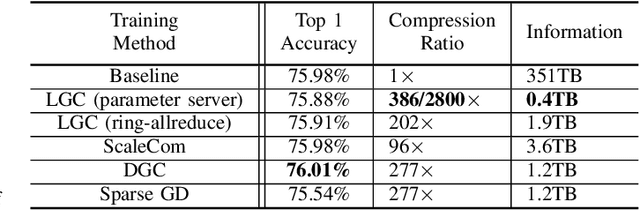
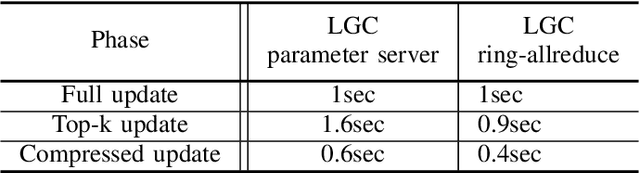
Training deep neural networks on large datasets containing high-dimensional data requires a large amount of computation. A solution to this problem is data-parallel distributed training, where a model is replicated into several computational nodes that have access to different chunks of the data. This approach, however, entails high communication rates and latency because of the computed gradients that need to be shared among nodes at every iteration. The problem becomes more pronounced in the case that there is wireless communication between the nodes (i.e. due to the limited network bandwidth). To address this problem, various compression methods have been proposed including sparsification, quantization, and entropy encoding of the gradients. Existing methods leverage the intra-node information redundancy, that is, they compress gradients at each node independently. In contrast, we advocate that the gradients across the nodes are correlated and propose methods to leverage this inter-node redundancy to improve compression efficiency. Depending on the node communication protocol (parameter server or ring-allreduce), we propose two instances of the LGC approach that we coin Learned Gradient Compression (LGC). Our methods exploit an autoencoder (i.e. trained during the first stages of the distributed training) to capture the common information that exists in the gradients of the distributed nodes. We have tested our LGC methods on the image classification and semantic segmentation tasks using different convolutional neural networks (ResNet50, ResNet101, PSPNet) and multiple datasets (ImageNet, Cifar10, CamVid). The ResNet101 model trained for image classification on Cifar10 achieved an accuracy of 93.57%, which is lower than the baseline distributed training with uncompressed gradients only by 0.18%.