 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCalibration of Vehicular Traffic Simulation Models by Local Optimization
Feb 17, 2025Simulation is a valuable tool for traffic management experts to assist them in refining and improving transportation systems and anticipating the impact of possible changes in the infrastructure network before their actual implementation. Calibrating simulation models using traffic count data is challenging because of the complexity of the environment, the lack of data, and the uncertainties in traffic dynamics. This paper introduces a novel stochastic simulation-based traffic calibration technique. The novelty of the proposed method is: (i) it performs local traffic calibration, (ii) it allows calibrating simulated traffic in large-scale environments, (iii) it requires only the traffic count data. The local approach enables decentralizing the calibration task to reach near real-time performance, enabling the fostering of digital twins. Using only traffic count data makes the proposed method generic so that it can be applied in different traffic scenarios at various scales (from neighborhood to region). We assess the proposed technique on a model of Brussels, Belgium, using data from real traffic monitoring devices. The proposed method has been implemented using the open-source traffic simulator SUMO. Experimental results show that the traffic model calibrated using the proposed method is on average 16% more accurate than those obtained by the state-of-the-art methods, using the same dataset. We also make available the output traffic model obtained from real data.
HybridTrack: A Hybrid Approach for Robust Multi-Object Tracking
Jan 02, 2025



The evolution of Advanced Driver Assistance Systems (ADAS) has increased the need for robust and generalizable algorithms for multi-object tracking. Traditional statistical model-based tracking methods rely on predefined motion models and assumptions about system noise distributions. Although computationally efficient, they often lack adaptability to varying traffic scenarios and require extensive manual design and parameter tuning. To address these issues, we propose a novel 3D multi-object tracking approach for vehicles, HybridTrack, which integrates a data-driven Kalman Filter (KF) within a tracking-by-detection paradigm. In particular, it learns the transition residual and Kalman gain directly from data, which eliminates the need for manual motion and stochastic parameter modeling. Validated on the real-world KITTI dataset, HybridTrack achieves 82.08% HOTA accuracy, significantly outperforming state-of-the-art methods. We also evaluate our method under different configurations, achieving the fastest processing speed of 112 FPS. Consequently, HybridTrack eliminates the dependency on scene-specific designs while improving performance and maintaining real-time efficiency. The code will be publicly available at the time of publishing: https://github.com/leandro-svg/HybridTrack.git.
Strada-LLM: Graph LLM for traffic prediction
Oct 28, 2024



Traffic prediction is a vital component of intelligent transportation systems. By reasoning about traffic patterns in both the spatial and temporal dimensions, accurate and interpretable predictions can be provided. A considerable challenge in traffic prediction lies in handling the diverse data distributions caused by vastly different traffic conditions occurring at different locations. LLMs have been a dominant solution due to their remarkable capacity to adapt to new datasets with very few labeled data samples, i.e., few-shot adaptability. However, existing forecasting techniques mainly focus on extracting local graph information and forming a text-like prompt, leaving LLM- based traffic prediction an open problem. This work presents a probabilistic LLM for traffic forecasting with three highlights. We propose a graph-aware LLM for traffic prediction that considers proximal traffic information. Specifically, by considering the traffic of neighboring nodes as covariates, our model outperforms the corresponding time-series LLM. Furthermore, we adopt a lightweight approach for efficient domain adaptation when facing new data distributions in few-shot fashion. The comparative experiment demonstrates the proposed method outperforms the state-of-the-art LLM-based methods and the traditional GNN- based supervised approaches. Furthermore, Strada-LLM can be easily adapted to different LLM backbones without a noticeable performance drop.
Interpretable Deep Multimodal Image Super-Resolution
Sep 07, 2020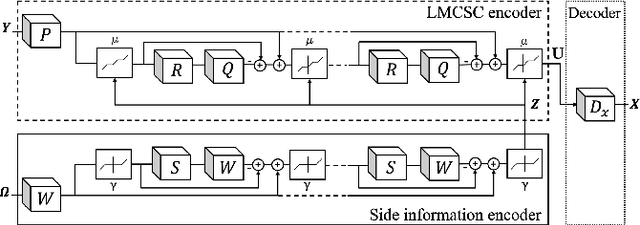
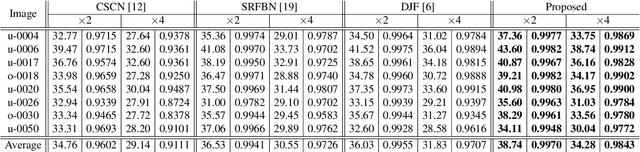

Multimodal image super-resolution (SR) is the reconstruction of a high resolution image given a low-resolution observation with the aid of another image modality. While existing deep multimodal models do not incorporate domain knowledge about image SR, we present a multimodal deep network design that integrates coupled sparse priors and allows the effective fusion of information from another modality into the reconstruction process. Our method is inspired by a novel iterative algorithm for coupled convolutional sparse coding, resulting in an interpretable network by design. We apply our model to the super-resolution of near-infrared image guided by RGB images. Experimental results show that our model outperforms state-of-the-art methods.
Multimodal Deep Unfolding for Guided Image Super-Resolution
Jan 21, 2020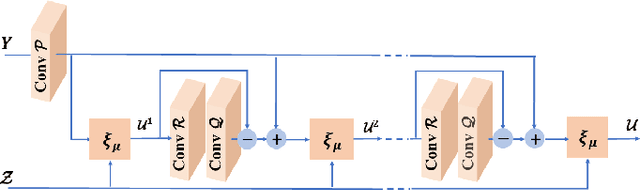
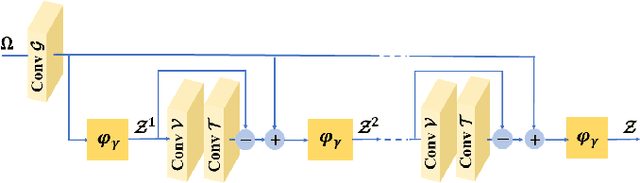
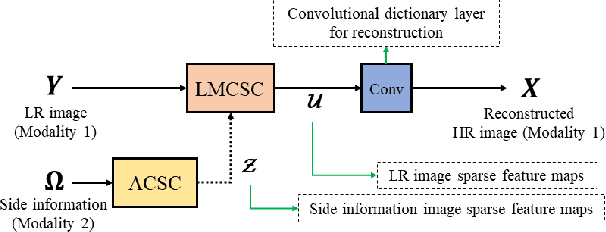
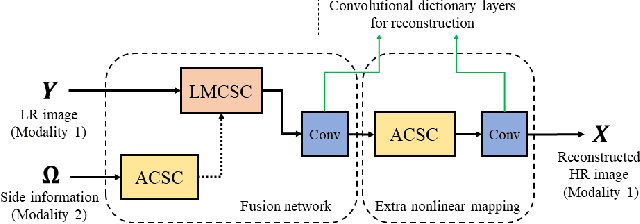
The reconstruction of a high resolution image given a low resolution observation is an ill-posed inverse problem in imaging. Deep learning methods rely on training data to learn an end-to-end mapping from a low-resolution input to a high-resolution output. Unlike existing deep multimodal models that do not incorporate domain knowledge about the problem, we propose a multimodal deep learning design that incorporates sparse priors and allows the effective integration of information from another image modality into the network architecture. Our solution relies on a novel deep unfolding operator, performing steps similar to an iterative algorithm for convolutional sparse coding with side information; therefore, the proposed neural network is interpretable by design. The deep unfolding architecture is used as a core component of a multimodal framework for guided image super-resolution. An alternative multimodal design is investigated by employing residual learning to improve the training efficiency. The presented multimodal approach is applied to super-resolution of near-infrared and multi-spectral images as well as depth upsampling using RGB images as side information. Experimental results show that our model outperforms state-of-the-art methods.
Multimodal Image Super-resolution via Deep Unfolding with Side Information
Oct 18, 2019
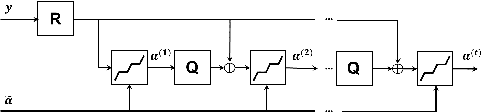
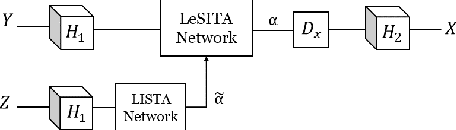
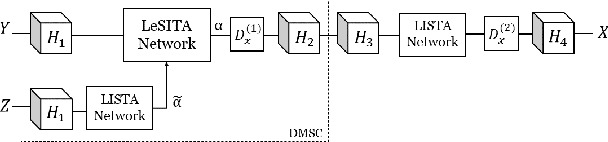
Deep learning methods have been successfully applied to various computer vision tasks. However, existing neural network architectures do not per se incorporate domain knowledge about the addressed problem, thus, understanding what the model has learned is an open research topic. In this paper, we rely on the unfolding of an iterative algorithm for sparse approximation with side information, and design a deep learning architecture for multimodal image super-resolution that incorporates sparse priors and effectively utilizes information from another image modality. We develop two deep models performing reconstruction of a high-resolution image of a target image modality from its low-resolution variant with the aid of a high-resolution image from a second modality. We apply the proposed models to super-resolve near-infrared images using as side information high-resolution RGB\ images. Experimental results demonstrate the superior performance of the proposed models against state-of-the-art methods including unimodal and multimodal approaches.
Twitter User Geolocation using Deep Multiview Learning
May 11, 2018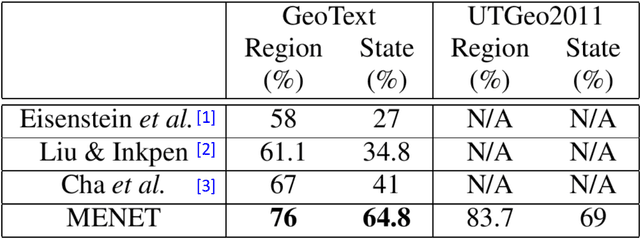
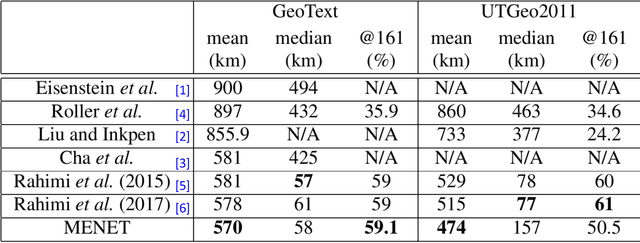
Predicting the geographical location of users on social networks like Twitter is an active research topic with plenty of methods proposed so far. Most of the existing work follows either a content-based or a network-based approach. The former is based on user-generated content while the latter exploits the structure of the network of users. In this paper, we propose a more generic approach, which incorporates not only both content-based and network-based features, but also other available information into a unified model. Our approach, named Multi-Entry Neural Network (MENET), leverages the latest advances in deep learning and multiview learning. A realization of MENET with textual, network and metadata features results in an effective method for Twitter user geolocation, achieving the state of the art on two well-known datasets.
Multiview Deep Learning for Predicting Twitter Users' Location
Dec 21, 2017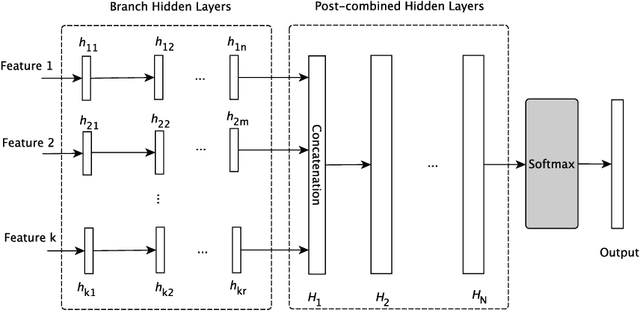

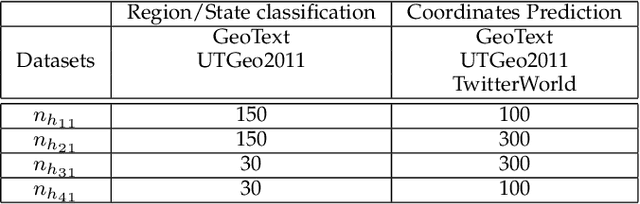
The problem of predicting the location of users on large social networks like Twitter has emerged from real-life applications such as social unrest detection and online marketing. Twitter user geolocation is a difficult and active research topic with a vast literature. Most of the proposed methods follow either a content-based or a network-based approach. The former exploits user-generated content while the latter utilizes the connection or interaction between Twitter users. In this paper, we introduce a novel method combining the strength of both approaches. Concretely, we propose a multi-entry neural network architecture named MENET leveraging the advances in deep learning and multiview learning. The generalizability of MENET enables the integration of multiple data representations. In the context of Twitter user geolocation, we realize MENET with textual, network, and metadata features. Considering the natural distribution of Twitter users across the concerned geographical area, we subdivide the surface of the earth into multi-scale cells and train MENET with the labels of the cells. We show that our method outperforms the state of the art by a large margin on three benchmark datasets.
Multi-modal dictionary learning for image separation with application in art investigation
Jul 14, 2016
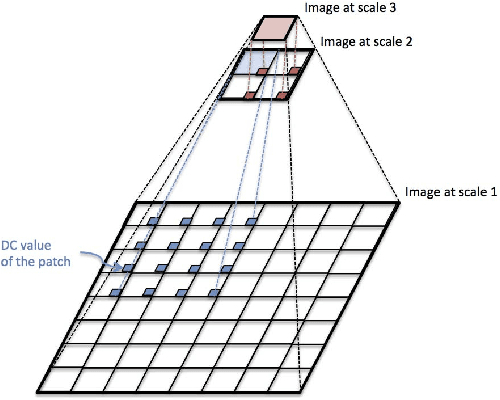


In support of art investigation, we propose a new source separation method that unmixes a single X-ray scan acquired from double-sided paintings. In this problem, the X-ray signals to be separated have similar morphological characteristics, which brings previous source separation methods to their limits. Our solution is to use photographs taken from the front and back-side of the panel to drive the separation process. The crux of our approach relies on the coupling of the two imaging modalities (photographs and X-rays) using a novel coupled dictionary learning framework able to capture both common and disparate features across the modalities using parsimonious representations; the common component models features shared by the multi-modal images, whereas the innovation component captures modality-specific information. As such, our model enables the formulation of appropriately regularized convex optimization procedures that lead to the accurate separation of the X-rays. Our dictionary learning framework can be tailored both to a single- and a multi-scale framework, with the latter leading to a significant performance improvement. Moreover, to improve further on the visual quality of the separated images, we propose to train coupled dictionaries that ignore certain parts of the painting corresponding to craquelure. Experimentation on synthetic and real data - taken from digital acquisition of the Ghent Altarpiece (1432) - confirms the superiority of our method against the state-of-the-art morphological component analysis technique that uses either fixed or trained dictionaries to perform image separation.
X-ray image separation via coupled dictionary learning
May 20, 2016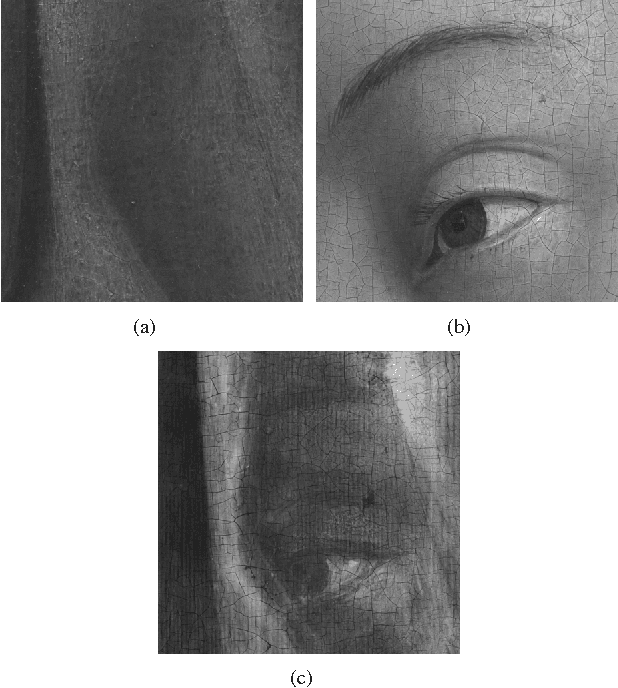
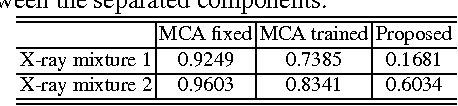
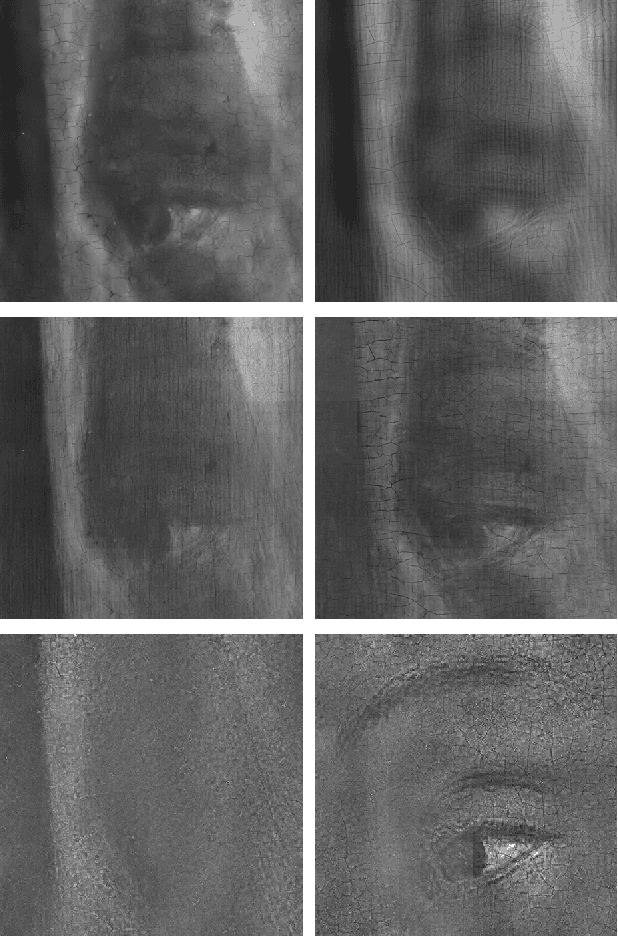
In support of art investigation, we propose a new source sepa- ration method that unmixes a single X-ray scan acquired from double-sided paintings. Unlike prior source separation meth- ods, which are based on statistical or structural incoherence of the sources, we use visual images taken from the front- and back-side of the panel to drive the separation process. The coupling of the two imaging modalities is achieved via a new multi-scale dictionary learning method. Experimental results demonstrate that our method succeeds in the discrimination of the sources, while state-of-the-art methods fail to do so.