 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Novel view synthesis of 360$^\circ$ Scenes in Extremely Sparse Views by Jointly Training Hemisphere Sampled Synthetic Images
May 25, 2025Novel view synthesis in 360$^\circ$ scenes from extremely sparse input views is essential for applications like virtual reality and augmented reality. This paper presents a novel framework for novel view synthesis in extremely sparse-view cases. As typical structure-from-motion methods are unable to estimate camera poses in extremely sparse-view cases, we apply DUSt3R to estimate camera poses and generate a dense point cloud. Using the poses of estimated cameras, we densely sample additional views from the upper hemisphere space of the scenes, from which we render synthetic images together with the point cloud. Training 3D Gaussian Splatting model on a combination of reference images from sparse views and densely sampled synthetic images allows a larger scene coverage in 3D space, addressing the overfitting challenge due to the limited input in sparse-view cases. Retraining a diffusion-based image enhancement model on our created dataset, we further improve the quality of the point-cloud-rendered images by removing artifacts. We compare our framework with benchmark methods in cases of only four input views, demonstrating significant improvement in novel view synthesis under extremely sparse-view conditions for 360$^\circ$ scenes.
Gradient Variance Loss for Structure-Enhanced Image Super-Resolution
Feb 02, 2022
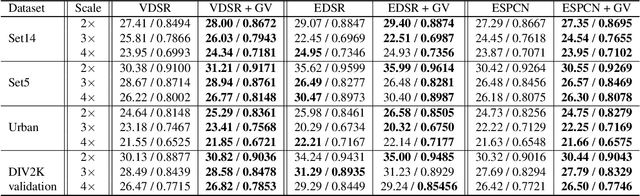
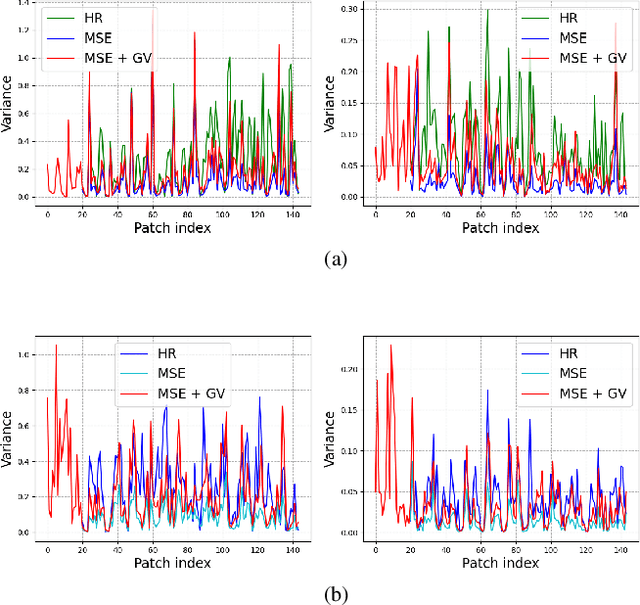
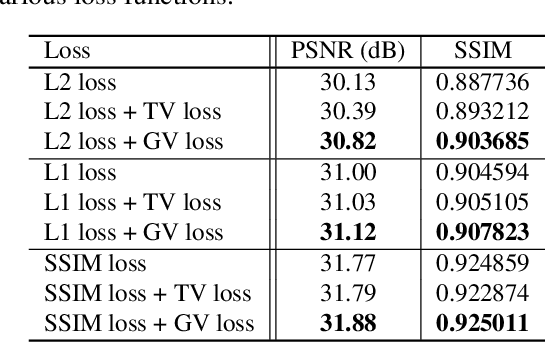
Recent success in the field of single image super-resolution (SISR) is achieved by optimizing deep convolutional neural networks (CNNs) in the image space with the L1 or L2 loss. However, when trained with these loss functions, models usually fail to recover sharp edges present in the high-resolution (HR) images for the reason that the model tends to give a statistical average of potential HR solutions. During our research, we observe that gradient maps of images generated by the models trained with the L1 or L2 loss have significantly lower variance than the gradient maps of the original high-resolution images. In this work, we propose to alleviate the above issue by introducing a structure-enhancing loss function, coined Gradient Variance (GV) loss, and generate textures with perceptual-pleasant details. Specifically, during the training of the model, we extract patches from the gradient maps of the target and generated output, calculate the variance of each patch and form variance maps for these two images. Further, we minimize the distance between the computed variance maps to enforce the model to produce high variance gradient maps that will lead to the generation of high-resolution images with sharper edges. Experimental results show that the GV loss can significantly improve both Structure Similarity (SSIM) and peak signal-to-noise ratio (PSNR) performance of existing image super-resolution (SR) deep learning models.