 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Novel view synthesis of 360$^\circ$ Scenes in Extremely Sparse Views by Jointly Training Hemisphere Sampled Synthetic Images
May 25, 2025Novel view synthesis in 360$^\circ$ scenes from extremely sparse input views is essential for applications like virtual reality and augmented reality. This paper presents a novel framework for novel view synthesis in extremely sparse-view cases. As typical structure-from-motion methods are unable to estimate camera poses in extremely sparse-view cases, we apply DUSt3R to estimate camera poses and generate a dense point cloud. Using the poses of estimated cameras, we densely sample additional views from the upper hemisphere space of the scenes, from which we render synthetic images together with the point cloud. Training 3D Gaussian Splatting model on a combination of reference images from sparse views and densely sampled synthetic images allows a larger scene coverage in 3D space, addressing the overfitting challenge due to the limited input in sparse-view cases. Retraining a diffusion-based image enhancement model on our created dataset, we further improve the quality of the point-cloud-rendered images by removing artifacts. We compare our framework with benchmark methods in cases of only four input views, demonstrating significant improvement in novel view synthesis under extremely sparse-view conditions for 360$^\circ$ scenes.
Degradation-Noise-Aware Deep Unfolding Transformer for Hyperspectral Image Denoising
May 06, 2023



Hyperspectral imaging (HI) has emerged as a powerful tool in diverse fields such as medical diagnosis, industrial inspection, and agriculture, owing to its ability to detect subtle differences in physical properties through high spectral resolution. However, hyperspectral images (HSIs) are often quite noisy because of narrow band spectral filtering. To reduce the noise in HSI data cubes, both model-driven and learning-based denoising algorithms have been proposed. However, model-based approaches rely on hand-crafted priors and hyperparameters, while learning-based methods are incapable of estimating the inherent degradation patterns and noise distributions in the imaging procedure, which could inform supervised learning. Secondly, learning-based algorithms predominantly rely on CNN and fail to capture long-range dependencies, resulting in limited interpretability. This paper proposes a Degradation-Noise-Aware Unfolding Network (DNA-Net) that addresses these issues. Firstly, DNA-Net models sparse noise, Gaussian noise, and explicitly represent image prior using transformer. Then the model is unfolded into an end-to-end network, the hyperparameters within the model are estimated from the noisy HSI and degradation model and utilizes them to control each iteration. Additionally, we introduce a novel U-Shaped Local-Non-local-Spectral Transformer (U-LNSA) that captures spectral correlation, local contents, and non-local dependencies simultaneously. By integrating U-LNSA into DNA-Net, we present the first Transformer-based deep unfolding HSI denoising method. Experimental results show that DNA-Net outperforms state-of-the-art methods, and the modeling of noise distributions helps in cases with heavy noise.
MSFA-Frequency-Aware Transformer for Hyperspectral Images Demosaicing
Mar 23, 2023



Hyperspectral imaging systems that use multispectral filter arrays (MSFA) capture only one spectral component in each pixel. Hyperspectral demosaicing is used to recover the non-measured components. While deep learning methods have shown promise in this area, they still suffer from several challenges, including limited modeling of non-local dependencies, lack of consideration of the periodic MSFA pattern that could be linked to periodic artifacts, and difficulty in recovering high-frequency details. To address these challenges, this paper proposes a novel de-mosaicing framework, the MSFA-frequency-aware Transformer network (FDM-Net). FDM-Net integrates a novel MSFA-frequency-aware multi-head self-attention mechanism (MaFormer) and a filter-based Fourier zero-padding method to reconstruct high pass components with greater difficulty and low pass components with relative ease, separately. The advantage of Maformer is that it can leverage the MSFA information and non-local dependencies present in the data. Additionally, we introduce a joint spatial and frequency loss to transfer MSFA information and enhance training on frequency components that are hard to recover. Our experimental results demonstrate that FDM-Net outperforms state-of-the-art methods with 6dB PSNR, and reconstructs high-fidelity details successfully.
Inheriting Bayer's Legacy-Joint Remosaicing and Denoising for Quad Bayer Image Sensor
Mar 23, 2023Pixel binning based Quad sensors have emerged as a promising solution to overcome the hardware limitations of compact cameras in low-light imaging. However, binning results in lower spatial resolution and non-Bayer CFA artifacts. To address these challenges, we propose a dual-head joint remosaicing and denoising network (DJRD), which enables the conversion of noisy Quad Bayer and standard noise-free Bayer pattern without any resolution loss. DJRD includes a newly designed Quad Bayer remosaicing (QB-Re) block, integrated denoising modules based on Swin-transformer and multi-scale wavelet transform. The QB-Re block constructs the convolution kernel based on the CFA pattern to achieve a periodic color distribution in the perceptual field, which is used to extract exact spectral information and reduce color misalignment. The integrated Swin-Transformer and multi-scale wavelet transform capture non-local dependencies, frequency and location information to effectively reduce practical noise. By identifying challenging patches utilizing Moire and zipper detection metrics, we enable our model to concentrate on difficult patches during the post-training phase, which enhances the model's performance in hard cases. Our proposed model outperforms competing models by approximately 3dB, without additional complexity in hardware or software.
Low-rank Meets Sparseness: An Integrated Spatial-Spectral Total Variation Approach to Hyperspectral Denoising
Apr 27, 2022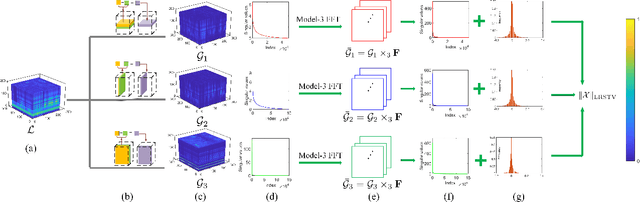

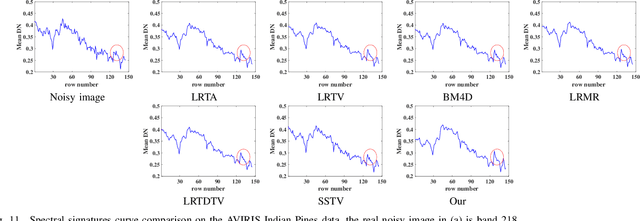

Spatial-Spectral Total Variation (SSTV) can quantify local smoothness of image structures, so it is widely used in hyperspectral image (HSI) processing tasks. Essentially, SSTV assumes a sparse structure of gradient maps calculated along the spatial and spectral directions. In fact, these gradient tensors are not only sparse, but also (approximately) low-rank under FFT, which we have verified by numerical tests and theoretical analysis. Based on this fact, we propose a novel TV regularization to simultaneously characterize the sparsity and low-rank priors of the gradient map (LRSTV). The new regularization not only imposes sparsity on the gradient map itself, but also penalize the rank on the gradient map after Fourier transform along the spectral dimension. It naturally encodes the sparsity and lowrank priors of the gradient map, and thus is expected to reflect the inherent structure of the original image more faithfully. Further, we use LRSTV to replace conventional SSTV and embed it in the HSI processing model to improve its performance. Experimental results on multiple public data-sets with heavy mixed noise show that the proposed model can get 1.5dB improvement of PSNR.
Gradient Variance Loss for Structure-Enhanced Image Super-Resolution
Feb 02, 2022
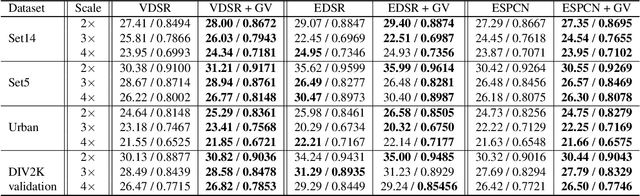
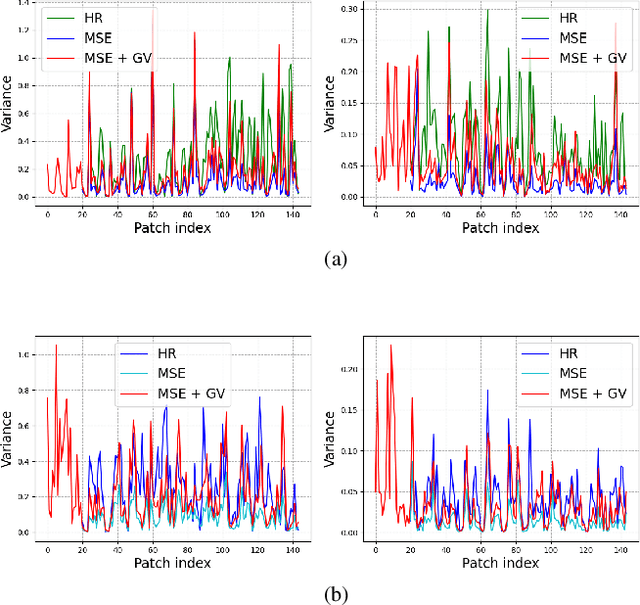
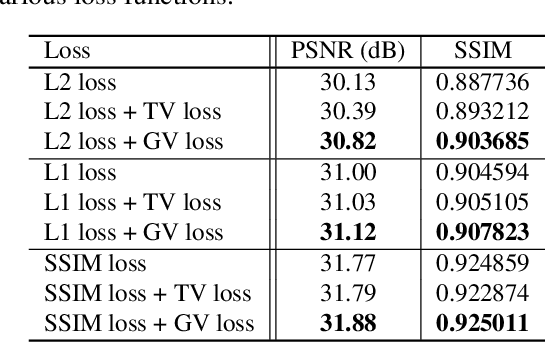
Recent success in the field of single image super-resolution (SISR) is achieved by optimizing deep convolutional neural networks (CNNs) in the image space with the L1 or L2 loss. However, when trained with these loss functions, models usually fail to recover sharp edges present in the high-resolution (HR) images for the reason that the model tends to give a statistical average of potential HR solutions. During our research, we observe that gradient maps of images generated by the models trained with the L1 or L2 loss have significantly lower variance than the gradient maps of the original high-resolution images. In this work, we propose to alleviate the above issue by introducing a structure-enhancing loss function, coined Gradient Variance (GV) loss, and generate textures with perceptual-pleasant details. Specifically, during the training of the model, we extract patches from the gradient maps of the target and generated output, calculate the variance of each patch and form variance maps for these two images. Further, we minimize the distance between the computed variance maps to enforce the model to produce high variance gradient maps that will lead to the generation of high-resolution images with sharper edges. Experimental results show that the GV loss can significantly improve both Structure Similarity (SSIM) and peak signal-to-noise ratio (PSNR) performance of existing image super-resolution (SR) deep learning models.
Resolution based Feature Distillation for Cross Resolution Person Re-Identification
Sep 16, 2021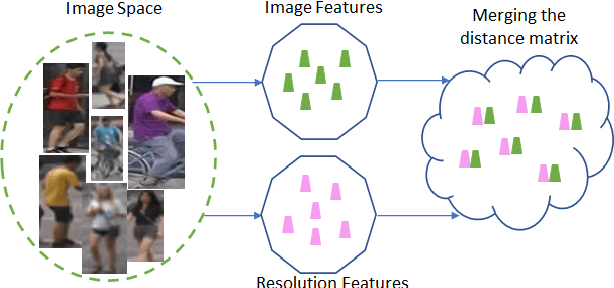
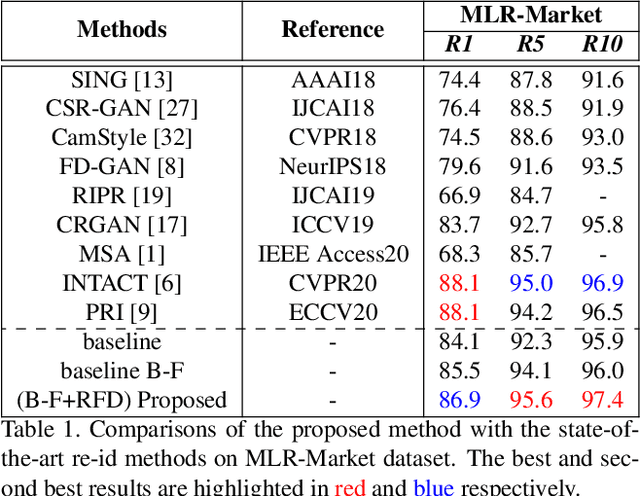
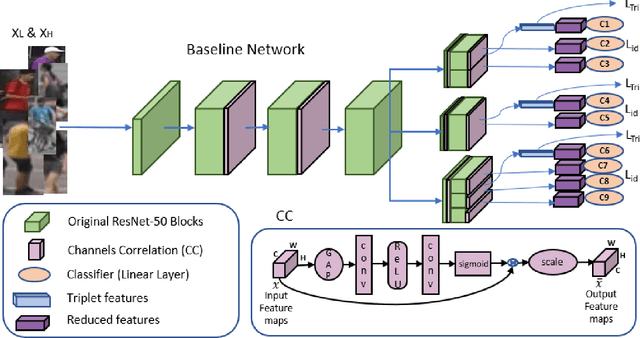
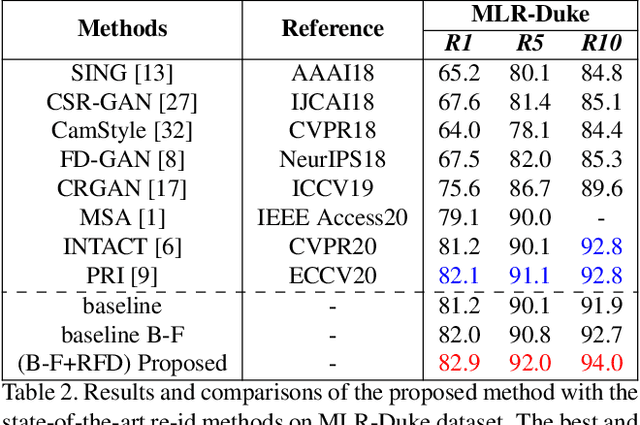
Person re-identification (re-id) aims to retrieve images of same identities across different camera views. Resolution mismatch occurs due to varying distances between person of interest and cameras, this significantly degrades the performance of re-id in real world scenarios. Most of the existing approaches resolve the re-id task as low resolution problem in which a low resolution query image is searched in a high resolution images gallery. Several approaches apply image super resolution techniques to produce high resolution images but ignore the multiple resolutions of gallery images which is a better realistic scenario. In this paper, we introduce channel correlations to improve the learning of features from the degraded data. In addition, to overcome the problem of multiple resolutions we propose a Resolution based Feature Distillation (RFD) approach. Such an approach learns resolution invariant features by filtering the resolution related features from the final feature vectors that are used to compute the distance matrix. We tested the proposed approach on two synthetically created datasets and on one original multi resolution dataset with real degradation. Our approach improves the performance when multiple resolutions occur in the gallery and have comparable results in case of single resolution (low resolution re-id).
Matrix Completion With Variational Graph Autoencoders: Application in Hyperlocal Air Quality Inference
Nov 05, 2018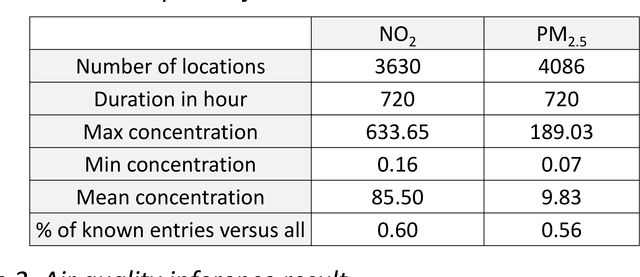
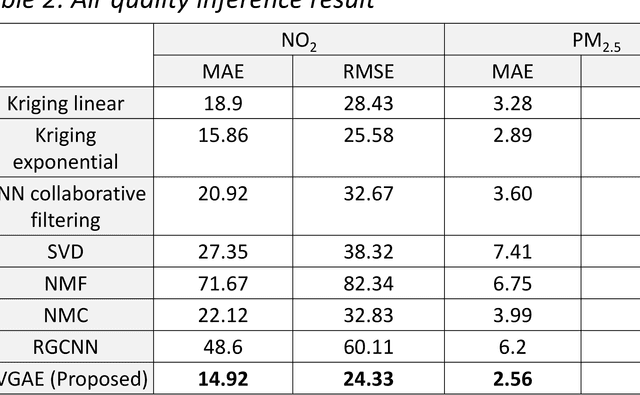
Inferring air quality from a limited number of observations is an essential task for monitoring and controlling air pollution. Existing inference methods typically use low spatial resolution data collected by fixed monitoring stations and infer the concentration of air pollutants using additional types of data, e.g., meteorological and traffic information. In this work, we focus on street-level air quality inference by utilizing data collected by mobile stations. We formulate air quality inference in this setting as a graph-based matrix completion problem and propose a novel variational model based on graph convolutional autoencoders. Our model captures effectively the spatio-temporal correlation of the measurements and does not depend on the availability of additional information apart from the street-network topology. Experiments on a real air quality dataset, collected with mobile stations, shows that the proposed model outperforms state-of-the-art approaches.
Bayesian Deconvolution of Scanning Electron Microscopy Images Using Point-spread Function Estimation and Non-local Regularization
Oct 23, 2018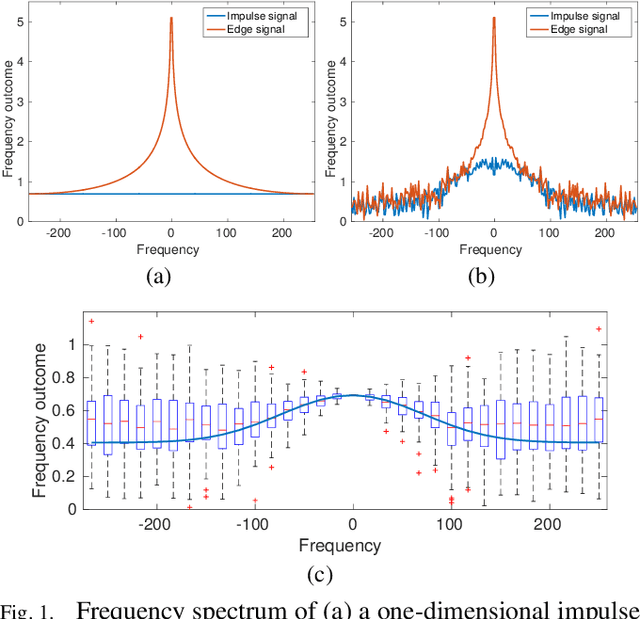
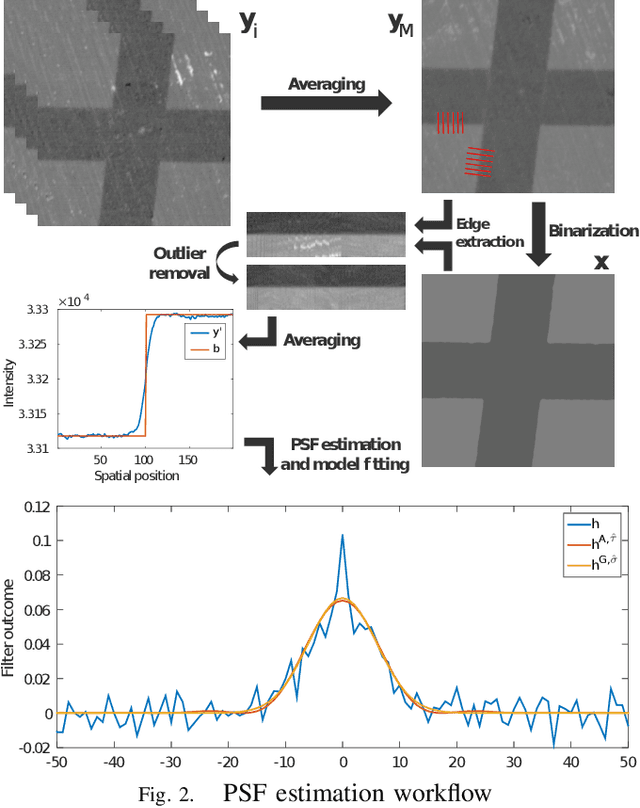
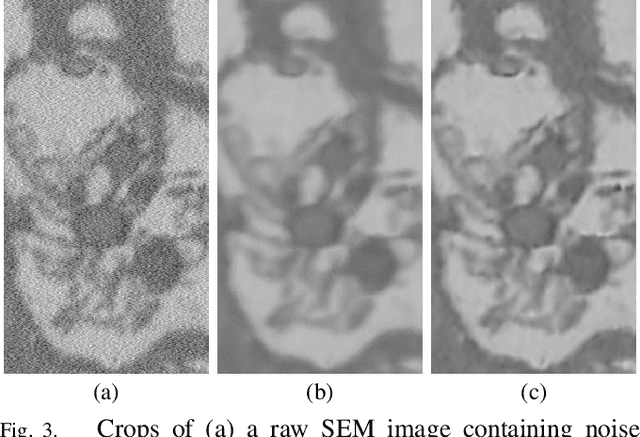
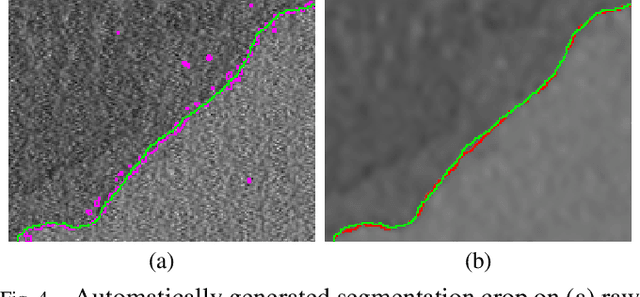
Microscopy is one of the most essential imaging techniques in life sciences. High-quality images are required in order to solve (potentially life-saving) biomedical research problems. Many microscopy techniques do not achieve sufficient resolution for these purposes, being limited by physical diffraction and hardware deficiencies. Electron microscopy addresses optical diffraction by measuring emitted or transmitted electrons instead of photons, yielding nanometer resolution. Despite pushing back the diffraction limit, blur should still be taken into account because of practical hardware imperfections and remaining electron diffraction. Deconvolution algorithms can remove some of the blur in post-processing but they depend on knowledge of the point-spread function (PSF) and should accurately regularize noise. Any errors in the estimated PSF or noise model will reduce their effectiveness. This paper proposes a new procedure to estimate the lateral component of the point spread function of a 3D scanning electron microscope more accurately. We also propose a Bayesian maximum a posteriori deconvolution algorithm with a non-local image prior which employs this PSF estimate and previously developed noise statistics. We demonstrate visual quality improvements and show that applying our method improves the quality of subsequent segmentation steps.
Convolutional Neural Network Pruning to Accelerate Membrane Segmentation in Electron Microscopy
Oct 23, 2018
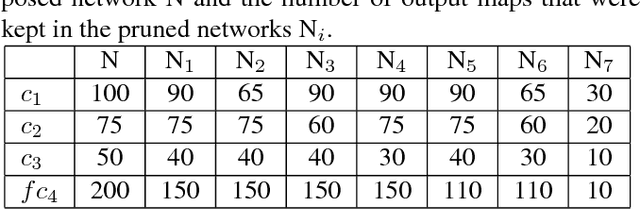
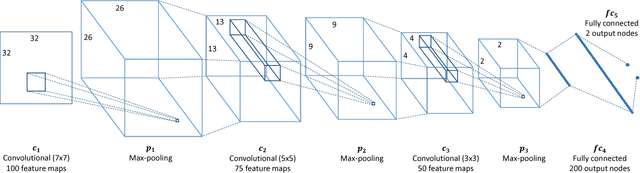
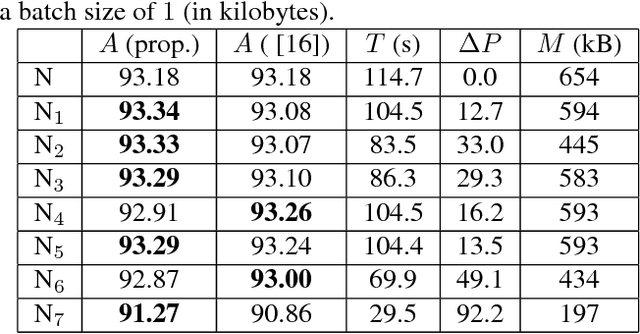
Biological membranes are one of the most basic structures and regions of interest in cell biology. In the study of membranes, segment extraction is a well-known and difficult problem because of impeding noise, directional and thickness variability, etc. Recent advances in electron microscopy membrane segmentation are able to cope with such difficulties by training convolutional neural networks. However, because of the massive amount of features that have to be extracted while propagating forward, the practical usability diminishes, even with state-of-the-art GPU's. A significant part of these network features typically contains redundancy through correlation and sparsity. In this work, we propose a pruning method for convolutional neural networks that ensures the training loss increase is minimized. We show that the pruned networks, after retraining, are more efficient in terms of time and memory, without significantly affecting the network accuracy. This way, we manage to obtain real-time membrane segmentation performance, for our specific electron microscopy setup.