 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Multigrid Memory For Computational Fluid Dynamics
Jun 24, 2023Turbulent flow simulation plays a crucial role in various applications, including aircraft and ship design, industrial process optimization, and weather prediction. In this paper, we propose an advanced data-driven method for simulating turbulent flow, representing a significant improvement over existing approaches. Our methodology combines the strengths of Video Prediction Transformer (VPTR) (Ye & Bilodeau, 2022) and Multigrid Architecture (MgConv, MgResnet) (Ke et al., 2017). VPTR excels in capturing complex spatiotemporal dependencies and handling large input data, making it a promising choice for turbulent flow prediction. Meanwhile, Multigrid Architecture utilizes multiple grids with different resolutions to capture the multiscale nature of turbulent flows, resulting in more accurate and efficient simulations. Through our experiments, we demonstrate the effectiveness of our proposed approach, named MGxTransformer, in accurately predicting velocity, temperature, and turbulence intensity for incompressible turbulent flows across various geometries and flow conditions. Our results exhibit superior accuracy compared to other baselines, while maintaining computational efficiency. Our implementation in PyTorch is available publicly at https://github.com/Combi2k2/MG-Turbulent-Flow
Temporal Collaborative Filtering with Graph Convolutional Neural Networks
Oct 13, 2020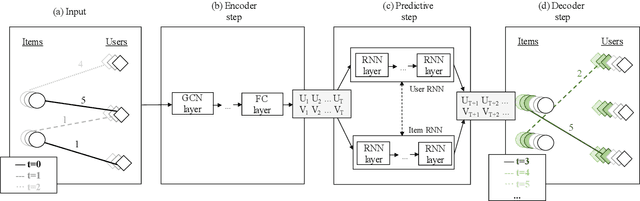


Temporal collaborative filtering (TCF) methods aim at modelling non-static aspects behind recommender systems, such as the dynamics in users' preferences and social trends around items. State-of-the-art TCF methods employ recurrent neural networks (RNNs) to model such aspects. These methods deploy matrix-factorization-based (MF-based) approaches to learn the user and item representations. Recently, graph-neural-network-based (GNN-based) approaches have shown improved performance in providing accurate recommendations over traditional MF-based approaches in non-temporal CF settings. Motivated by this, we propose a novel TCF method that leverages GNNs to learn user and item representations, and RNNs to model their temporal dynamics. A challenge with this method lies in the increased data sparsity, which negatively impacts obtaining meaningful quality representations with GNNs. To overcome this challenge, we train a GNN model at each time step using a set of observed interactions accumulated time-wise. Comprehensive experiments on real-world data show the improved performance obtained by our method over several state-of-the-art temporal and non-temporal CF models.
Graph Convolutional Neural Networks with Node Transition Probability-based Message Passing and DropNode Regularization
Aug 28, 2020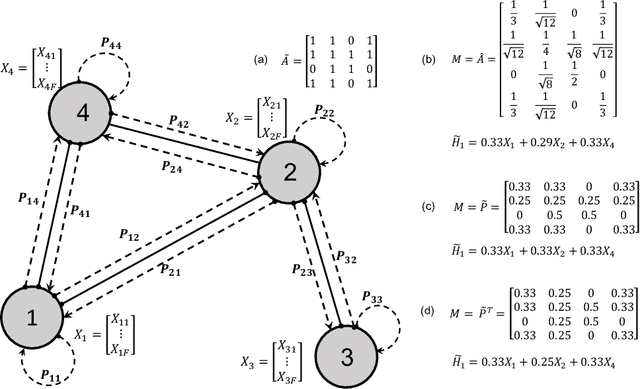
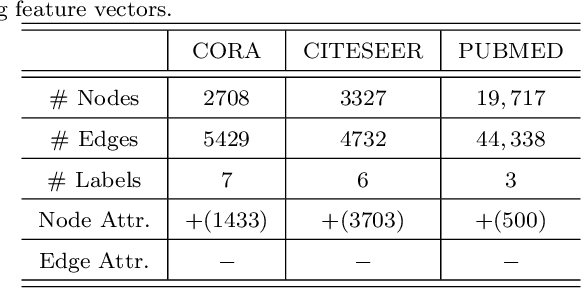
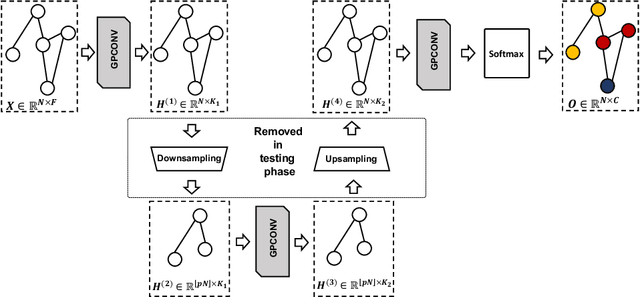
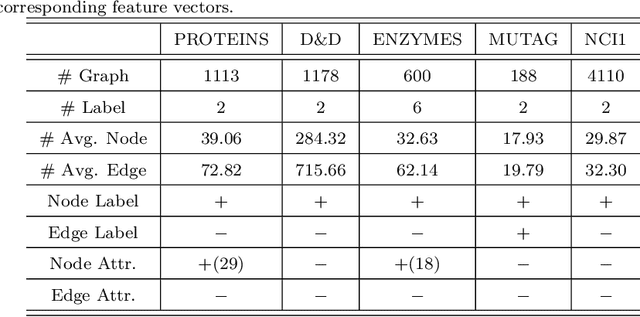
Graph convolutional neural networks (GCNNs) have received much attention recently, owing to their capability in handling graph-structured data. Among the existing GCNNs, many methods can be viewed as instances of a neural message passing motif; features of nodes are passed around their neighbors, aggregated and transformed to produce better nodes' representations. Nevertheless, these methods seldom use node transition probabilities, a measure that has been found useful in exploring graphs. Furthermore, when the transition probabilities are used, their transition direction is often improperly considered in the feature aggregation step, resulting in an inefficient weighting scheme. In addition, although a great number of GCNN models with increasing level of complexity have been introduced, the GCNNs often suffer from over-fitting when being trained on small graphs. Another issue of the GCNNs is over-smoothing, which tends to make nodes' representations indistinguishable. This work presents a new method to improve the message passing process based on node transition probabilities by properly considering the transition direction, leading to a better weighting scheme in nodes' features aggregation compared to the existing counterpart. Moreover, we propose a novel regularization method termed DropNode to address the over-fitting and over-smoothing issues simultaneously. DropNode randomly discards part of a graph, thus it creates multiple deformed versions of the graph, leading to data augmentation regularization effect. Additionally, DropNode lessens the connectivity of the graph, mitigating the effect of over-smoothing in deep GCNNs. Extensive experiments on eight benchmark datasets for node and graph classification tasks demonstrate the effectiveness of the proposed methods in comparison with the state of the art.
Rumour Detection via News Propagation Dynamics and User Representation Learning
Apr 18, 2019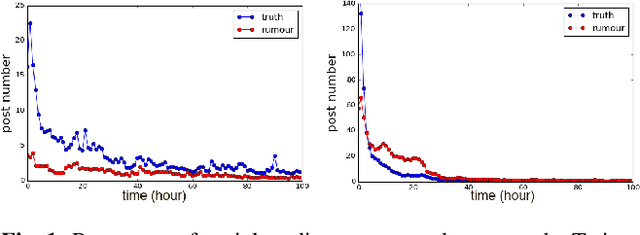
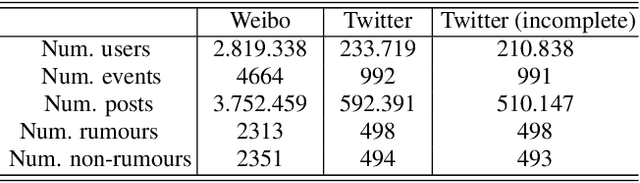
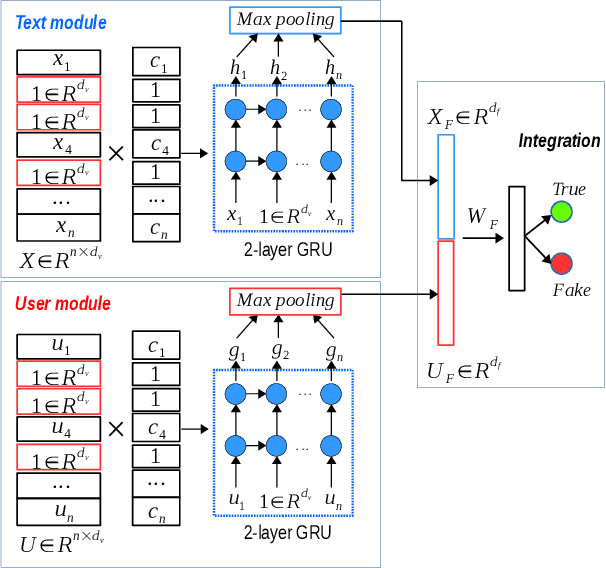
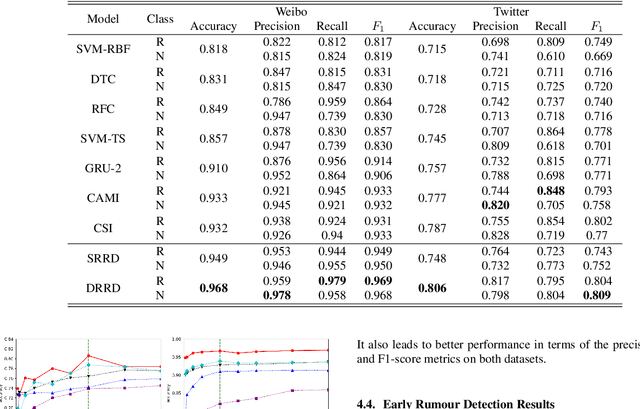
Rumours have existed for a long time and have been known for serious consequences. The rapid growth of social media platforms has multiplied the negative impact of rumours; it thus becomes important to early detect them. Many methods have been introduced to detect rumours using the content or the social context of news. However, most existing methods ignore or do not explore effectively the propagation pattern of news in social media, including the sequence of interactions of social media users with news across time. In this work, we propose a novel method for rumour detection based on deep learning. Our method leverages the propagation process of the news by learning the users' representation and the temporal interrelation of users' responses. Experiments conducted on Twitter and Weibo datasets demonstrate the state-of-the-art performance of the proposed method.
Geometric Matrix Completion with Deep Conditional Random Fields
Jan 29, 2019
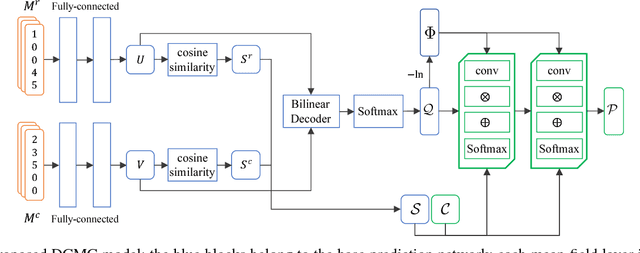
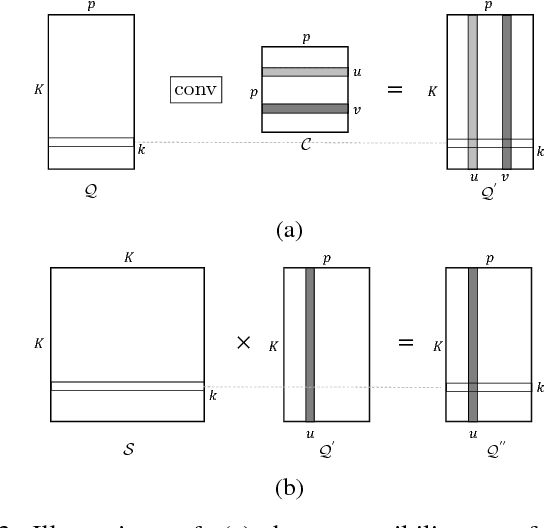
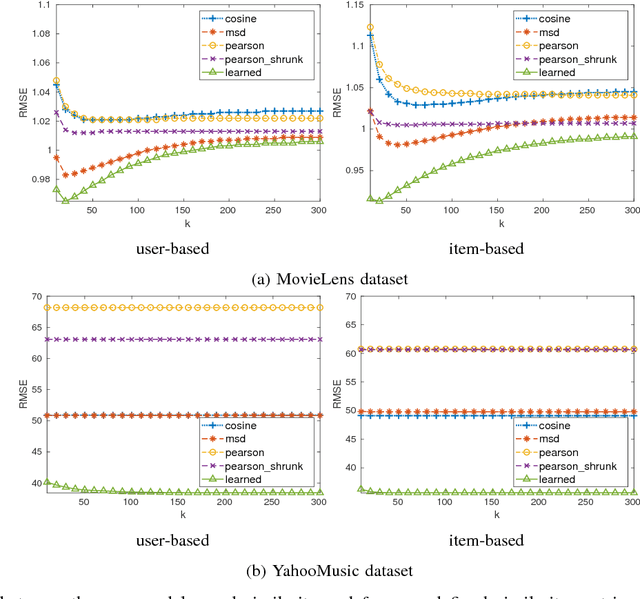
The problem of completing high-dimensional matrices from a limited set of observations arises in many big data applications, especially, recommender systems. Existing matrix completion models generally follow either a memory- or a model-based approach, whereas, geometric matrix completion models combine the best from both approaches. Existing deep-learning-based geometric models yield good performance, but, in order to operate, they require a fixed structure graph capturing the relationships among the users and items. This graph is typically constructed by evaluating a pre-defined similarity metric on the available observations or by using side information, e.g., user profiles. In contrast, Markov-random-fields-based models do not require a fixed structure graph but rely on handcrafted features to make predictions. When no side information is available and the number of available observations becomes very low, existing solutions are pushed to their limits. In this paper, we propose a geometric matrix completion approach that addresses these challenges. We consider matrix completion as a structured prediction problem in a conditional random field (CRF), which is characterized by a maximum a posterior (MAP) inference, and we propose a deep model that predicts the missing entries by solving the MAP inference problem. The proposed model simultaneously learns the similarities among matrix entries, computes the CRF potentials, and solves the inference problem. Its training is performed in an end-to-end manner, with a method to supervise the learning of entry similarities. Comprehensive experiments demonstrate the superior performance of the proposed model compared to various state-of-the-art models on popular benchmark datasets and underline its superior capacity to deal with highly incomplete matrices.
Matrix Factorization via Deep Learning
Dec 04, 2018

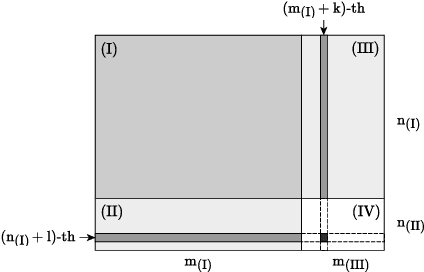
Matrix completion is one of the key problems in signal processing and machine learning. In recent years, deep-learning-based models have achieved state-of-the-art results in matrix completion. Nevertheless, they suffer from two drawbacks: (i) they can not be extended easily to rows or columns unseen during training; and (ii) their results are often degraded in case discrete predictions are required. This paper addresses these two drawbacks by presenting a deep matrix factorization model and a generic method to allow joint training of the factorization model and the discretization operator. Experiments on a real movie rating dataset show the efficacy of the proposed models.
Matrix Completion With Variational Graph Autoencoders: Application in Hyperlocal Air Quality Inference
Nov 05, 2018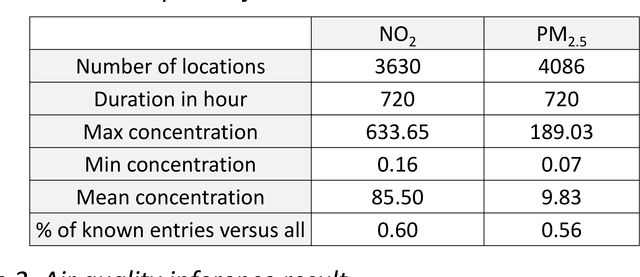
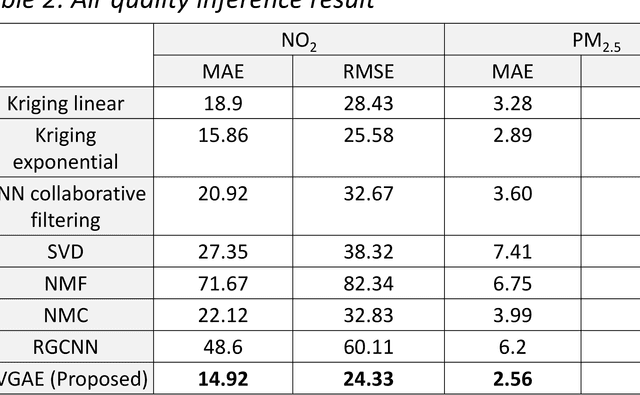
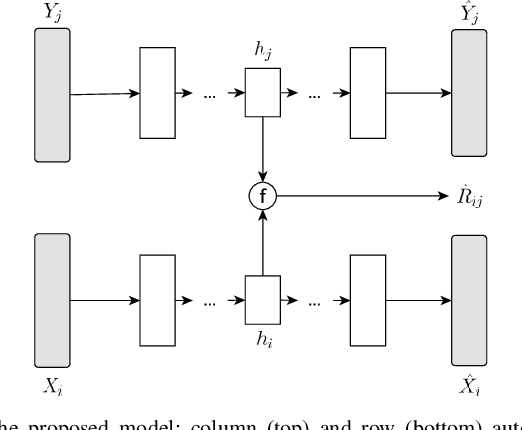
Inferring air quality from a limited number of observations is an essential task for monitoring and controlling air pollution. Existing inference methods typically use low spatial resolution data collected by fixed monitoring stations and infer the concentration of air pollutants using additional types of data, e.g., meteorological and traffic information. In this work, we focus on street-level air quality inference by utilizing data collected by mobile stations. We formulate air quality inference in this setting as a graph-based matrix completion problem and propose a novel variational model based on graph convolutional autoencoders. Our model captures effectively the spatio-temporal correlation of the measurements and does not depend on the availability of additional information apart from the street-network topology. Experiments on a real air quality dataset, collected with mobile stations, shows that the proposed model outperforms state-of-the-art approaches.
Regularizing Autoencoder-Based Matrix Completion Models via Manifold Learning
Jul 04, 2018


Autoencoders are popular among neural-network-based matrix completion models due to their ability to retrieve potential latent factors from the partially observed matrices. Nevertheless, when training data is scarce their performance is significantly degraded due to overfitting. In this paper, we mit- igate overfitting with a data-dependent regularization technique that relies on the principles of multi-task learning. Specifically, we propose an autoencoder-based matrix completion model that performs prediction of the unknown matrix values as a main task, and manifold learning as an auxiliary task. The latter acts as an inductive bias, leading to solutions that generalize better. The proposed model outperforms the existing autoencoder-based models designed for matrix completion, achieving high reconstruction accuracy in well-known datasets.
Extendable Neural Matrix Completion
May 13, 2018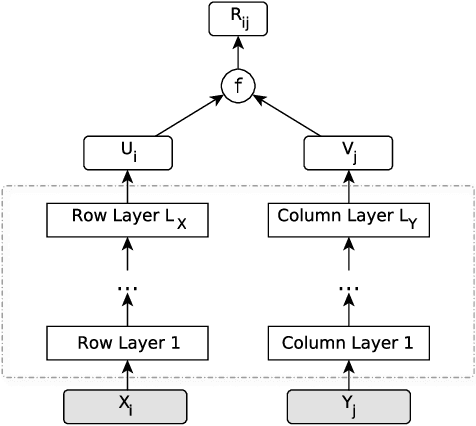
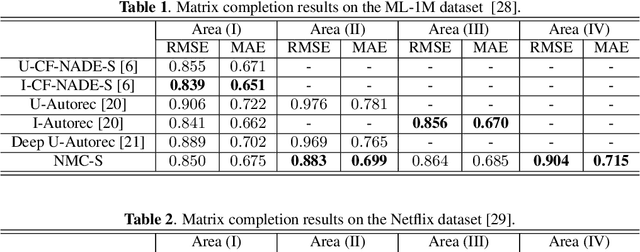
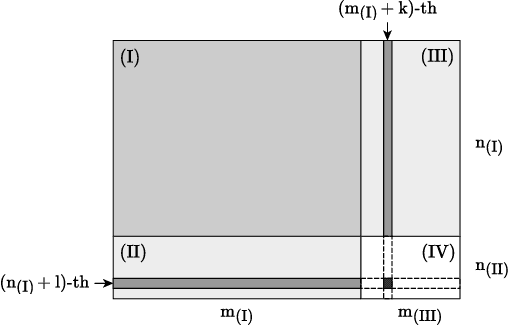

Matrix completion is one of the key problems in signal processing and machine learning, with applications ranging from image pro- cessing and data gathering to classification and recommender sys- tems. Recently, deep neural networks have been proposed as la- tent factor models for matrix completion and have achieved state- of-the-art performance. Nevertheless, a major problem with existing neural-network-based models is their limited capabilities to extend to samples unavailable at the training stage. In this paper, we propose a deep two-branch neural network model for matrix completion. The proposed model not only inherits the predictive power of neural net- works, but is also capable of extending to partially observed samples outside the training set, without the need of retraining or fine-tuning. Experimental studies on popular movie rating datasets prove the ef- fectiveness of our model compared to the state of the art, in terms of both accuracy and extendability.
Twitter User Geolocation using Deep Multiview Learning
May 11, 2018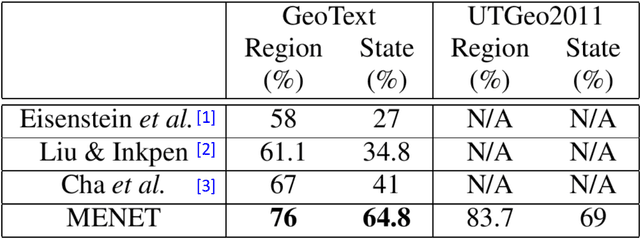
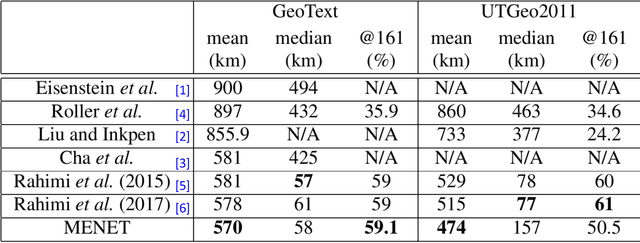
Predicting the geographical location of users on social networks like Twitter is an active research topic with plenty of methods proposed so far. Most of the existing work follows either a content-based or a network-based approach. The former is based on user-generated content while the latter exploits the structure of the network of users. In this paper, we propose a more generic approach, which incorporates not only both content-based and network-based features, but also other available information into a unified model. Our approach, named Multi-Entry Neural Network (MENET), leverages the latest advances in deep learning and multiview learning. A realization of MENET with textual, network and metadata features results in an effective method for Twitter user geolocation, achieving the state of the art on two well-known datasets.